前回のおさらい:フォルダの確認・作成
前回までに温度・湿度ロガーのデータを分析するため、フォルダを確認・作成(再作成)するプログラムを作成しました。
今回はとうとう温度・湿度ロガーIBS-TH1 PLUSのデータを読み込んでいきましょう。
ということでまずは前回のおさらい。
前回はここまでプログラムを作成しました。
import os
import shutil
def dir_check(dirname, dirlist):
if dirname not in dirlist:
os.mkdir(dirname)
elif dirname in dirlist:
shutil.rmtree(dirname)
os.mkdir(dirname)
path = os.getcwd()
# print(path)
dirnames = []
for f in os.listdir(path):
if os.path.isdir(f) == True:
dirnames.append(f)
# print(dirnames)
dir_check("Data", dirnames)
dir_check("Graph", dirnames)私はAnacondaのJupyter Notebookを使っていますが、前回はこのプログラムを一つのセルに書いていました。
今回は次のセルを使っていきます。

ファイルの確認と移動
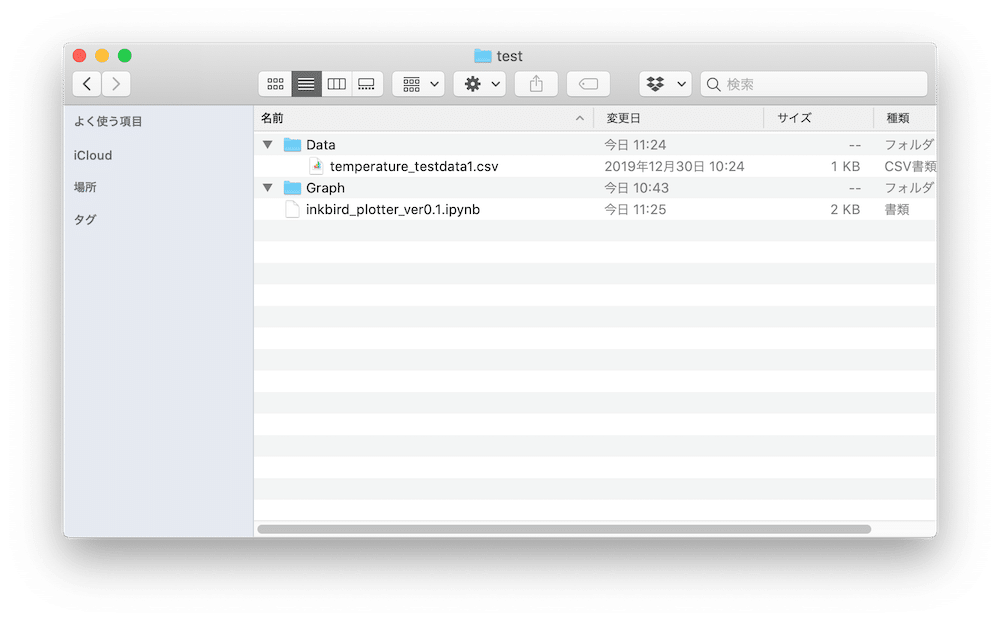
まずはファイルの存在を確認し、Dataフォルダ内に移動させましょう。
今回、移動させたいファイルは「temperature_testdata1.csv」です。
今後もこのような「CSVファイル」がIBS-TH1 PLUSから得られるので、CSVファイルかどうかを確認するというのが第一段階になります。
そしてCSVファイルをDataフォルダ内に移動させます。
ファイルを移動させるにはshutil.move(元のファイルパス, 移動先のファイルパス)を使います。
そのうちにshutilモジュールに関してもまとめていくので、しばしお時間ください。
ということでプログラムとしてはこんな感じになります。
import os
import shutil
import csv
path = os.getcwd()
data_path = path + "//Data//"
for f in os.listdir(path):
if f[-4:] == ".csv":
shutil.move(f, data_path + f)今後、Dataフォルダは何度も使うので、絶対パスを「data_path = path + “//Data//”」とすることで、data_pathにまとめておきます。
os.listdir(パス)でファイルの現在のフォルダ内のリストを取得し、for文で順次変数fに挿入していきます。
f[-4:]はfのファイル名の後ろから4文字を取得します。
そしてif f[-4:] == “.csv”:でファイル名の後ろから4文字が「.csv」となる場合のみ場合分けします。
shutil.move(f, “.//Data//” + f)でDataフォルダに移動させます。
ちなみに”.//Data//”というのは、”.//”が現在のフォルダを表し、”Data//”でDataフォルダ内を示します。
実行してみると「temperature_testdata1.csv」が「Dataフォルダ」内に移動することができました。
ファイルの読み込み
次にファイルを読み込んでいきます。
今後、同じようなファイルが増えていくことを考えると、for文を使ってファイルを順番に読んでいくプログラムにしておいた方が無難でしょう。
CSVファイルを読み込むにはcsvモジュールを使います。

import os
import shutil
import csv
path = os.getcwd()
data_path = path + "//Data//"
for f in os.listdir(path):
if f[-4:] == ".csv":
shutil.move(f, data_path + f)
for f in os.listdir(data_path):
if f[-4:] == ".csv":
file = open(data_path + f, "r")
reader = csv.reader(file)
for row in reader:
print(row)
file.close()
実行結果
['Time', 'Temperature_C', 'Relative_Humidity']
['2019-12-29 18:53:36', '26.59', '22.12']
['2019-12-29 19:23:36', '25.37', '23.46']
['2019-12-29 19:53:36', '24.15', '24.79']
['2019-12-29 20:23:36', '22.93', '26.13']
['2019-12-29 20:53:36', '21.71', '27.46']
['2019-12-29 21:23:36', '20.48', '28.8']
(以下省略)ファイルを開いた際は、ファイル名.close()でファイルを閉じるのを忘れないでください。
データが長いので出力結果を省略していますが、とりあえずデータを読み込むことができました。
一番最初の行はヘッダーになっていて、’Time’, ‘Temperature_C’, ‘Relative_Humidity’の三つの列があることが分かります。
二行目からは’2019-12-29 18:53:36′, ‘26.59’, ‘22.12’となっています。
最初の数字がヘッダーでいう’Time’であり、データの日時を示しています。
二つ目、三つ目の数字が’Temperature_C’:温度と、’Relative_Humidity’:湿度に対応しています。
ここで問題点は二つ。
最初のヘッダーの行も、データの行と同じように取得してしまっていること。
全ての値が文字型(str型)となっていること。
ということで次回はヘッダーの行とデータの行の場合分けをしていきます。

ということで今回はこんな感じで。
コメント