前回のおさらい:CSVファイルの読み込み
前回は温度・湿度ロガーのデータを分析するため、CSVファイルを読み込む部分のプログラムを作成しました。
まずはとりあえず前回のコードを見てみます。
import os
import shutil
import csv
path = os.getcwd()
data_path = path + "//Data//"
for f in os.listdir(path):
if f[-4:] == ".csv":
shutil.move(f, data_path + f)
for f in os.listdir(data_path):
if f[-4:] == ".csv":
file = open(data_path + f, "r")
reader = csv.reader(file)
for row in reader:
print(row)
実行結果
['Time', 'Temperature_C', 'Relative_Humidity']
['2019-12-29 18:53:36', '26.59', '22.12']
['2019-12-29 19:23:36', '25.37', '23.46']
['2019-12-29 19:53:36', '24.15', '24.79']
['2019-12-29 20:23:36', '22.93', '26.13']
['2019-12-29 20:53:36', '21.71', '27.46']
['2019-12-29 21:23:36', '20.48', '28.8']
(以下省略)ここでの問題点はヘッダーとデータが同じように取得されてしまっていることと、日時のデータと温度・湿度のデータが文字(str)となってしまっていることです。
ということで今回はヘッダーとデータの行を分けるプログラムを作成していきます。
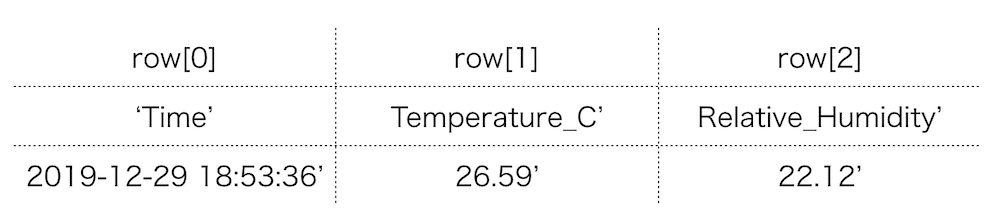
それぞれの値を別々に取得
先ほどの実行結果ではprint(row)とすることでデータを一括で表示していました。
そこでまずはそれぞれの値を別々に取得してみます。
rowは現在、リストとなっているので、row[0]とすると最初の値が、row[1]とすると2番目の値、row[2] とすると3番目の値を取得することができます。
import os
import shutil
import csv
path = os.getcwd()
data_path = path + "//Data//"
for f in os.listdir(path):
if f[-4:] == ".csv":
shutil.move(f, data_path + f)
for f in os.listdir(data_path):
if f[-4:] == ".csv":
file = open(data_path + f, "r")
reader = csv.reader(file)
for row in reader:
print(row[0], row[1], row[2])
実行結果
Time Temperature_C Relative_Humidity
2019-12-29 18:53:36 26.59 22.12
2019-12-29 19:23:36 25.37 23.46
2019-12-29 19:53:36 24.15 24.79
2019-12-29 20:23:36 22.93 26.13
2019-12-29 20:53:36 21.71 27.46
(以下省略)ヘッダーの場合分け
先ほどの実行結果をみると最初の行はヘッダー、二行目からデータとなっています。
とりあえずここを場合分けします。
どう場合分けするかというと、最初の行ヘッダーは3つとも文字、二行目以降は日時、小数、小数となっています。(ただし現状では全てstr型)
ということで2つ目、3つ目の値が、str型(文字)から小数であるfloat型に変換できれば、その行はデータの行だと分かります。
逆に変換できなかった場合はヘッダーということです。
ここで使うのは、例外処理であるtry – except文です。

要するにfloat型に変換してみて、出来たなら「True」、できなかったら「False」という値を返す関数を作り、2つ目、3つ目の数値で「True」が返ってくる行を取得するというわけです。
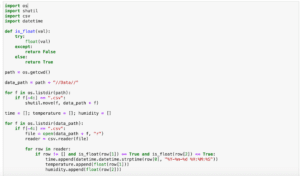
そのfloat型に変換できるか判定する関数はこんな感じです。
def is_float(val):
try:
float(val)
except:
return False
else:
return Trueこれを先ほどのプログラムに組み込んで、ちゃんと判定ができているか確認します。
import os
import shutil
import csv
def is_float(val):
try:
float(val)
except:
return False
else:
return True
path = os.getcwd()
data_path = path + "//Data//"
for f in os.listdir(path):
if f[-4:] == ".csv":
shutil.move(f, data_path + f)
for f in os.listdir(data_path):
if f[-4:] == ".csv":
file = open(data_path + f, "r")
reader = csv.reader(file)
for row in reader:
print(is_float(row[0]), is_float(row[1]),is_float(row[2]))
実行結果
False False False
False True True
False True True
False True True
False True True
False True True
(以下省略)とりあえず2つ目(row[1])、3つ目(row[2])の値だけでなく、最初の値(row[0])も確認してみました。
最初の行はすべて文字なので「False」、つまりfloat型に変換できないということで予想通りです。
二行目からは最初の値(row[0])は日時のためfloat型に変換できない(False)、しかし2つ目(row[1])、3つ目(row[2])の値はfloat型に変換できる(True)ということでこちらも予想通りです。
ということでこの関数とif文を使って、データの行だけ場合分けします。
import os
import shutil
import csv
def is_float(val):
try:
float(val)
except:
return False
else:
return True
path = os.getcwd()
data_path = path + "//Data//"
for f in os.listdir(path):
if f[-4:] == ".csv":
shutil.move(f, data_path + f)
for f in os.listdir(data_path):
if f[-4:] == ".csv":
file = open(data_path + f, "r")
reader = csv.reader(file)
for row in reader:
if row != [] and is_float(row[1]) == True and is_float(row[2]) == True:
print(row)
出力結果
['2019-12-29 18:53:36', '26.59', '22.12']
['2019-12-29 19:23:36', '25.37', '23.46']
['2019-12-29 19:53:36', '24.15', '24.79']
['2019-12-29 20:23:36', '22.93', '26.13']
['2019-12-29 20:53:36', '21.71', '27.46']
(以下省略)今回はヘッダー行が表示されませんでした。
ということで正しくデータの行を取得できていることでしょう。
ちなみにif文をちょっと解説しておきましょう。
if row != [] and is_float(row[1]) == True and is_float(row[2]) == True:最初の row != [] は、その行が空白行でない(!= は notの意味)ことを示しています。
そして is_float(row[1]) == True と is_float(row[2]) == True で2つ目と3つ目の値が小数であることを示しています。
全て「and」で繋がっているので、空白行ではなく、row[1]とrow[2]が小数である場合のみが場合分けされます。
これでデータが取得することができました。
次回はもう一つの問題である「値が全てstr型になっている」に対処していきましょう。
ということで今回はこんな感じで。
コメント