Python基礎– tag –
-
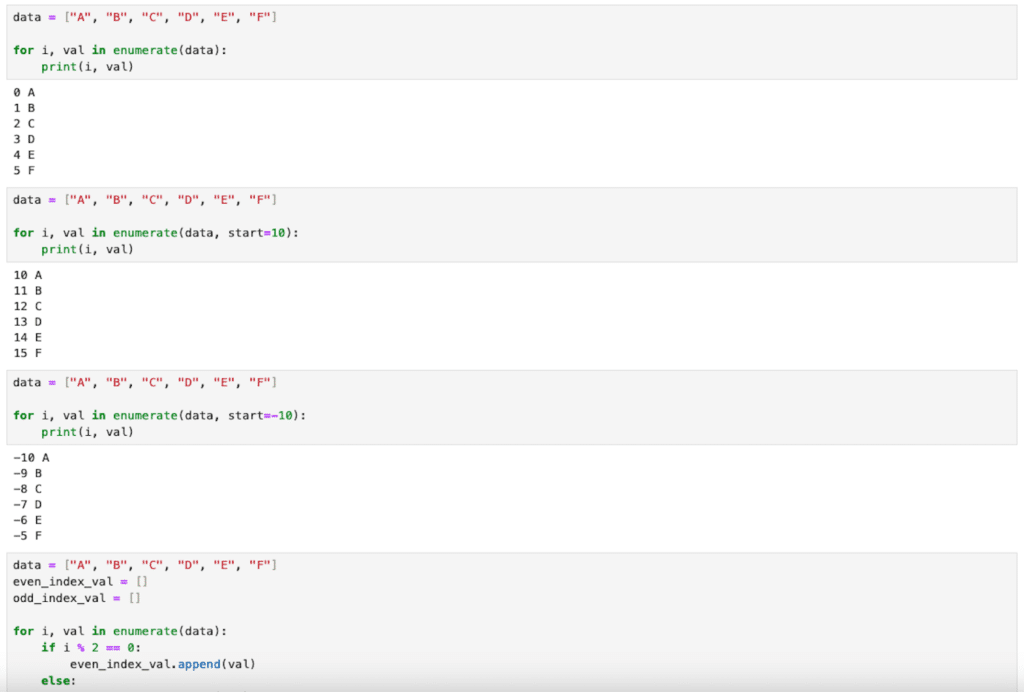
【Python基礎】enumerate関数の変わった使い方(開始値指定、奇数・偶数インデックスに分割、インデックスをキーとする辞書を作成)
enumerate 前回、itertoolsの文字列のイテレータであるchain、compress、islice、pairwise、zip_longestを紹介しました。 今回はenumerate関数の変わった使い方として開始値指定したり、奇数・偶数インデックスに分割したり、インデックスをキーとする辞書... -
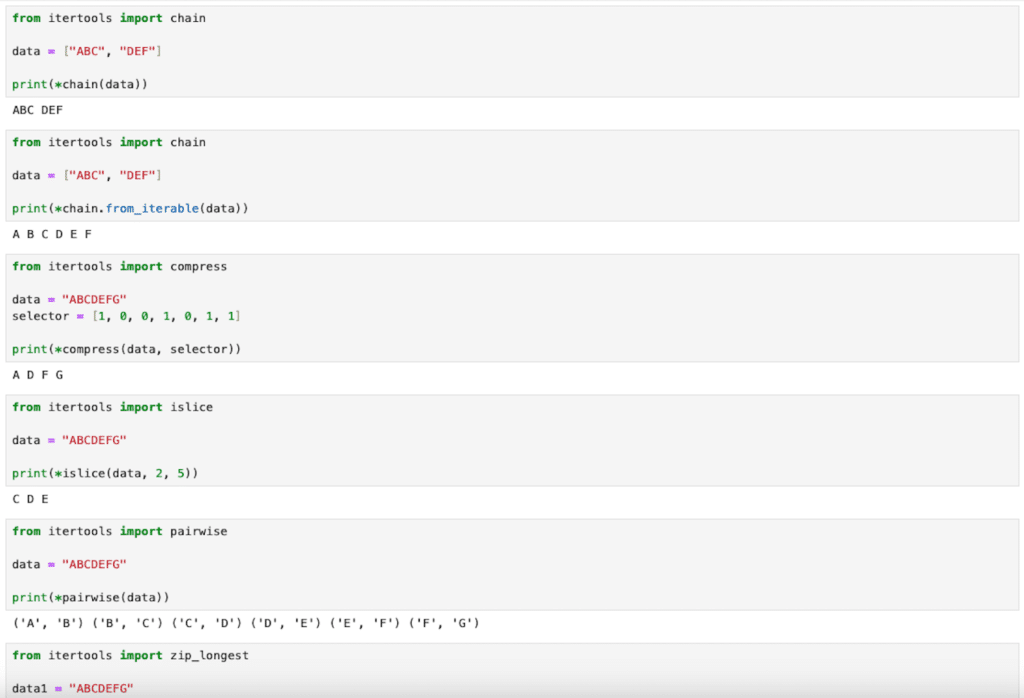
【itertools】文字列のイテレータであるchain、compress、islice、pairwise、zip_longest[Python]
itertools 前回、itertoolsでリストの値の累積和や他の累積計算値を取得する関数accumulateを紹介しました。 今回はitertoolsの中の文字列のイテレータであるchain、compress、islice、pairwise、zip_longestを紹介します。 ちなみにイテレータなのでアン... -
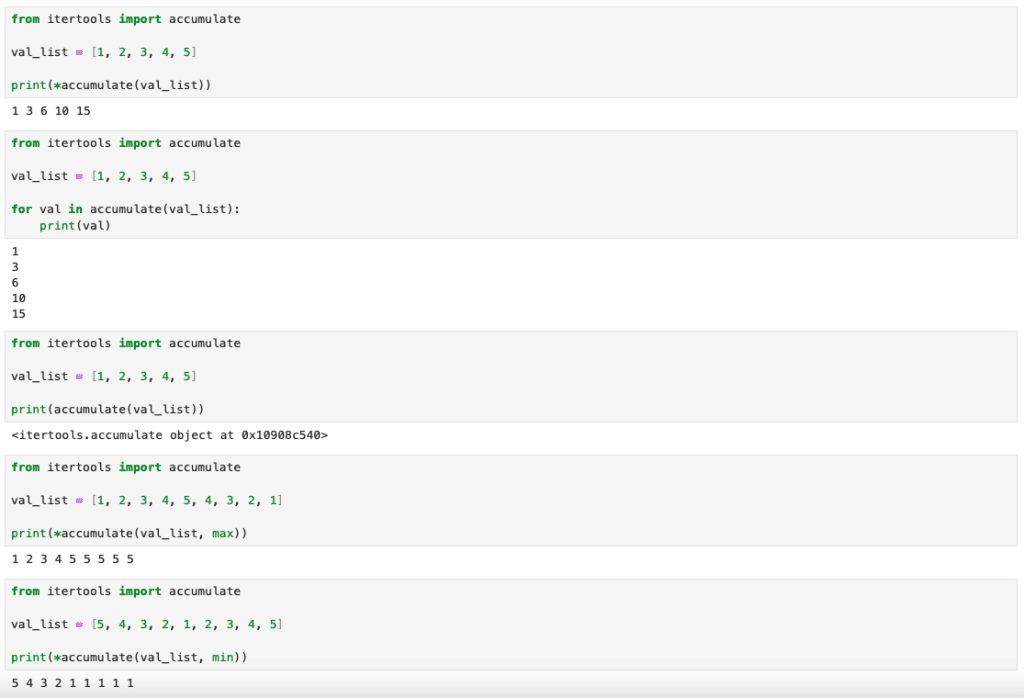
【itertools】リストの値の累積和や他の累積計算値を取得する関数accumulate[Python]
functools 前回、functoolsで特定の関数の一部の引数を固定した新しい関数を作る方法(functools.partial)を紹介しました。 今回はitertoolsでリストの値の累積和や他の累積計算値を取得する関数accumulateを紹介します。 それでは始めていきましょう。 a... -
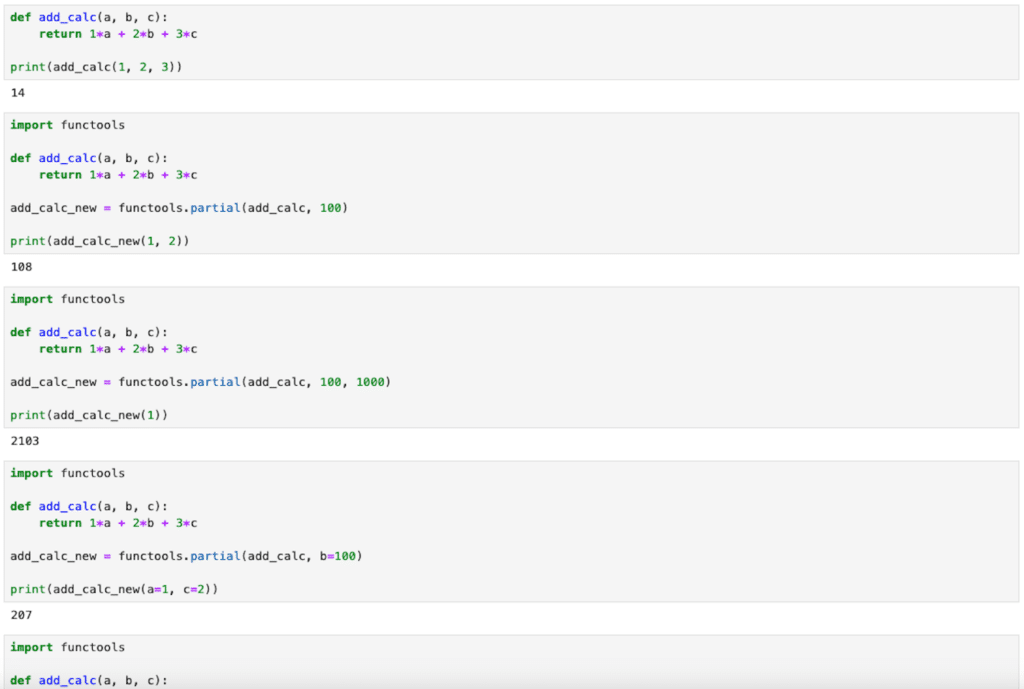
【functools】特定の関数の一部の引数を固定した新しい関数を作る方法(functools.partial)[Python]
functools 前回、itertoolsの無限イテレータcount、cycle、repeatを紹介しました。 今回はfunctoolsのpartialを使って特定の関数の一部の引数を固定した新しい関数を作る方法を紹介します。 関数の一部の引数を固定するということなので、基本となる関数を... -
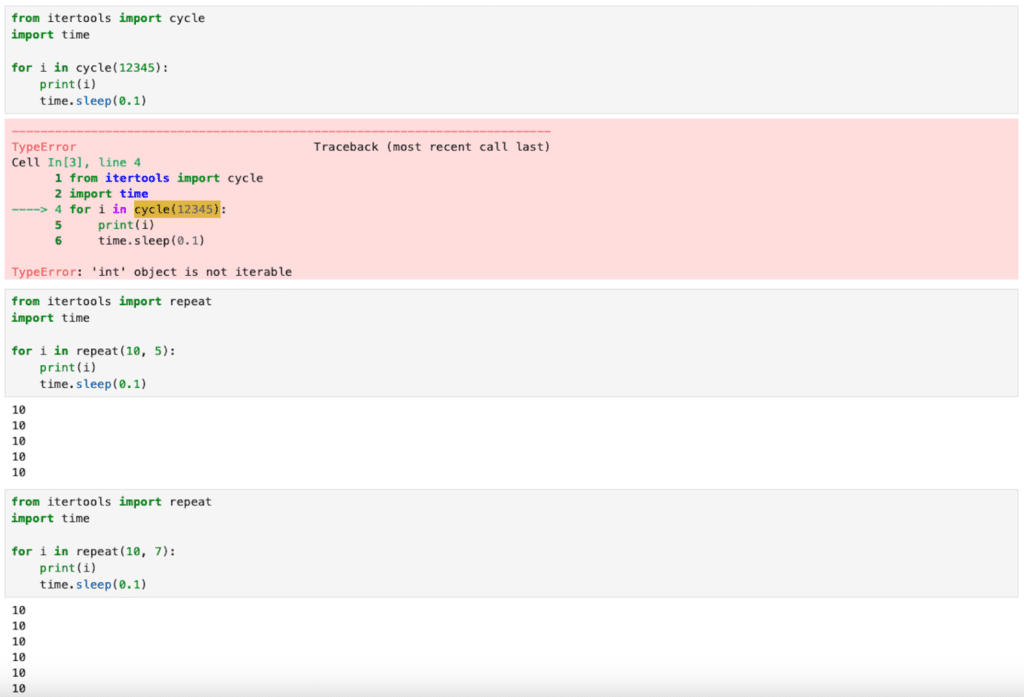
【itertools】無限イテレータcount、cycle、repeat[Python]
itertools 前回、functoolsのreduce関数を使ってリスト内の全要素の計算値を取得する方法を紹介しました。 今回はitertoolsの無限イテレータcount、cycle、repeatを紹介します。 どれも普通に使ってしまうとものすごい速さでカウントしていくので、今回はt... -
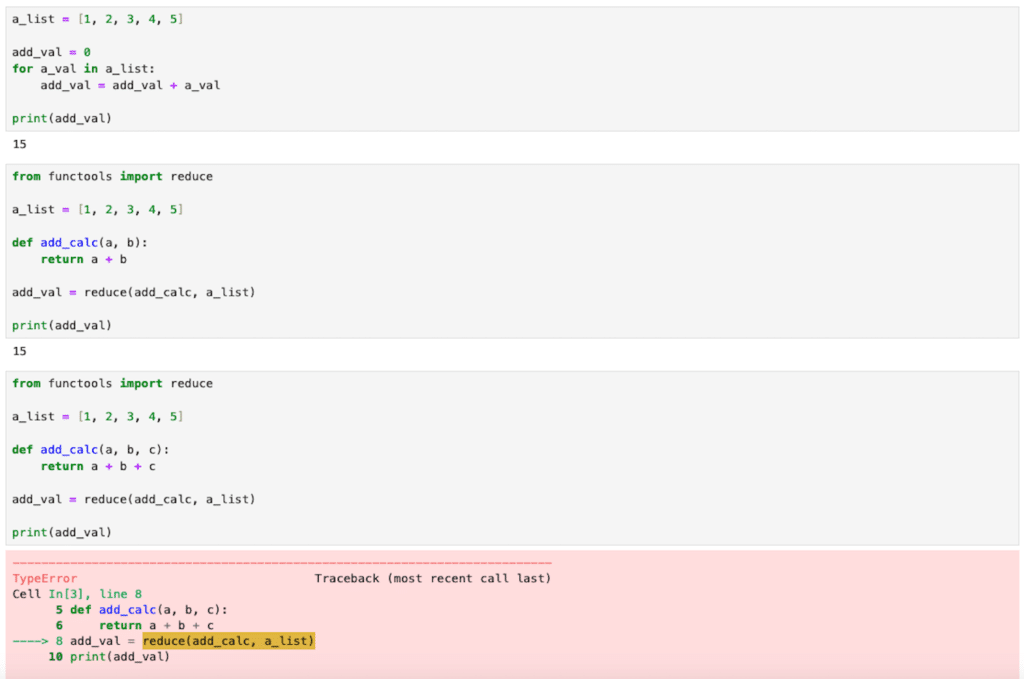
【functools】reduce関数を使ってリスト内の全要素の計算値を取得する方法[Python]
functools 前回、自作関数を使ってリストや辞書から条件を満たす要素を抽出するfilter関数を紹介しました。 今回はfunctoolsのreduce関数を使ってリスト内の全要素の計算値を取得する方法を紹介します。 ここでいう計算値というのは全要素を足し算したり、... -
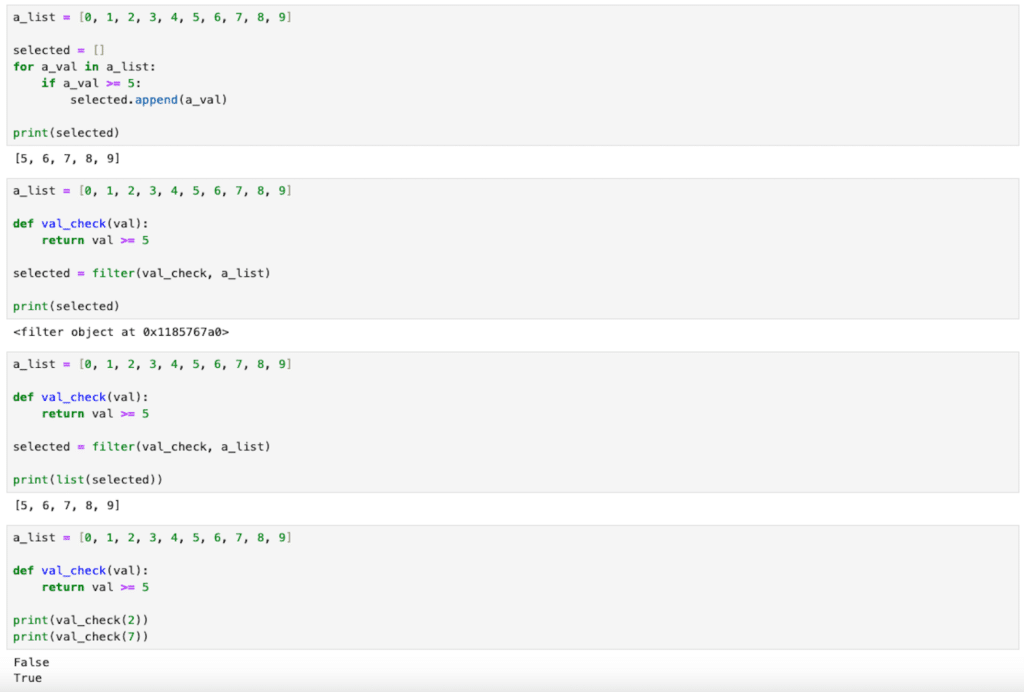
【Python基礎】自作関数を使ってリストや辞書から条件を満たす要素を抽出するfilter関数
filter関数 前回、Pandasでisinと==を使って特定の値の要素を抽出する方法を紹介しました。 今回は自作関数を使ってリストや辞書から条件を満たす要素を抽出するfilter関数を紹介します。 例えば0から9までの数値のリストから5以上のものを新たなリストと... -
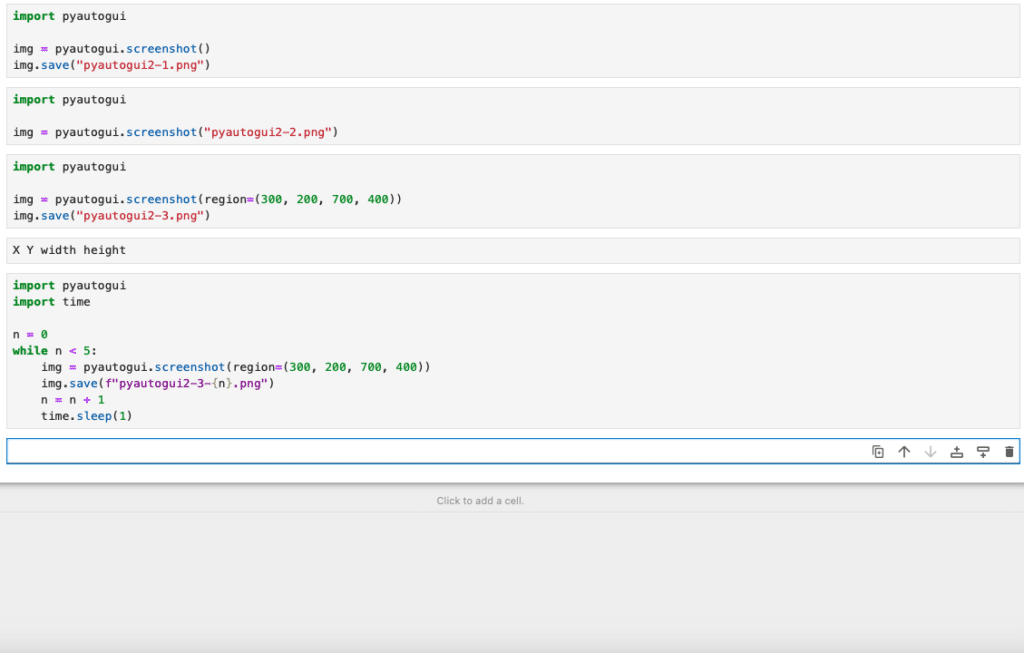
【Python基礎】PyAutoGUIで自動でスクリーンショットを撮影する方法
PyAutoGUI 前回は、SciPyやPandasを使ってグラフの歪度(左右非対称具合)と尖度(尖り具合)を取得する方法を紹介を紹介しました。 今回はPyAutoGUIを使って自動でスクリーンショットを撮影する方法を紹介します。 それでは始めていきましょう。 スクリー... -
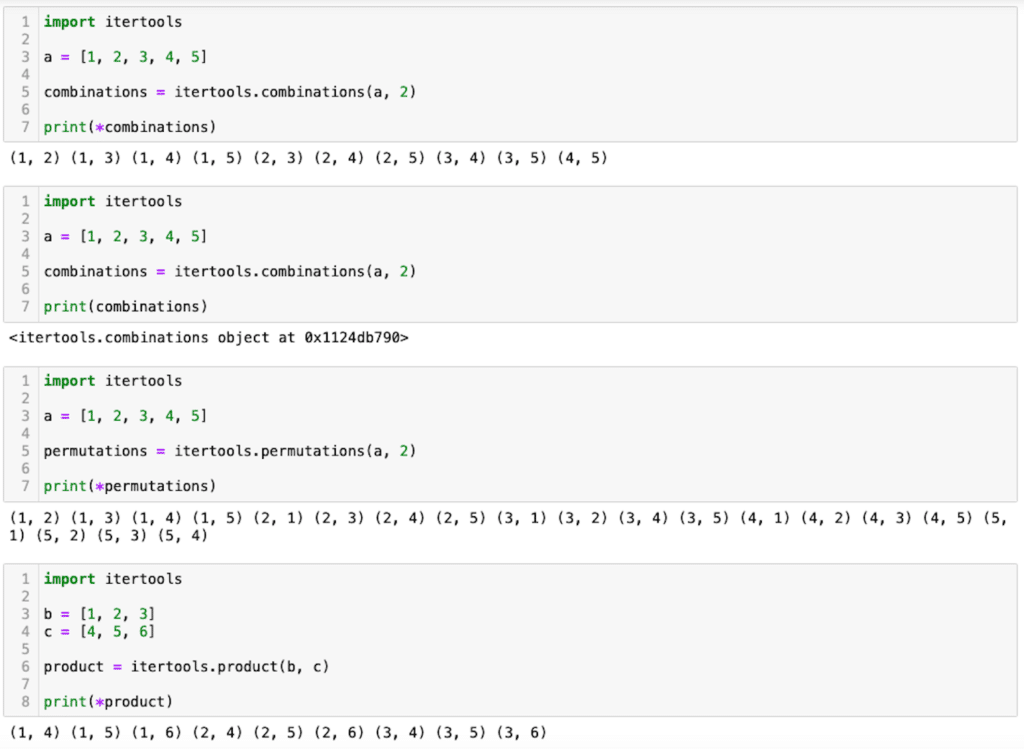
【Python基礎】itertoolsを使った組み合わせ、順列、そして複数のリストの要素の総組み合わせの作成方法
itertools 前回、例外処理try...exceptで強制的に例外を発生させるraiseの使い方を紹介しました。 今回はPythonでitertoolsを使った組み合わせ、順列、そして複数のリストの要素の総組み合わせの作成方法を紹介します。 それでは始めていきましょう。 組み... -
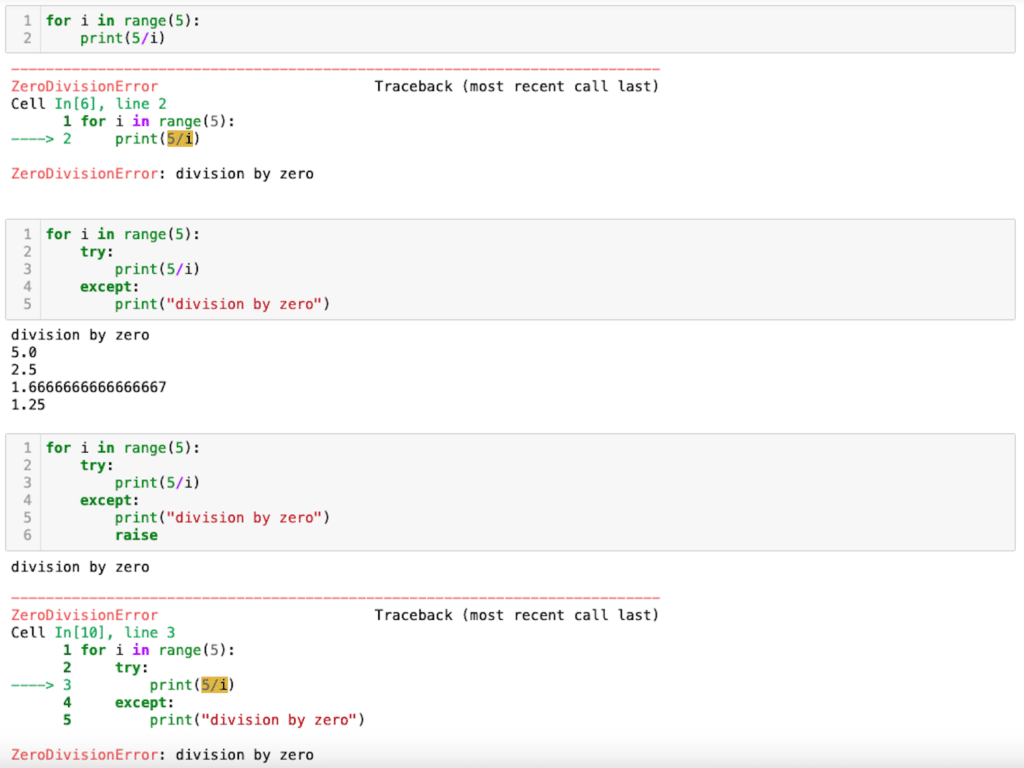
【Python基礎】例外処理try…exceptで強制的に例外を発生させるraiseの使い方
例外処理 前回、Pythonの列挙型enumの使い方を紹介しました。 今回は例外処理try...except文で強制的に例外を発生させるraiseの使い方を紹介します。 それでは始めていきましょう。 raise 例えばこんなプログラムがあったとします。 for i in range(5): pr...