ファイルの書き込みの比較
今回は何となく思ったことを試していくコーナーとして、ファイルの書き込みの際、いつファイルを閉じたらいいかを検証していきます。
どういうことかと言うと、例えばこんな感じのデータ。
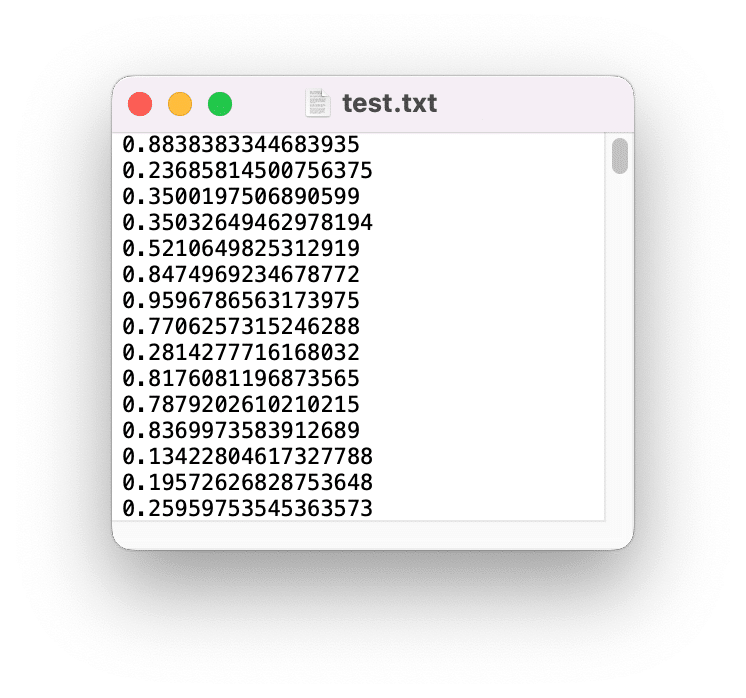
1行ずつ数値データが書き込まれています。
このファイルを生成する際、ファイルをどのように開き、そして閉じたら処理が短くて済むかということを検証したいと思ったわけです。
プログラムで書いてみるとまずはこれのように「ファイルを開いて、データを全て書き込んでから閉じる」タイプ。
with open(filepath, 'w') as f_out:
for _ in range(cycles):
f_out.write(f'{random.random()}\n')もしくはこんな感じで、「開いて1行書いて閉じるを繰り返す」タイプ。
for _ in range(cycles):
with open(filepath, 'a') as f_out:
f_out.write(f'{random.random()}\n')まず間違いなく「ファイルを開いて、データを全て書き込んでから閉じる」タイプの方が処理時間は速いことでしょう。
でもまず間違いなく「ファイルを開いて、データを全て書き込んでから閉じる」タイプは途中で処理が中断されると、そこまでの処理は保存されず、破棄されてしまうのではないでしょうか?
その場合、「開いて1行書いて閉じるを繰り返す」タイプでは毎行保存をしているようなものなので、処理の中断に強いのではないでしょうか?
そこらへんの疑問が浮かんできたので、とりあえず試してみることにしました。
検討用のプログラム全体
まずは検討のプログラム全体をお見せします。
import random
import os
import psutil
import datetime
cycles = 1000000
default_dirpath = os.getcwd()
time_start = datetime.datetime.now()
time_start_str = time_start.strftime('%Y%m%d%H%M%S')
os.mkdir(time_start_str)
output_dirpath = os.path.join(default_dirpath, time_start_str)
memorylog_filename = 'memory.log'
memorylog_filepath = os.path.join(output_dirpath, memorylog_filename)
test_filename = 'test.txt'
text_filepath = os.path.join(output_dirpath, test_filename)
mem = psutil.virtual_memory()
used_start = mem.used
def filewrite1(text_filepath, memory_filepath, time_start):
with open(text_filepath, 'w') as f_out:
for _ in range(cycles):
f_out.write(f'{random.random()}\n')
memorySave(memorylog_filepath, time_start)
def filewrite2(text_filepath, memory_filepath, time_start):
for _ in range(cycles):
with open(text_filepath, 'a') as f_out:
f_out.write(f'{random.random()}\n')
memorySave(memorylog_filepath, time_start)
def memorySave(memorylog_filepath, time_start):
time_now = datetime.datetime.now()
timedelta = time_now - time_start
mem_now = psutil.virtual_memory()
used_now = mem_now.used
used_delta = used_now - used_start
with open(memorylog_filepath, 'a') as mem_out:
mem_out.write(f'{timedelta},{used_delta}\n')
if __name__ == '__main__':
filewrite1(text_filepath, memorylog_filepath, time_start)
# filewrite2(text_filepath, memorylog_filepath, time_start)上の方から順に解説していきましょう。
ライブラリの読み込み&設定部分
まずはライブラリの読み込みと設定の部分です。
import random
import os
import psutil
import datetime
cycles = 1000000
default_dirpath = os.getcwd()
time_start = datetime.datetime.now()
time_start_str = time_start.strftime('%Y%m%d%H%M%S')
os.mkdir(time_start_str)
output_dirpath = os.path.join(default_dirpath, time_start_str)
memorylog_filename = 'memory.log'
memorylog_filepath = os.path.join(output_dirpath, memorylog_filename)
test_filename = 'test.txt'
text_filepath = os.path.join(output_dirpath, test_filename)
mem = psutil.virtual_memory()
used_start = mem.used今回使用しているライブラリは「os」、「random」、「psutil」、「datetime」の4つです。
psutilはメモリやCPUの使用量を取得するライブラリで、こちらで解説していますので、よかったらどうぞ。
「cycles = 1000000」は繰り返しの回数ですので、PCの性能に合わせて増減してください。
そしてプログラムを実行したフォルダをデフォルトのフォルダとして設定(default_dirpath = os.getcwd())しています。
また日時を取得し、結果を保存するフォルダ名を開始日時としてフォルダを作成し、出力用のフォルダとして設定しています。
time_start = datetime.datetime.now()
time_start_str = time_start.strftime('%Y%m%d%H%M%S')
os.mkdir(time_start_str)
output_dirpath = os.path.join(default_dirpath, time_start_str)そしてメモリ使用量のデータを保存するファイル(memory.log)と処理を保存するファイル(test.txt)を設定しています。
memorylog_filename = 'memory.log'
memorylog_filepath = os.path.join(output_dirpath, memorylog_filename)
test_filename = 'test.txt'
text_filepath = os.path.join(output_dirpath, test_filename)最後に開始時のメモリ使用量を取得しています。
mem = psutil.virtual_memory()
used_start = mem.usedファイル書き込用関数
次はファイル書き込みの部分です。
def filewrite1(text_filepath, memory_filepath, time_start):
with open(text_filepath, 'w') as f_out:
for _ in range(cycles):
f_out.write(f'{random.random()}\n')
memorySave(memorylog_filepath, time_start)
def filewrite2(text_filepath, memory_filepath, time_start):
for _ in range(cycles):
with open(text_filepath, 'a') as f_out:
f_out.write(f'{random.random()}\n')
memorySave(memorylog_filepath, time_start)アップデートの際のミスを減らすために、一つのファイルで関数を適宜選択し、処理を変える方法を取りました。
filewrite1関数が「ファイルを開いて、データを全て書き込んでから閉じる」タイプ。
filewrite2関数が「開いて1行書いて閉じるを繰り返す」タイプ。
ファイルの書き込みに関しては先ほども解説しているので、ここでは割愛します。
ちなみに書き込むデータはrandomライブラリを使って、「random.random()」でランダムな小数を生み出し、ファイルに書き込んでいます。
filewrite1関数、filewrite2関数それぞれの最後にあるmemorySave関数は次で解説します。
memorySave関数
filewrite1関数でもfilewrite2関数でも1行処理したら、その時点でのメモリ使用量を取得し、ファイルに書き込むようにしました。
def memorySave(memorylog_filepath, time_start):
time_now = datetime.datetime.now()
timedelta = time_now - time_start
mem_now = psutil.virtual_memory()
used_now = mem_now.used
used_delta = used_now - used_start
with open(memorylog_filepath, 'a') as mem_out:
mem_out.write(f'{timedelta},{used_delta}\n')datetime関数で日時を取得したのち、プログラム開始時に取得した日時と引き算をすることで、経過時間を取得しています。
time_now = datetime.datetime.now()
timedelta = time_now - time_startメモリ使用量も同様に処理毎にメモリ使用量を取得し、プログラム開始時に取得したメモリ使用量と引き算をすることでプログラム開始時からのメモリ使用量の増減を取得しています。
mem_now = psutil.virtual_memory()
used_now = mem_now.used
used_delta = used_now - used_startそして最後にメモリ使用量を記録するためのファイル「memory.log」に出力しています。
if __name__ == ‘__main__’部分
最後に実行部分である「if __name__ == ‘__main__’」部分です。
if __name__ == '__main__':
filewrite1(text_filepath, memorylog_filepath, time_start)
# filewrite2(text_filepath, memorylog_filepath, time_start)ここではfilewrite1関数とfilewrite2関数のどちらかを呼び出す(使わない方をコメントアウトする)だけです。
グラフ作成用プログラム
次は取得したメモリ使用量のデータをグラフ化するプログラムです。
import os
import matplotlib.pyplot as plt
import pandas as pd
default_dirpath = os.getcwd()
memorylog_filename = 'memory.log'
memorylog_filepath = os.path.join(default_dirpath, memorylog_filename)
def main():
df = pd.read_csv(memorylog_filepath, names=['Time', 'Memory'])
total_seconds_list = []
for time in df['Time']:
hour = int(time.split(':')[0])
minute = int(time.split(':')[1])
second = float(time.split(':')[2])
total_seconds = 60*60*hour + 60*minute + second
total_seconds_list.append(total_seconds)
fig = plt.figure()
plt.plot(total_seconds_list, df['Memory'])
plt.xlabel('Seconds')
plt.ylabel('Memory Used')
plt.savefig('memory.png')
if __name__ == '__main__':
main()こちらも順に解説していきましょう。
ライブラリの読み込み&設定部分
import os
import matplotlib.pyplot as plt
import pandas as pd
default_dirpath = os.getcwd()
memorylog_filename = 'memory.log'
memorylog_filepath = os.path.join(default_dirpath, memorylog_filename)こちらで使用しているライブラリは「os」、「matplotlib」、「pandas」の3つです。
またメモリ使用量を保存しているファイル「memory.log」のファイルパスの設定をしています。
ちなみにこのグラフ化プログラムは、先ほどの処理用プログラムで作成された日時のフォルダの中で使用するのを想定しています。
Main関数部分
def main():
df = pd.read_csv(memorylog_filepath, names=['Time', 'Memory'])
total_seconds_list = []
for time in df['Time']:
hour = int(time.split(':')[0])
minute = int(time.split(':')[1])
second = float(time.split(':')[2])
total_seconds = 60*60*hour + 60*minute + second
total_seconds_list.append(total_seconds)
fig = plt.figure()
plt.plot(total_seconds_list, df['Memory'])
plt.xlabel('Seconds')
plt.ylabel('Memory Used')
plt.savefig('memory.png')
if __name__ == '__main__':
main()memory.logをCSVファイルとしてPandasを使って読み込みます(df = pd.read_csv(memorylog_filepath, names=[‘Time’, ‘Memory’]))。
その際、先ほどの処理用プログラムでは列名であるヘッダー行がなかったので、ここで追加しています(names=[‘Time’, ‘Memory’])。
そして残念ながら時間に関してはPandasでは文字列として認識されているので、時、分、秒と分割した後、秒数に計算し直して、リストに格納しています。
total_seconds_list = []
for time in df['Time']:
hour = int(time.split(':')[0])
minute = int(time.split(':')[1])
second = float(time.split(':')[2])
total_seconds = 60*60*hour + 60*minute + second
total_seconds_list.append(total_seconds)ちなみに「pd.to_datetime(時間の列, format=’日時のフォーマット’)」で、その列を日時に一括変換できるようなのですが、どうしてもフォーマットに合わない行があり、今回は断念しました。
後は変換した処理時間をX軸のデータに、メモリ使用量をY軸のデータにしてMatplotlibでグラフ化しています。
fig = plt.figure()
plt.plot(total_seconds_list, df['Memory'])
plt.xlabel('Seconds')
plt.ylabel('Memory Used')
plt.savefig('memory.png')実行結果
それでは実行結果を見ていきましょう。
今回はそれぞれ3回ずつ処理してみました。
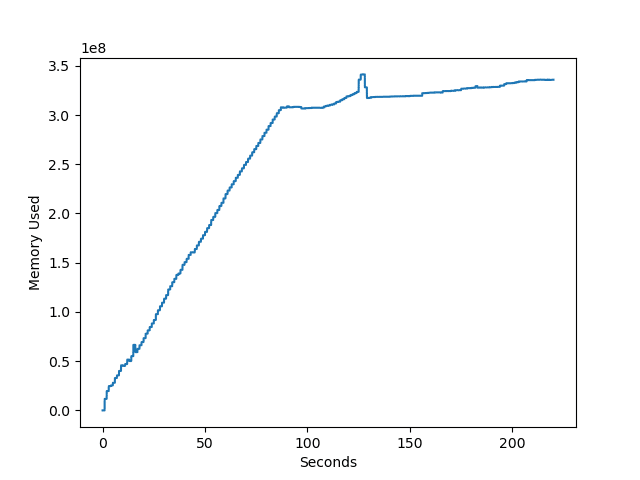
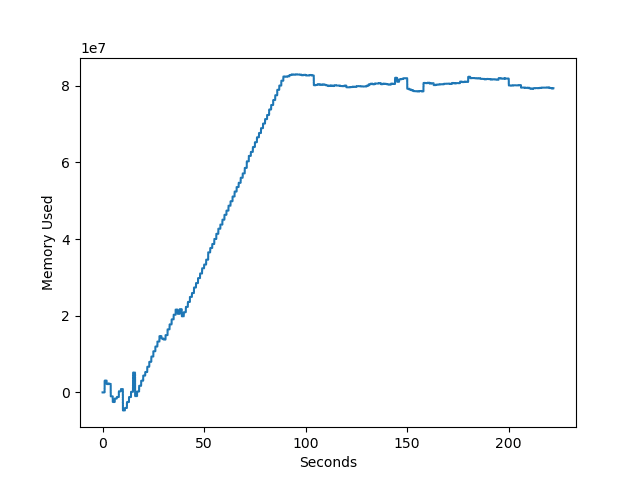
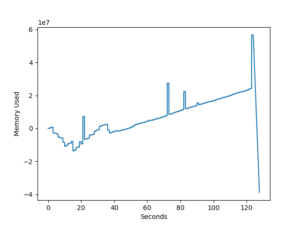
filewrite1関数:ファイルを開いて、データを全て書き込んでから閉じる
1回目。
2回目。
3回目。
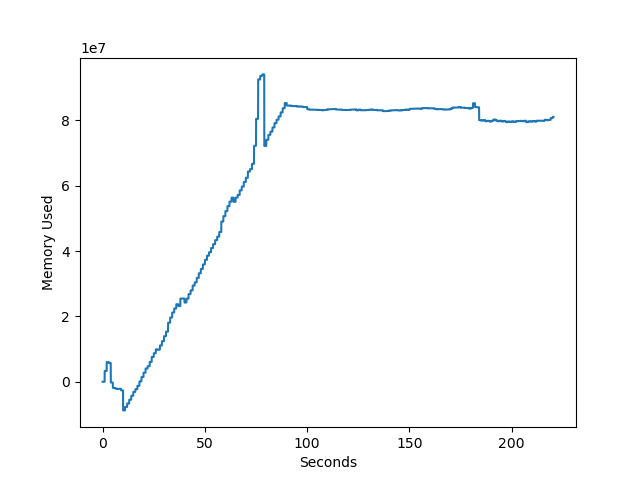
| 処理時間 | 最大メモリ使用量 | |
| 1回目 | 3分40秒 | 341 MB |
| 2回目 | 3分42秒 | 83 MB |
| 3回目 | 3分40秒 | 94 MB |
filewrite2関数:開いて1行書いて閉じるを繰り返す
1回目。
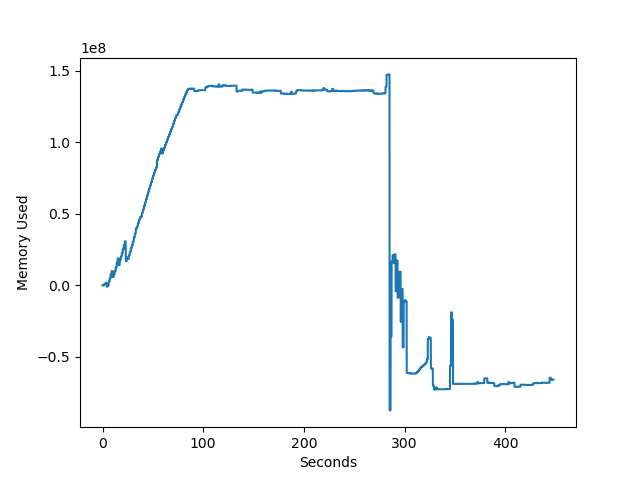
2回目。
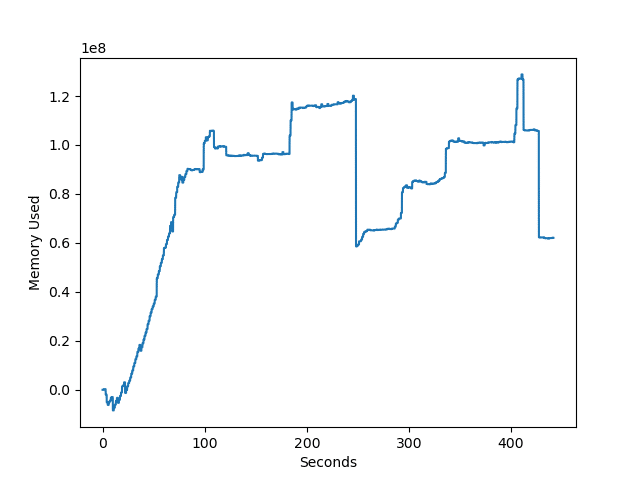
3回目。
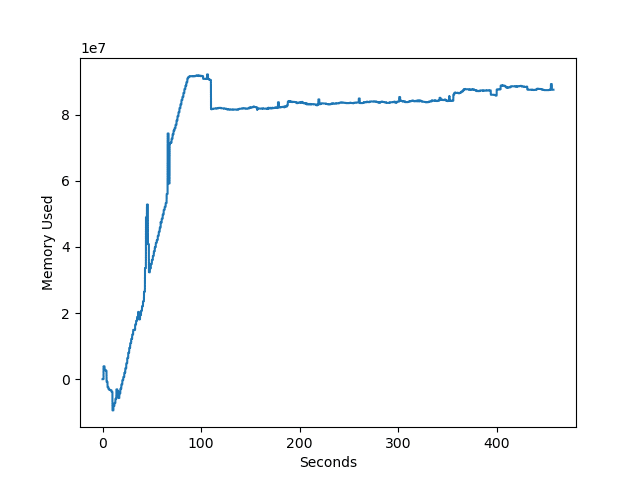
| 処理時間 | 最大メモリ使用量 | |
| 1回目 | 7分27秒 | 147MB |
| 2回目 | 7分21秒 | 129 MB |
| 3回目 | 7分37秒 | 92 MB |
予想通り「ファイルを開いて、データを全て書き込んでから閉じる」よりも「開いて1行書いて閉じるを繰り返す」の方が処理時間がかかり、だいたい倍くらいになっています。
メモリ使用量的にはそれほど大きな差異はないように見えます。
ただ「ファイルを開いて、データを全て書き込んでから閉じる」の1回目が他よりも数倍メモリを使用しており、もしかしたらPCの状態の影響を受けやすいのかもしれません。
そしてもう一つ試してみたのが、処理の途中でわざと処理を止めてみるということです。
予想としては「ファイルを開いて、データを全て書き込んでから閉じる」ではデータは保存されず、破棄されてしまうと思っていたのですが、予想に反して処理を中断したところまでのデータが書き込まれたファイルが得られました。
こうなってくると「開いて1行書いて閉じるを繰り返す」のメリットはないため、「ファイルを開いて、データを全て書き込んでから閉じる」方が断然いいように思えます。
ということで とりあえずは「ファイルを開いて、データを全て書き込んでから閉じる」ができる場合はこちらの書き方をしてみようと思います。
次回はついでに処理したデータを一度リストに格納してから、後でファイルに書き出すのと、処理したデータを即ファイルに書き込むのではどれくらい処理時間に差が出るのか試してみたいと思います。
ではでは今回はこんな感じで。
コメント