Pandas
前回、Pythonのデータ解析支援ライブラリPandasでシリーズの作成と要素の追加・削除を行いました。
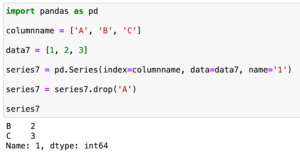
今回はデータフレームを結合させる「merge」という関数を試していきましょう。
今回は2つのデータフレームをいろいろなパターンで結合させていきますので、被った列や値をもつこのような2つのデータフレームを作成しました。
import pandas as pd
columnname1 = ['A', 'B', 'C']
columnname2 = ['B', 'C', 'D']
data1 = [['a1', 'b1', 'c1'], ['a2', 'b2', 'c2'], ['a3', 'b3', 'c3']]
data2 = [['b2', 'c2', 'd2'], ['b3', 'c3', 'd3'], ['b4', 'c4', 'd4']]
df1 = pd.DataFrame(columns=columnname1, data=data1)
df2 = pd.DataFrame(columns=columnname2, data=data2)df1
実行結果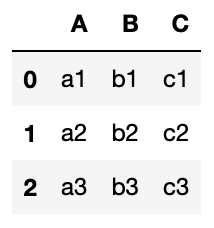
df2
実行結果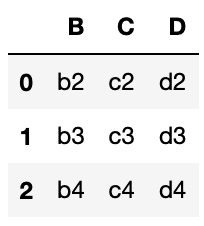
それでは始めていきましょう。
mergeの基本
まずはとりあえずmergeを使ってみます。
使い方としては「pd.merge(データフレーム1, データフレーム2)」です。
df3 = pd.merge(df1, df2)
df3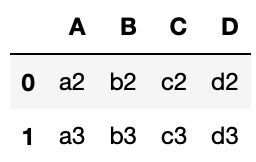
このように何もオプションをつけずにmergeをすると、2つのデータフレームで同じ列名、同じ値をもつデータフレームとなります。
mergeする列を指定:on
次に結合する列を指定してmergeしてみます。
どういうことかというと先ほどの2つのデータフレームでは「B」と「C」の列が両方に存在します。
そこでこの両方に存在する列を重ね合わせて結合するということです。
この場合は「pd.merge(データフレーム1, データフレーム2, on=[列名])」というようにonのオプションを追加します。
「B」を重ね合わせてmergeしてみましょう。
df4 = pd.merge(df1, df2, on=['B'])
df4
実行結果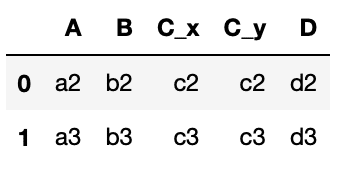
「B」の列を重ね合わせてmergeした結果、「C」の列はそれぞれのデータフレームに存在するため、それぞれのデータフレームからの「C」の列が「C_x」、「C_y」として結合されました。
ちなみにこの「on」のオプションは1つの列だけでなく、2つ以上の列を指定することもできます。
df5 = pd.merge(df1, df2, on=['B', 'C'])
df5
実行結果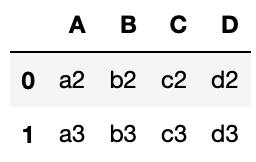
結合する方法を指定:how
結合方法としては「inner」、「left」、「right」、「outer」の4つの結合方法があります。
この結合方法とは結合後のデータフレームにどちらのデータフレームを完全に残すかということを指定しています。
「pd.merge(データフレーム1, データフレーム2])」とした場合、
| inner | データフレーム1、データフレーム2の両方に存在するもののみ残る(デフォルト) |
| left | データフレーム1は完全に残り、データフレーム2はデータフレーム1に存在するもののみ残る |
| right | データフレーム2は完全に残り、データフレーム1はデータフレーム2に存在するもののみ残る |
| outer | 両方のデータフレームが完全に残る |
という感じなのですが、なかなか文字では分かりづらいので、とりあえず試してみましょう。
inner
df6 = pd.merge(df1, df2, on=['B', 'C'], how='inner')
df6
実行結果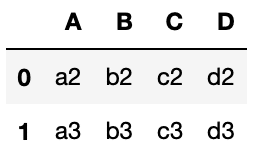
left
df7 = pd.merge(df1, df2, on=['B', 'C'], how='left')
df7
実行結果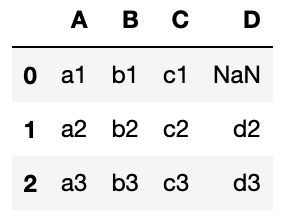
df1のデータが完全に残り、そこにdf2のデータが結合されるため、「D列の0行」がNanになっています。
right
df8 = pd.merge(df1, df2, on=['B', 'C'], how='right')
df8
実行結果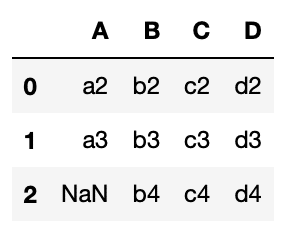
df2のデータが完全に残り、そこにdf1のデータが結合されるため、「A列の3行」がNanになっています。
outer
df9 = pd.merge(df1, df2, on=['B', 'C'], how='outer')
df9
実行結果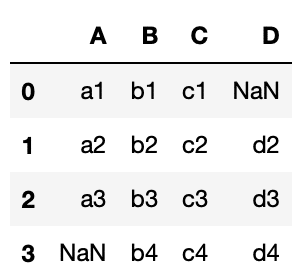
df1、df2の両方が完全に残るように結合されるため、「A列の3行」と「D列の0行」がNanになっています。
データフレームを複数使うようになると結合する場面も出てくると思うので、覚えておくといいかなと思います。
ではでは今回はこんな感じで。
コメント