リスト内全要素の型変換
前回、データフレーム間でのデータを1行や1列コピーする方法を勉強してみました。
今回はPythonのリスト内の要素の型を全て変換する方法を勉強していきます。
例えばデータベースからデータを取得した際、数値なのに全てstr型になっていたりして計算できないなんてことが多々あります。
そんなときに必要な操作になってきますので、覚えておくと便利かなと思います。
まずは今回使うデータの確認です。
こんな感じで1から5のint型の値をもつリストを作成してみました。
test1 = [1, 2, 3, 4, 5]
print(test1, type(test1))
for val in test1:
print(val, type(val))
実行結果
[1, 2, 3, 4, 5] <class 'list'>
1 <class 'int'>
2 <class 'int'>
3 <class 'int'>
4 <class 'int'>
5 <class 'int'>「type(値やオブジェクト)」は値やオブジェクト(リスト等)の型を調べる関数です。
リストを入れると「<class ‘list’>」とlist型であることが、要素を一つずつ取得して入れると「<class ‘int’>」とint型になっているのが確認できました。
それでは始めていきましょう。
よくやる間違い
まずはよくやる間違いからです(私だけ?)。
型を変換するのに、例えばint型をstr型に変換する時は「str(int型の値)」とします。
これをそのままリストにも使えるんじゃないかとこんな感じのプログラムを書いてしまうことがあります。
test1 = [1, 2, 3, 4, 5]
test1_str = str(test1)
print(test1_str, type(test1_str))
for val in test1_str:
print(val, type(val))
実行結果
[1, 2, 3, 4, 5] <class 'str'>
[ <class 'str'>
1 <class 'str'>
, <class 'str'>
<class 'str'>
2 <class 'str'>
, <class 'str'>
<class 'str'>
3 <class 'str'>
, <class 'str'>
<class 'str'>
4 <class 'str'>
, <class 'str'>
<class 'str'>
5 <class 'str'>
] <class 'str'>これだとご覧の通りlist型の出力がそのままstr型に変換されてしまいます。
for文を使って一つずつ変換
リスト内の要素の型変換の基本は一つずつ取得し、変換し、再度リストに入れるということです。
繰り返しの処理になりますので、最初に思いつくのはfor文でしょう。
for文を使って、変換するとこんな感じのプログラムになります。
test1 = [1, 2, 3, 4, 5]
test1_str = []
for val in test1:
test1_str.append(str(val))
print(test1_str, type(test1_str))
for val in test1_str:
print(val, type(val))
実行結果
['1', '2', '3', '4', '5'] <class 'list'>
1 <class 'str'>
2 <class 'str'>
3 <class 'str'>
4 <class 'str'>
5 <class 'str'>リスト内包表記を使って一つずつ変換
単純なfor文が使えるならば、リスト内包表記を使っても書き表すことができます。
その場合はこんな感じです。
test1 = [1, 2, 3, 4, 5]
test1_str = [str(val) for val in test1]
print(test1_str, type(test1_str))
for val in test1_str:
print(val, type(val))
実行結果
['1', '2', '3', '4', '5'] <class 'list'>
1 <class 'str'>
2 <class 'str'>
3 <class 'str'>
4 <class 'str'>
5 <class 'str'>numpyを使って一括変換
最後にあまり目にしたことないですが、numpyを使うと一括変換できたので紹介します。
numpyだとlist型をnp.array型に変換する際に型を指定することができます(「np.array(リスト, dtype=’変換後の型’)」)。
また「np.array(リスト)」でnp.array型にした後で「.astype(‘変換後の型’)」で一括で型を変換するということができます。
そしてさらにリスト型に戻す「.tolist()」を使うことで、リスト内の全要素の型を変換するということができます。
ということでまずは「np.array(リスト, dtype=’変換後の型’)」を使う方法から紹介します。
import numpy as np
test1 = [1, 2, 3, 4, 5]
test1_str = np.array(test1, dtype='str').tolist()
print(test1_str, type(test1_str))
for val in test1_str:
print(val, type(val))
実行結果
['1', '2', '3', '4', '5'] <class 'list'>
1 <class 'str'>
2 <class 'str'>
3 <class 'str'>
4 <class 'str'>
5 <class 'str'>次に「np.array(リスト)」でnp.array型にした後で「.astype(‘変換後の型’)」を使う方法です。
import numpy as np
test1 = [1, 2, 3, 4, 5]
test1_str = np.array(test1).astype('int').tolist()
print(test1_str, type(test1_str))
for val in test1_str:
print(val, type(val))
実行結果
[1, 2, 3, 4, 5] <class 'list'>
1 <class 'int'>
2 <class 'int'>
3 <class 'int'>
4 <class 'int'>
5 <class 'int'>処理時間が短いのはどれ?
ここまでやってふと疑問に思ったのが、どれが一番処理時間が短いのだろうかということ。
データベースを使い始めると大量のデータを処理することから、一つ一つの処理は短いに越したことはありません。
ということでどれが一番処理が速いのか計測してみました。
Jupyter notebookの場合、セルに「%%timeit」というマジックコマンドを追加すると、自動で複数回処理し、処理時間の平均値を表示してくれます。
for文を使う方法
%%timeit
test2 = range(10000000)
test2_str = []
for val in test2:
test2_str.append(str(val))
実行結果
2.96 s ± 354 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)リスト内包表記を使う方法
%%timeit
test2 = range(10000000)
test2_str = [str(val) for val in test2]
実行結果
2.92 s ± 703 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)np.array(リスト, dtype=’変換後の型’).tolist()を使う方法
%%timeit
test2 = range(10000000)
test2_str = np.array(test2, dtype='str').tolist()
実行結果
6.46 s ± 729 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)np.array(リスト).astype(‘変換後の型’).tolist()を使う方法
%%timeit
test2 = range(10000000)
test2_str = np.array(test2).astype('int').tolist()
実行結果
1.65 s ± 102 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)思ったよりも大きな違いがなかったですが、強いて言えば「np.array(リスト).astype(‘変換後の型’).tolist()」を使うのが早そうです。
リスト内包表記は速いというイメージがあったのですが、思ったほどでもなくちょっとびっくりしています。
処理回数を増やしてみる
普段からリスト内包表記は速いというイメージがあったため、これは何かおかしいんじゃないかと思い、試行回数を10倍ずつ増やしていって、処理にかかる時間を計測していきます。
そのためJupyter notebookの最初のセルにはサイクル数の変数を準備しました。
test = range(10**1)サイクル数は101(10)から107(10,000,000)まで変化させました。
そしてこれ以降は前回行った4種類の方法を別々のセルに用意し、それぞれ実行し、その処理速度を取得しました。
for文を使う方法
%%timeit
test_str = []
for val in test:
test_str.append(str(val))リスト内包表記を使う方法
%%timeit
test_str = [str(val) for val in test]np.array(リスト, dtype=’変換後の型’).tolist()を使う方法
%%timeit
import numpy as np
test_str = np.array(test, dtype='str').tolist()np.array(リスト).astype(‘変換後の型’).tolist()を使う方法
%%timeit
import numpy as np
test_str = np.array(test).astype('int').tolist()結果
試してみた結果がこちらです。
numpy1は「np.array(リスト, dtype=’変換後の型’).tolist()を使う方法」、numpy2が「np.array(リスト).astype(‘変換後の型’).tolist()を使う方法」です。
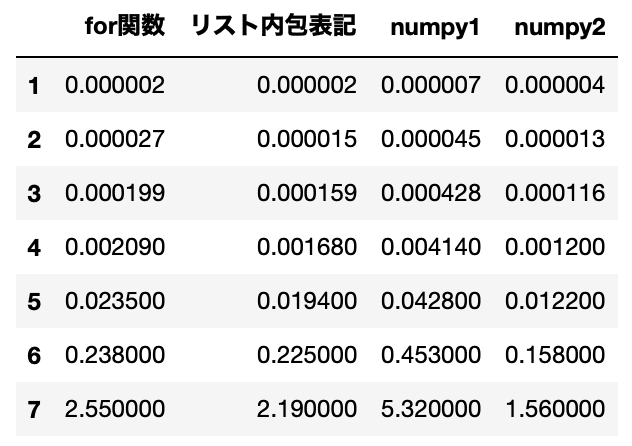
このままでは分かりにくいのでグラフ化しました。
X軸がサイクル数の乗数、Y軸が処理時間です。
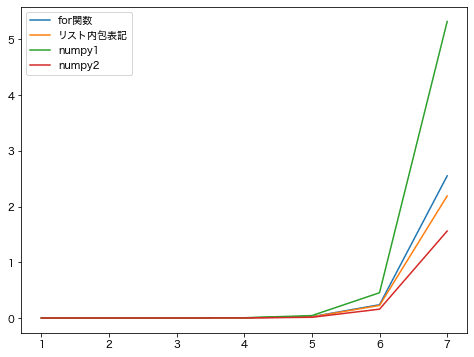
サイクル数が少ないところが分かりにくいので、Y軸を対数表示にしたものがこちら。
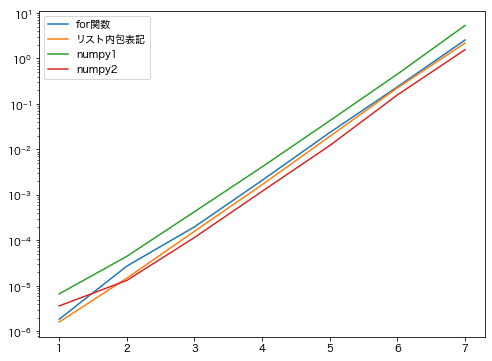
一番遅いのが「np.array(リスト, dtype=’変換後の型’).tolist()を使う方法」で一番速いのが「np.array(リスト).astype(‘変換後の型’).tolist()を使う方法」でしたが、それでも3.4倍程度の差でした。
もちろん処理が重たくなれば、その3.4倍のタイムロスは大きいのでしょうが、私みたいに普段ちょっとした処理を自動化するというPythonユーザーにとってはそれほど変わらないような気がします。
本当は何十倍も違ったり、サイクル数を増やすと他の手法と比べて格段に速くなったり、遅くなったりするといった得手不得手があると予想していたのですが、どれも同じように遅くなるという面白みのない結果となってしまいました。
まぁこういうこともあるということで今回はご勘弁ください。
次回は連番のファイル名を付ける際に便利なゼロパディング(0埋め)を勉強していきましょう。
ではでは今回はこんな感じで。
コメント