gTTS
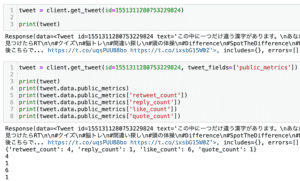
前回、weepyからTwitter API v2を使って、いいねの数、返信数、リツイートの数、引用リツイートの数を取得してみました。
今回は少し趣向を変えて、Pythonで音声読み上げをやってみます。
音声読み上げに関してはGoggle Text-to-SpeechというAPIを使いますので、使用時にインターネットへの接続が必要なことにご注意ください。
そしてそのAPIに接続するために、gTTSというPythonのライブラリを使っていきます。
なんにせよほぼ読み上げしてほしいテキストを送るだけなので、非常に簡単です。
それでは始めていきましょう。
gTTSライブラリのインストール
まずはgTTSライブラリのインストールをしていきます。
pip install gTTSgTTSの使い方の基本
まずはとりあえず使ってみます。
基本的には「gTTS(text=’読み上げたいテキスト’, lang=’言語’)」で読み上げのデータに変換できます。
そして「.save(“保存するファイルパス”)」で音声データを保存できます。
import os
from gtts import gTTS
mytext = "隣の客はよく柿食う客だ"
speech = gTTS(text=mytext, lang='ja')
speech.save("test1.mp3")
実行結果これだけのプログラムでこれほど流暢に読み上げてくれるのは正直すごいなと思いました。
音声のスピードを変えてみる
実はgTTSで変更できるオプションというのは少なく、言語と音声スピードくらいのようです。
残念ながら男性の声にしたり、イントネーションを変えたりということはできないようです。
ということで音声スピードを変えてみましょう。
音声スピードを変えるには「slow=False」、または「slow=True」のオプションを追加します。
ちなみに「slow=False」がデフォルトですので「slow=True」を試してみます。
from gtts import gTTS
mytext = "隣の客はよく柿食う客だ"
speech = gTTS(text=mytext, lang='ja', slow=True)
speech.save("test2.mp3")
実行結果少しゆっくりになりましたが、違和感があるというほどでもない気がします。
長文を試してみる
先ほどの1行であれば、それほど読み上げは難しくないのかもしれません。
ということでもう少し長めの文章を試してみました。
夏目漱石の「吾輩は猫である」の冒頭です。
from gtts import gTTS
mytext = "吾輩は猫である。名前はまだ無い。どこで生れたかとんと見当がつかぬ。\
何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。\
しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であったそうだ。\
この書生というのは時々我々を捕つかまえて煮にて食うという話である。"
speech = gTTS(text=mytext, lang='ja', slow=False)
speech.save("test3.mp3")
実行結果流暢にしゃべってはいますが、一文が長すぎて息継ぎをせずに一気に話しているという印象を受けます。
ということで適当なところで句読点を入れて、少し話す間を取るとグッと自然になります。
from gtts import gTTS
mytext = "吾輩は猫である。名前はまだ無い。どこで生れたか、とんと見当がつかぬ。\
何でも薄暗いじめじめした所で、ニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。\
しかもあとで聞くと、それは書生という人間中で一番獰悪な種族であったそうだ。\
この書生というのは、時々我々を捕つかまえて煮にて食うという話である。"
speech = gTTS(text=mytext, lang='ja', slow=False)
speech.save("test4.mp3")
実行結果英語も試してみる
日本語ばかりでなく他の言語として英語も試してみました。
先ほどまで「lang=’ja’」だった言語オプションを「lang=’en’」に変更します。
from gtts import gTTS
mytext = "My name is Mike. I have a pen which my grand father gave me a long time ago."
speech = gTTS(text=mytext, lang='en', slow=False)
speech.save("test5.mp3")
実行結果ものすごく流暢ですね。
やはり英語圏が元となっているので、完成度が段違いに感じられます。
ちなみに英語の文章で言語オプションを日本語にするとこうなります。
from gtts import gTTS
mytext = "My name is Mike. I have a pen which my grand father gave me a long time ago."
speech = gTTS(text=mytext, lang='ja', slow=False)
speech.save("test6.mp3")
実行結果英語の読み方も間違っていますし、イントネーションもほぼ合っていない感じです。
とはいえこれはこれで面白いかもしれません。
カタカナにしたらもう少しマシになるのかなと思って試してみました。
from gtts import gTTS
mytext = "マイネーム イズ マイク。アイ ハブ ア ペン、ウィッチ マイ グランドファーザー ゲイブ ミー、ア ロング タイム アゴウ"
speech = gTTS(text=mytext, lang='ja', slow=False)
speech.save("test7.mp3")
実行結果なかなかそう上手くはいかないようです。
何はともあれテキストを音声に変えることができました。
コロナのせいで対面のプレゼンテーションがウェブ発表やビデオ発表になっている方も多いと思います。
そんな時に自分で入れた音声は結構くぐもって聞こえるので、こういった音声読み上げを使用した方が多少の違和感があってもクリアに聞こえるということが少なくありません。
巷には色々な音声読み上げサービスも出ていますので、今回のPython、gTTSを使った音声読み上げ以外にも試してみると面白いかと思います。
次回はリスト内包表記で複数のリストを同時に作成する方法を解説していきます。
ではでは今回はこんな感じで。
コメント