pickle
前回、Pythonのmatplotlibでtight_layoutを使った際の余白の設定方法を紹介しました。
今回はオブジェクトをそのまま保存したり、その保存したオブジェクトを読み込んだりできるpickleというライブラリを紹介します。
通常Pythonで処理したデータは、例えばcsvファイルだったり、jsonだったり、なんらかのテキスト形式のファイルに変換して、保存することでしょう。
ですが、その際に変換する手間だったり、変換するためのCPU的、もしくは時間的コストがかかってしまいます。
pickleではPythonのオブジェクトをそのままファイルに保存できるため、そのようなコストがかからないというのがメリットのようです。
ただしファイル自体はバイナリファイルとして保存されることから、テキストエディターなどのソフトでは開けないことに注意です。
それでは始めていきましょう。
pickleでオブジェクトを保存
まず通常のファイルの保存を見てみましょう。
ls = range(1000)
with open("test1.txt", "w") as f_out:
for i in ls:
f_out.write(str(i))range関数を使って、0から999までの数値のリストを作成しました。
そしてopen関数の”w”モードでファイルを作成して、開きます。
そのファイルにデータを書き込んでいくのですが、テキストファイルではPythonのオブジェクト(ここではrange関数で作成したリスト)はそのままでは保存できません。
そこでfor文を使って一つずつファイルに書き込んでいます。
これが通常のファイルへのデータの保存です。
次にpickleでのデータの保存を見てみましょう。
import pickle
ls = range(1000)
with open("test1.pickle", "wb") as f_out:
pickle.dump(ls, f_out)pickleで保存する場合もopen関数を使ってファイルを開きます。
ただしこの際「wb」モード、つまりバイナリ(binary)の書き込み(write)モードで開くことに注意してください。
そしてオブジェクトを書き込むには「pickle.dump(オブジェクト, ファイル)」とします。
これでオブジェクトがそのままファイルに保存されます。
それでは実際にテキストエディタで開いて見てみましょう。
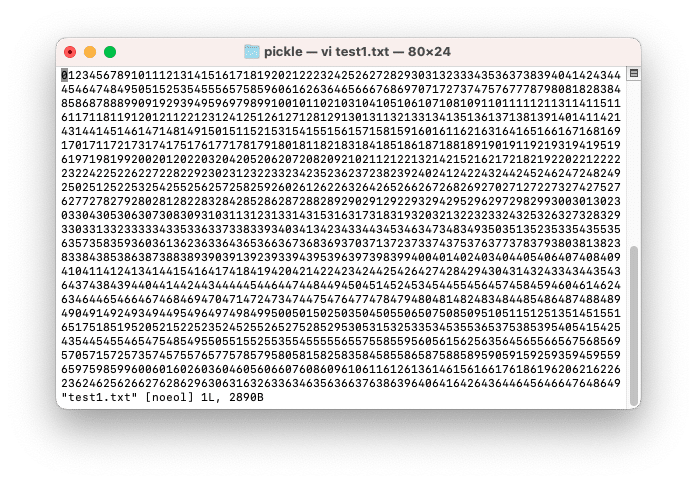
普通に保存したファイルではこんな感じで、数字の羅列が表示されました。
次にpickleを使って保存した場合はこんな感じです。
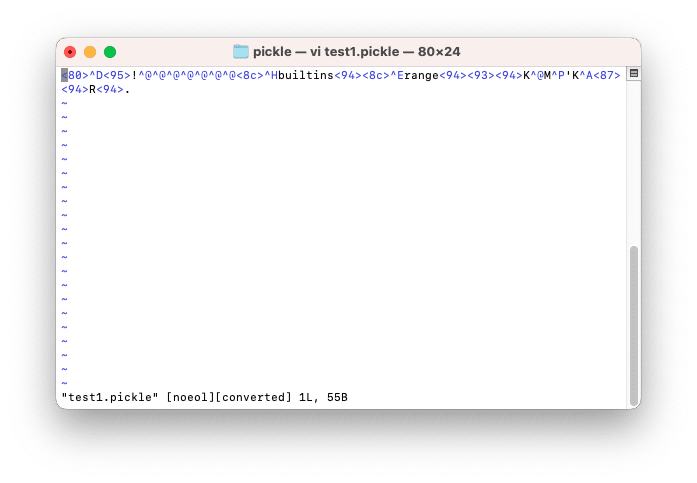
pickleを使って保存したファイルはバイナリファイルなので文字化けしていてちゃんとは読めませんが、全然書き込まれているデータの量が違います。
ちなみにファイルサイズとしては普通に保存したファイルでは「3KB」、pickleを使って保存した場合は「44バイト」となりました。
流石に差が出過ぎだと思い、range関数のままではなく、一度リストに保存してから、そのリストをpickleを使って保存するということをしてみました。
import pickle
ls = [i for i in range(1000)]
with open("test2.pickle", "wb") as f_out:
pickle.dump(ls, f_out)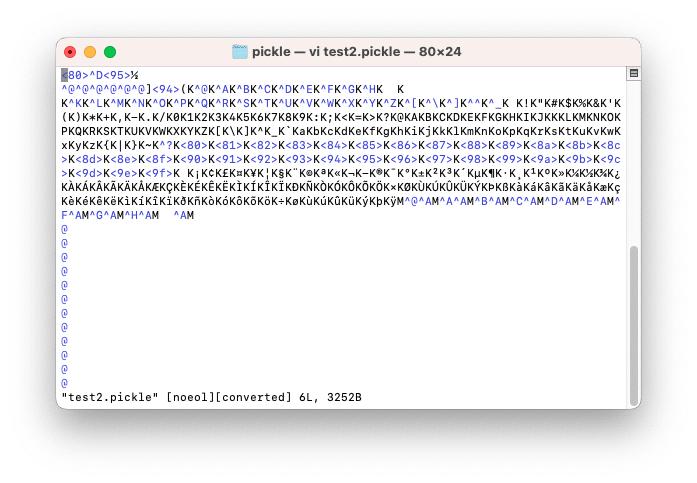
こちらもテキストエディタで開いても読めませんが、先ほどのrange関数のまま保存したものと比べてよりデータが書かれているのが分かります。
またファイルサイズも「3KB」になりました。
つまり同じ結果となるオブジェクトでも、どのオブジェクトで保存するのかによって保存のされ方が大きく変わるということです。
この点は普通のファイル保存と違い注意する点でしょう。
pickleで保存したファイルの読み込み
pickleで保存したファイルを読み込むにはバイナリの読み込みモード「rb」でファイルを開き、「pickle.load(ファイル)」で読み込みます。
import pickle
with open("test1.pickle", "rb") as f_in:
data = pickle.load(f_in)
print(data)
実行結果
range(0, 1000)ちなみに上の例ではrange関数で保存したファイルですが、リスト形式で保存したファイルはリスト形式で読み込まれます。
import pickle
with open("test2.pickle", "rb") as f_in:
data = pickle.load(f_in)
print(data)
実行結果
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
(中略)
991, 992, 993, 994, 995, 996, 997, 998, 999]書き込み速度の比較
jupyter notebooknの「%%timeit」のマジックコマンドを使って、①通常のファイル保存、②pickleを使ってrange関数を保存、③pickleを使ってリストを保存の3種類のファイル保存速度を比較してみました。
%%timeit
ls = range(10000)
with open("test1.txt", "w") as f_out:
for i in ls:
f_out.write(str(i))
実行結果
3.17 ms ± 225 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)%%timeit
import pickle
ls = range(10000)
with open("test1.pickle", "wb") as f_out:
pickle.dump(ls, f_out)
実行結果
357 µs ± 31.8 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)%%timeit
import pickle
ls = [i for i in range(10000)]
with open("test2.pickle", "wb") as f_out:
pickle.dump(ls, f_out)
実行結果
915 µs ± 13.6 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)結果として1番速かったのは②pickleを使ってrange関数を保存、次に③pickleを使ってリストを保存、最後に①通常のファイル保存でした。
②は出力されたファイルを見ても書き込まれたデータ量が少ないため、速く保存できたとしても不思議ではありません。
③は①とほぼ同じデータ量が出力されているにも関わらず、3分の1程度の時間で保存できているのはなかなか興味深い結果です。
とりあえずpickleを使うと基本的には速くデータが保存できそうです。
ファイル読み込み速度の比較
次に上記で作成した3種のファイルの読み込み速度を比較してみました。
%%timeit
with open("test1.txt", "r") as f_in:
data = [row for row in f_in]
実行結果
160 µs ± 21.4 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)%%timeit
import pickle
with open("test1.pickle", "rb") as f_in:
data = pickle.load(f_in)
実行結果
121 µs ± 16.3 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)%%timeit
import pickle
with open("test2.pickle", "rb") as f_in:
data = pickle.load(f_in)
実行結果
438 µs ± 25 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)読み込みに関しては②pickleを使ってrange関数を保存が一番速かったのですが、①通常のファイル保存もほぼ同じくらいの時間でファイルを保存できています。
ただし③pickleを使ってリストを保存は他の3倍以上の時間がかかっています。
このように保存したオブジェクトによってはファイルの読み込みが遅くなることもあるというのは注意点でしょう。
もしかしたらファイルの読み書きが劇的に速くなる可能性があるpickleですが、そこまで検証しながらプログラムを書くのは大変そうです。
とりあえず自分のプログラムに合うのか、使いながらプログラムをチューニングしていく必要がありそうです。
次回はPandasで列名が重複した列を取り除く方法を紹介します。
ではでは今回はこんな感じで。
コメント