Pandas
前回、PythonのPandasで外れ値を除去したり、置換する方法を紹介しました。
今回はPandasで特定の行や列を削除する方法、そして特定の値をもつデータを削除する方法を紹介します。
使うデータはこんな感じで作ってみました。
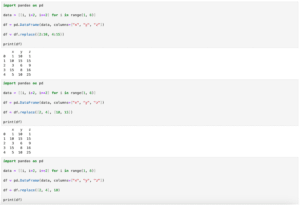
import pandas as pd
data = [[i, i*2, i**2] for i in range(1, 6)]
df = pd.DataFrame(data, columns=["x", "y", "z"])
print(df)
実行結果
x y z
0 1 2 1
1 2 4 4
2 3 6 9
3 4 8 16
4 5 10 25それでは始めていきましょう。
特定の行を削除
まずは特定の行や列を削除していきます。
使う関数は「drop(行のインデックス)」で、指定した行が削除されます。
import pandas as pd
data = [[i, i*2, i**2] for i in range(1, 6)]
df = pd.DataFrame(data, columns=["x", "y", "z"])
df = df.drop(2)
print(df)
実行結果
x y z
0 1 2 1
1 2 4 4
3 4 8 16
4 5 10 25指定しているのは行のインデックスなので注意してください。
ちなみにリスト形式で渡す(drop([行1, 行2]))と複数の行を一度に削除することもできます。
import pandas as pd
data = [[i, i*2, i**2] for i in range(1, 6)]
df = pd.DataFrame(data, columns=["x", "y", "z"])
df = df.drop([2, 4])
print(df)
実行結果
x y z
0 1 2 1
1 2 4 4
3 4 8 16特定の列を削除
次に特定の列を削除していきます。
列を削除する場合も「drop」を用いますが、「drop(“列名”, axis=1)」となります。
import pandas as pd
data = [[i, i*2, i**2] for i in range(1, 6)]
df = pd.DataFrame(data, columns=["x", "y", "z"])
df = df.drop("y", axis=1)
print(df)
実行結果
x z
0 1 1
1 2 4
2 3 9
3 4 16
4 5 25列を削除する場合もリスト形式で渡すと複数の列を一度に削除することができます。
import pandas as pd
data = [[i, i*2, i**2] for i in range(1, 6)]
df = pd.DataFrame(data, columns=["x", "y", "z"])
df = df.drop(["y", "z"], axis=1)
print(df)
実行結果
x
0 1
1 2
2 3
3 4
4 5inplace=True
ちなみに「drop」のオプションとして「inplace=True」とすると、元のデータフレームが更新されます。
import pandas as pd
data = [[i, i*2, i**2] for i in range(1, 6)]
df = pd.DataFrame(data, columns=["x", "y", "z"])
df.drop([2, 4], inplace=True)
print(df)
実行結果
x y z
0 1 2 1
1 2 4 4
3 4 8 16つまりこの場合は「df = df.drop([2, 4])」と同じ意味になります。
気をつけなければいけないのは「inplace=True」がない場合、元のデータフレームは置き換わらないということです。
import pandas as pd
data = [[i, i*2, i**2] for i in range(1, 6)]
df = pd.DataFrame(data, columns=["x", "y", "z"])
df.drop([2, 4])
print(df)
実行結果
x y z
0 1 2 1
1 2 4 4
2 3 6 9
3 4 8 16
4 5 10 25これはやりがちで、一瞬パニックになるので注意しましょう。
特定の値をもつデータを削除
ここからは特定の値をもつデータを削除する方法を紹介します。
ただ実は「削除する」のではなく、「特定の値をもつデータ以外を抽出する」という形でデータを取得します。
例えば「xが2以下のものを削除」したい場合、発想を逆転させて「xが2より大きいものを抽出」と考えます。
つまりこんな感じです。
import pandas as pd
data = [[i, i*2, i**2] for i in range(1, 6)]
df = pd.DataFrame(data, columns=["x", "y", "z"])
df = df[df["x"] > 2]
print(df)
実行結果
x y z
2 3 6 9
3 4 8 16
4 5 10 25複数の条件で抽出する場合、and、or、notはそれぞれ「&」、「|」、「~」を使い、さらにそれぞれの条件を括弧で括ります。
import pandas as pd
data = [[i, i*2, i**2] for i in range(1, 6)]
df = pd.DataFrame(data, columns=["x", "y", "z"])
df = df[(df["x"] != 2) & (df["y"] != 8)]
print(df)
実行結果
x y z
0 1 2 1
2 3 6 9
4 5 10 25「query(抽出条件)」を使っても同様に抽出可能です。
import pandas as pd
data = [[i, i*2, i**2] for i in range(1, 6)]
df = pd.DataFrame(data, columns=["x", "y", "z"])
df = df.query("x > 2")
print(df)
実行結果
x y z
2 3 6 9
3 4 8 16
4 5 10 25ちなみに「query」を用いた場合、条件に変数を使いたい時には変数に「@」をつけます。
import pandas as pd
data = [[i, i*2, i**2] for i in range(1, 6)]
df = pd.DataFrame(data, columns=["x", "y", "z"])
a = 2
df = df.query("x > @a")
print(df)
実行結果
x y z
2 3 6 9
3 4 8 16
4 5 10 25また複数の条件で抽出する場合はやはりand、or、notはそれぞれ「&」、「|」、「~」を使いますが、それぞれの条件を括弧でくくる必要はありません。
import pandas as pd
data = [[i, i*2, i**2] for i in range(1, 6)]
df = pd.DataFrame(data, columns=["x", "y", "z"])
df = df.query("x != 2 & y != 8")
print(df)
実行結果
x y z
0 1 2 1
2 3 6 9
4 5 10 25次回はPandasで特定の値を書き換える方法を紹介します。
ではでは今回はこんな感じで。
コメント