目次
enumerate
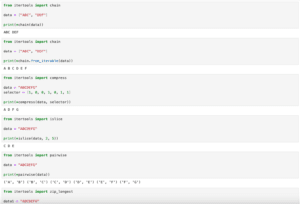
前回、itertoolsの文字列のイテレータであるchain、compress、islice、pairwise、zip_longestを紹介しました。
あわせて読みたい
【itertools】文字列のイテレータであるchain、compress、islice、pairwise、zip_longest[Python]
itertools 前回、itertoolsでリストの値の累積和や他の累積計算値を取得する関数accumulateを紹介しました。 今回はitertoolsの中の文字列のイテレータであるchain、com…
今回はenumerate関数の変わった使い方として開始値指定したり、奇数・偶数インデックスに分割したり、インデックスをキーとする辞書を作成したりする方法を紹介します。
まずenumerate関数のおさらいですが、for文と組み合わせて繰り返しの回数を取得できる関数でした。
data = ["A", "B", "C", "D", "E", "F"]
for i, val in enumerate(data):
print(i, val)
実行結果
0 A
1 B
2 C
3 D
4 E
5 Fちなみに前にこちらの記事で紹介していますので、よかったらどうぞ。
あわせて読みたい

【Python基礎】zip関数、enumerate関数、リスト内包表記
for文 前にfor文の基本的な使い方を紹介しました。 色々勉強してきて、もう少し高度な使い方があることが分かってきたので、まとめてみたいと思います。 その前に「for…
それでは始めていきましょう。
開始値を指定する方法
enumerate関数ではオプション引数として「start=値」を追加すると開始値を変更することができます。
data = ["A", "B", "C", "D", "E", "F"]
for i, val in enumerate(data, start=10):
print(i, val)
実行結果
10 A
11 B
12 C
13 D
14 E
15 F値にはマイナスの値も取ることができます。
data = ["A", "B", "C", "D", "E", "F"]
for i, val in enumerate(data, start=-10):
print(i, val)
実行結果
-10 A
-9 B
-8 C
-7 D
-6 E
-5 Fインデックスが偶数・奇数のものである要素に分割する方法
for文でリストから一つずつ要素を取得する際、enumerate関数を使うとその繰り返し回数、つまりはリストのインデックスと連動した値を取得することができます。
そのため取得した値を2で割り切れるか、割り切れないかをif文で条件分岐させることで、インデックスが偶数のものである要素、奇数のものである要素に分割することができます。
ちなみに割り算して余りが「0」となるかどうかは「if 値1 % 値2 == 0:」で表現することができます。
data = ["A", "B", "C", "D", "E", "F"]
even_index_val = []
odd_index_val = []
for i, val in enumerate(data):
if i % 2 == 0:
even_index_val.append(val)
else:
odd_index_val.append(val)
print(even_index_val)
print(odd_index_val)
実行結果
['A', 'C', 'E']
['B', 'D', 'F']リストからインデックスをキーとする辞書を作成する方法
enumerate関数を使って取得した繰り返し回数を辞書のキーとして使うとリストから辞書を作成することができます。
data = ["A", "B", "C", "D", "E", "F"]
data_dict = {}
for i, val in enumerate(data):
data_dict[i] = val
print(data_dict)
実行結果
{0: 'A', 1: 'B', 2: 'C', 3: 'D', 4: 'E', 5: 'F'}次回はリスト内包表記の変わった使い方を紹介します。
ではでは今回はこんな感じで。
コメント