辞書
前回、Pythonの複数のfor文からbreakで全てのfor文から抜ける方法を紹介しました。
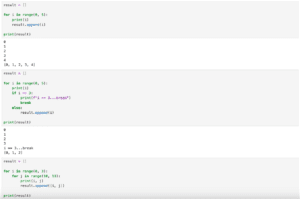
今回はネスト(複数の階層)された辞書の作成方法を紹介します。
事の発端はこんな感じで複数の階層をもつ(つまりネストされた)辞書を作成しようとした時にエラーとなってしまったことです。
val1_list = [10, 20, 30, 40, 50]
val2_list = [60, 70, 80, 90, 100]
result_dict = {}
for i, val1 in enumerate(val1_list):
for j, val2 in enumerate(val2_list):
result_dict[i][j] = val1*val2
print(result_dict)
実行結果
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[1], line 7
5 for i, val1 in enumerate(val1_list):
6 for j, val2 in enumerate(val2_list):
----> 7 result_dict[i][j] = val1*val2
9 print(result_dict)
KeyError: 0どうやらこのように複数の階層の下へ階層を作りつつ、一気に要素を格納することはできないようです。
ではどうしたらいいのかと考えて、やってみた結果を紹介します。
先に階層構造を作ってしまう方法
まずはとりあえずfor文を一回まわして階層だけ作り、2回目に要素を入れていく方法です。
val1_list = [10, 20, 30, 40, 50]
val2_list = [60, 70, 80, 90, 100]
result_dict = {}
for i in range(len(val1_list)):
result_dict[i] = {}
for j in range(len(val2_list)):
result_dict[i][j] = {}
for i, val1 in enumerate(val1_list):
for j, val2 in enumerate(val2_list):
result_dict[i][j] = val1*val2
print(result_dict)
実行結果
{0: {0: 600, 1: 700, 2: 800, 3: 900, 4: 1000},
1: {0: 1200, 1: 1400, 2: 1600, 3: 1800, 4: 2000},
2: {0: 1800, 1: 2100, 2: 2400, 3: 2700, 4: 3000},
3: {0: 2400, 1: 2800, 2: 3200, 3: 3600, 4: 4000},
4: {0: 3000, 1: 3500, 2: 4000, 3: 4500, 4: 5000}}コードが冗長になってしまいますが、役割がはっきりしていて分かりやすいかもしれません。
階層構造を作りつつ、要素を入れていく方法
次は一段ずつ階層構造を作りつつ、要素を入れていく方法です。
val1_list = [10, 20, 30, 40, 50]
val2_list = [60, 70, 80, 90, 100]
result_dict = {}
for i, val1 in enumerate(val1_list):
result_dict[i] = {}
for j, val2 in enumerate(val2_list):
result_dict[i][j] = val1*val2
print(result_dict)
実行結果
{0: {0: 600, 1: 700, 2: 800, 3: 900, 4: 1000},
1: {0: 1200, 1: 1400, 2: 1600, 3: 1800, 4: 2000},
2: {0: 1800, 1: 2100, 2: 2400, 3: 2700, 4: 3000},
3: {0: 2400, 1: 2800, 2: 3200, 3: 3600, 4: 4000},
4: {0: 3000, 1: 3500, 2: 4000, 3: 4500, 4: 5000}}作り方としてはこれがストレートな感じがします。
先に下の階層を作り、上の階層に格納する方法
最後は先に下の階層に要素を入れて完成させて、その後、上の階層に格納する方法です。
val1_list = [10, 20, 30, 40, 50]
val2_list = [60, 70, 80, 90, 100]
result_dict = {}
for i, val1 in enumerate(val1_list):
result_dict_temp = {}
for j, val2 in enumerate(val2_list):
result_dict_temp[j] = val1*val2
result_dict[i] = result_dict_temp
print(result_dict)
実行結果
{0: {0: 600, 1: 700, 2: 800, 3: 900, 4: 1000},
1: {0: 1200, 1: 1400, 2: 1600, 3: 1800, 4: 2000},
2: {0: 1800, 1: 2100, 2: 2400, 3: 2700, 4: 3000},
3: {0: 2400, 1: 2800, 2: 3200, 3: 3600, 4: 4000},
4: {0: 3000, 1: 3500, 2: 4000, 3: 4500, 4: 5000}}要素を格納していく順番にコードが書けるので理解がしやすいかもしれません。
処理速度の比較
とりあえずは書きやすいものを使えばいいと思いますが、処理速度に違いがあるのかをマジックコマンド「%%timeit」を使って確認してみました。
・先に階層構造を作ってしまう方法
%%timeit
val1_list = [10, 20, 30, 40, 50]
val2_list = [60, 70, 80, 90, 100]
result_dict = {}
for i in range(len(val1_list)):
result_dict[i] = {}
for j in range(len(val2_list)):
result_dict[i][j] = {}
for i, val1 in enumerate(val1_list):
for j, val2 in enumerate(val2_list):
result_dict[i][j] = val1*val2
実行結果
10.1 μs ± 289 ns per loop (mean ± std. dev. of 7 runs,
100,000 loops each)・階層構造を作りつつ、要素を入れていく方法
%%timeit
val1_list = [10, 20, 30, 40, 50]
val2_list = [60, 70, 80, 90, 100]
result_dict = {}
for i, val1 in enumerate(val1_list):
result_dict[i] = {}
for j, val2 in enumerate(val2_list):
result_dict[i][j] = val1*val2
実行結果
5.43 μs ± 88.1 ns per loop (mean ± std. dev. of 7 runs,
100,000 loops each)・先に下の階層を作り、上の階層に格納する方法
%%timeit
val1_list = [10, 20, 30, 40, 50]
val2_list = [60, 70, 80, 90, 100]
result_dict = {}
for i, val1 in enumerate(val1_list):
result_dict_temp = {}
for j, val2 in enumerate(val2_list):
result_dict_temp[j] = val1*val2
result_dict[i] = result_dict_temp
実行結果
4.86 μs ± 49.3 ns per loop (mean ± std. dev. of 7 runs,
100,000 loops each)3回ずつくらい試してみましたが、大体同じ結果になりました。
「先に階層構造を作ってしまう方法」はやはり同じfor文を2回回すことになることから、倍の時間がかかってしまいます。
「階層構造を作りつつ、要素を入れていく方法」と「先に下の階層を作り、上の階層に格納する方法」は大体同じ処理時間でしたが、若干「先に下の階層を作り、上の階層に格納する方法」の方が速い感じでした。
次回はPandasの「FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. 」の警告への対処法を紹介します。
ではでは今回はこんな感じで。
コメント