漢字間違い探しクイズ
前に漢字間違い探しクイズを自動生成するプログラムを作成し、TwitterやDjangoで公開してみました。

Djangoで作ったWebページの方はアクセス解析をつけていないのでどれくらいの人が使ってくれているのか分かりませんが、Twitterでは少しずつファンも付き、楽しんでくれる人が増えてきています。
ということで表示するフォントを増やしたり、問題数を増やしたりすることで、楽しんでもらえるように拡大していきました。
ただその時にぶち当たった壁が「文字化け」。
日本語フォントと言っても流石に全ての漢字が含まれているとは限りません。
そして漢字を扱うこのクイズ。
文字化けする、出力されないとなると致命的なわけです。
ということで問題にある漢字に対して、全てのフォントを確認する「フォントチェッカー」なるものを作成してみました。
ではでは始めていきましょう。
プログラム全体
まずはプログラム全体をお見せします。
default_dir = './'
import json
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import os
%matplotlib notebook
question_start = 1
question_end = 20
def jsonDataGet(jsonfile):
with open(jsonfile, 'r') as f_in:
json_dic = json.load(f_in)
return json_dic
def figMake(question_dic, fonts_dic, default_dir):
horizontal = len(fonts_dic)
for i in range(question_start, question_end):
fig = plt.figure(figsize=((horizontal+1)/5, 3))
plt.clf()
for h in range(1, horizontal+1):
font_name = list(fonts_dic)[h-1]
font_path = os.path.join(default_dir, fonts_dic[font_name])
fp = fm.FontProperties(fname=font_path)
plt.text(h/horizontal, 4, font_name, fontsize=12, rotation=90, fontproperties=fp)
plt.text(h/horizontal, 2, question_dic[str(i)][0], fontsize=12, fontproperties=fp)
plt.text(h/horizontal, 1, question_dic[str(i)][1], fontsize=12, fontproperties=fp)
plt.ylim(0,10)
plt.gca().spines['right'].set_visible(False)
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['bottom'].set_visible(False)
plt.gca().spines['left'].set_visible(False)
plt.tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False, bottom=False, left=False, right=False, top=False)
plt.show()
def main():
question_json = os.path.join(default_dir, 'question.json')
fonts_json = os.path.join(default_dir, 'fonts.json')
question_list = questionListGet(question_json)
fonts_list = fontsListGet(fonts_json)
figMake(question_list, fonts_list, default_dir)
if __name__ == '__main__':
main()という感じですが、後で思ったのは実行形式(最後のif name == ‘main’:の部分)にする必要はなかったなと。
それでは解説していきましょう。
インポート&設定
まずはインポートと設定部分です。
default_dir = './'
import json
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import os
%matplotlib notebook
question_start = 1
question_end = 20インポートしているのは「json」、「matplotlibのpyplot」、「matplotlibのfont_manager」、「os」です。
またJupyter Notebook上で画像を表示させるため「%matplotlib notebook」のマジックコマンドをつけています。
設定としては3つで「default_dir」でデフォルトのフォルダ位置の定義、そして問題の範囲を設定するための「question_start」と「question_end」です。
問題の範囲の設定とは、今回のプログラムは問題一つ(漢字2つ)に対して一つの画像を生成します。
そのため何百という大量の問題を一度にプログラムで処理してしまうと、時間がかかってしまうことから問題数を区切るようにしました。
問題とフォントのJSONファイル読み込み関数
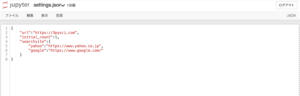
問題とフォントのリストはJSONファイルとして保存しています。
そこでJSONファイルを読み込み、辞書形式にして出力する関数を準備しました。
def jsonDataGet(jsonfile):
with open(jsonfile, 'r') as f_in:
json_dic = json.load(f_in)
return json_dic特に難しいことはなく「with open(json, ‘r’) as f_in:」でファイルを開き、「json_dic = json.load(f_in)」で辞書形式に変換しているだけです。
こちらの記事で解説していますので、よかったらどうぞ。
画像生成用関数
次に漢字とフォントを確認するための画像を生成する関数です。
def figMake(question_dic, fonts_dic, default_dir):
horizontal = len(fonts_dic)
for i in range(question_start, question_end):
fig = plt.figure(figsize=((horizontal+1)/5, 3))
plt.clf()
for h in range(1, horizontal+1):
font_name = list(fonts_dic)[h-1]
font_path = os.path.join(default_dir, fonts_dic[font_name])
fp = fm.FontProperties(fname=font_path)
plt.text(h/horizontal, 4, font_name, fontsize=12, rotation=90, fontproperties=fp)
plt.text(h/horizontal, 2, question_dic[str(i)][0], fontsize=12, fontproperties=fp)
plt.text(h/horizontal, 1, question_dic[str(i)][1], fontsize=12, fontproperties=fp)
plt.ylim(0,10)
plt.gca().spines['right'].set_visible(False)
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['bottom'].set_visible(False)
plt.gca().spines['left'].set_visible(False)
plt.tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False, bottom=False, left=False, right=False, top=False)
plt.show() 構成がなかなか厄介ですが、順番に見ていきましょう。
まず中途半端ですが、ここまで。
horizontal = len(fonts_dic)
for i in range(question_start, question_end):
fig = plt.figure(figsize=((horizontal+1)/5, 3))
plt.clf()「horizontal = len(fonts_dic)」では横の長さをフォントの数から定義しています。
そして「for i in range(question_start, question_end):」で設定部分で定義した問題の範囲を使って、繰り返し処理を始めていきます。
「fig = plt.figure(figsize=((horizontal+1)/5, 2))」で画像サイズを設定しています。
この際、縦はとりあえず3で固定、横はフォントの数で可変にするため、先ほど横の長さをフォントから定義した変数を使っています。
多少割ったり足したりしているのは、画像のサイズの調整ですので、ここら辺はお好みでどうぞ。
「plt.clf()」はおまじないで、とりあえず作成した画像エリアを一度クリアしています。
それでは次にいきましょう。
for h in range(1, horizontal+1):
font_name = list(fonts_dic)[h-1]
font_path = os.path.join(default_dir, fonts_dic[font_name])
fp = fm.FontProperties(fname=font_path)
plt.text(h/horizontal, 4, font_name, fontsize=12, rotation=90, fontproperties=fp)
plt.text(h/horizontal, 2, question_dic[str(i)][0], fontsize=12, fontproperties=fp)
plt.text(h/horizontal, 1, question_dic[str(i)][1], fontsize=12, fontproperties=fp)今回のプログラムの1番のキモがこちらです。
「for h in range(1, horizontal+1):」で横の長さ、つまりフォントの数に対して繰り返しをしています。
ここで最初を「1」、最後を「horizontal+1」にしているのは、あとで出てくるテキストの描写「plt.text(h/horizontal,…」のhを0にしないためです。
そして次の3行でフォントを取得し、matplotlibのfont_managerに読み込ませます。
font_name = list(fonts_list)[h-1]
font_path = os.path.join(default_dir, fonts_list[font_name])
fp = fm.FontProperties(fname=font_path)「font_name = list(fonts_dic)[h-1]」では、JSONファイルで読み込んだデータは辞書形式になっているので「list(辞書)」でリスト形式に変換し、インデックスを指定することでその値を取得しています。
「[h-1]」と1を引いているのは、先ほど繰り返しの範囲を「1からhorizontal+1」までに指定したのに対し、リストは「0からhorizontal」までなので合わせるために「1を引いて」います。
次の3行がテキストとしてmaplotlibの画像エリアに書き込んでいる部分です。
plt.text(h/horizontal, 4, font_name, fontsize=12, rotation=90, fontproperties=fp)
plt.text(h/horizontal, 2, question_dic[str(i)][0], fontsize=12, fontproperties=fp)
plt.text(h/horizontal, 1, question_dic[str(i)][1], fontsize=12, fontproperties=fp)画像エリアに書き込むのは基本的には「plt.text(x, y, ’文字’)」です。
最初の「plt.text(h/horizontal, 4, font_name, fontsize=12, rotation=90, fontproperties=fp)」でフォント名を出力していますが、この際「rotation=90」とすることで90度傾けています。
最後に縦横の罫線やラベルを消し、画像として表示しています。
plt.gca().spines['right'].set_visible(False)
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['bottom'].set_visible(False)
plt.gca().spines['left'].set_visible(False)
plt.tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False, bottom=False, left=False, right=False, top=False)
plt.show() この部分は最初の4行で枠線を、最後の1行で軸のメモリ線を消しています。
こちらの記事でも使っていて、今度解説しますといってまだしていませんでしたので、近いうちに解説記事を作ろうと思います。

main関数
最後に先ほどの関数をまとめて、実際に実行する「main関数」の部分です。
def main():
question_json = os.path.join(default_dir, 'question.json')
fonts_json = os.path.join(default_dir, 'fonts.json')
question_dic = jsonDataGet(question_json)
fonts_dic = jsonDataGet(fonts_json)
figMake(question_dic, fonts_dic, default_dir)最初2行でJSONファイルのパスを定義しています。
question_json = os.path.join(default_dir, 'question.json')
fonts_json = os.path.join(default_dir, 'fonts.json')定義したJSONファイルのパスと先ほど作成した「jsonDataGet関数」を使って、JSONファイルのデータを辞書形式にして取得しています。
question_dic = jsonDataGet(question_json)
fonts_dic = jsonDataGet(fonts_json)あとは画像を作成する「figMake関数」にそれらを入力しています。
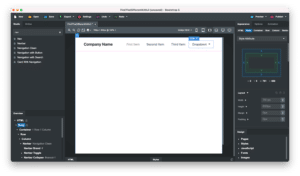
これで作成される画像はこんな感じです。

これが選択した問題の数だけ表示されます。
ちなみにフォントに対して、指定した漢字がない場合はこのような表示になります。

これで例えば「MPLUS」のシリーズや「Sawarabi」のシリーズには「稍」のフォントが含まれておらず、文字化けや空白になってしまうことが分かります。
大量の問題に対して、大量のフォントを試していくので、一度に全部試すにはマシンパワーが必要になりますので、このように区切って表示する形式にしましたが、これでかなり確認しやすくなりました。
ではでは今回はこんな感じで。
コメント