Pandas
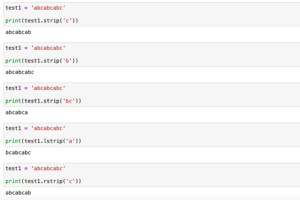
前回、Pythonで末端の文字を削除するstrip、lstrip、rstripを勉強しました。
今回は自分が苦戦したPandasのデータフレーム間のデータのコピーを自分への備忘録として解説していきます。
特に複数のデータのコピーではなく、1列や1行といったデータのコピーで、実は1行のデータのコピーをするときにどハマりしましたので、そのどハマりポイントも一緒に説明していきます。
まずは今回使うデータをこんなふうに作ってみました。
import pandas as pd
data1 = [[1, 2, 3], [1, 4, 9], [1, 8, 27]]
data2 = [[2, 4, 8], [3, 9, 27]]
df1 = pd.DataFrame(data1, columns=['a', 'b', 'c'])
df2 = pd.DataFrame(data2, columns=['a', 'b', 'c'])
print(df1)
print()
print(df2)
実行結果
a b c
0 1 2 3
1 1 4 9
2 1 8 27
a b c
0 2 4 8
1 3 9 27両方とも「a列、b列、c列」があり、そこにそれぞれ3つと2つのデータが入っています。
今回はdf2のデータをdf1にコピーしていきますが、その場合df1がどんどん上書きされていきますので、毎回上のプログラムを実行して元のデータフレームにしていますので、注意してください。
それでは始めていきましょう。
1列のコピー
最初に簡単な1列のコピーです。
これは特に迷うことはなく、df2のコピーしたい列をdf1の新しい列に移すだけです。
import pandas as pd
data1 = [[1, 2, 3], [1, 4, 9], [1, 8, 27]]
data2 = [[2, 4, 8], [3, 9, 27]]
df1 = pd.DataFrame(data1, columns=['a', 'b', 'c'])
df2 = pd.DataFrame(data2, columns=['a', 'b', 'c'])
df1['d'] = df2['c']
print(df1)
実行結果
a b c d
0 1 2 3 8.0
1 1 4 9 27.0
2 1 8 27 NaNちなみにこの方法でコピーするとコピー前のデータとコピー後のデータは連動していません。
そのためdf2のデータを変更しても、コピーしたdf1のデータは変更されませんのでご注意ください。
df2.iloc[1,2] = 81
print(df1)
print()
print(df2)
実行結果
a b c d
0 1 2 3 8.0
1 1 4 9 27.0
2 1 8 27 NaN
a b c
0 2 4 8
1 3 9 811行のコピー
次に1行のコピーを行なっていきます。
1行コピーするだけなら「append」を使いたいところですが、こちらの記事であったように「append」は将来無くなる関数であるため、使わない方が無難です。
ということでデータフレームを連結する「concat」を使っていきます。
今回は「df2の2行目(df2.iloc[1])」のデータをdf1にコピーしようとしてみました。
import pandas as pd
data1 = [[1, 2, 3], [1, 4, 9], [1, 8, 27]]
data2 = [[2, 4, 8], [3, 9, 27]]
df1 = pd.DataFrame(data1, columns=['a', 'b', 'c'])
df2 = pd.DataFrame(data2, columns=['a', 'b', 'c'])
df1 = pd.concat([df1, df2.iloc[1]])
print(df1)
実行結果
a b c 0
0 1.0 2.0 3.0 NaN
1 1.0 4.0 9.0 NaN
2 1.0 8.0 27.0 NaN
a NaN NaN NaN 3.0
b NaN NaN NaN 9.0
c NaN NaN NaN 27.0思ったような結合はできませんでした。
このような結合のされ方は先ほど紹介した記事でもありましたが、SeriesをDataFrameに結合したときの結合のされ方です。
そこで「df2.iloc[1]」の型を確認してみました。
print(type(df2.iloc[1]))
実行結果
<class 'pandas.core.series.Series'>確かにSeriesですので、これをDataFrame型にしなければいけません。
SeriesからDetaFrameにしてコピー
ということでSeriesからDataFrameに変更する方法です。
SeriesからDataFrameにするには「pd.DataFrame(Seriesのデータ).transpose()」とします。
「.transpose()」はDataFrameの行と列を入れ替える関数で、Seriesはデータの行と列の情報が入っておらず、そのままDataFrameに変換すると列だったものが行に、行だったものが列になってしまいます。
そのため「.transpose()」で入れ替えるというわけです。
import pandas as pd
data1 = [[1, 2, 3], [1, 4, 9], [1, 8, 27]]
data2 = [[2, 4, 8], [3, 9, 27]]
columnnames = ['a', 'b', 'c']
df1 = pd.DataFrame(data1, columns=['a', 'b', 'c'])
df2 = pd.DataFrame(data2, columns=['a', 'b', 'c'])
df3 = pd.DataFrame(df2.iloc[1]).transpose()
df1 = pd.concat([df1, df3])
print(df1)
実行結果
a b c
0 1 2 3
1 1 4 9
2 1 8 27
1 3 9 27確かにdf2の2行目がdf1の一番下の行に追加されました。
DataFrameから1行をDataFrameとして取り出してコピー
もう一つの方法はDataFrameから1行取り出すとSeriesになってしまうのですが、取り方を変えるとDataFrameとして取り出せることがあります。
その方法は「行の範囲として取り出す」という方法です。
df2の1行目をDataFrameで取得するには「df2.iloc[1:2](データフレーム名.iloc[取り出したい行のインデックス, 取り出したい行のインデックス+1])]とします。
import pandas as pd
data1 = [[1, 2, 3], [1, 4, 9], [1, 8, 27]]
data2 = [[2, 4, 8], [3, 9, 27]]
columnnames = ['a', 'b', 'c']
df1 = pd.DataFrame(data1, columns=['a', 'b', 'c'])
df2 = pd.DataFrame(data2, columns=['a', 'b', 'c'])
df3 = df2.iloc[1:2]
df1 = pd.concat([df1, df3])
print(df1)
実行結果
a b c
0 1 2 3
1 1 4 9
2 1 8 27
1 3 9 27確かに新しい行として追加されました。
ついでに「df2.iloc[1:2]」で取得した値がDataFrame型か確認しておきましょう。
print(type(df3))
実行結果
<class 'pandas.core.frame.DataFrame'>確かにDataFrame型でした。
また1行コピーからは話がずれますが、複数行コピーする際もこのデータの取得方法は使えます。
import pandas as pd
data1 = [[1, 2, 3], [1, 4, 9], [1, 8, 27]]
data2 = [[2, 4, 8], [3, 9, 27]]
columnnames = ['a', 'b', 'c']
df1 = pd.DataFrame(data1, columns=['a', 'b', 'c'])
df2 = pd.DataFrame(data2, columns=['a', 'b', 'c'])
df3 = df2.iloc[0:2]
df1 = pd.concat([df1, df3])
print(df1)
print(type(df3))
実行結果
a b c
0 1 2 3
1 1 4 9
2 1 8 27
0 2 4 8
1 3 9 27
<class 'pandas.core.frame.DataFrame'>新しいデータフレームに1行ずつコピー
コピー先のデータフレームが新しいデータフレームの場合、追加したいデータを全て追加してから「.transpose()」で行と列の入れ替えをするという方法もできます。
import pandas as pd
data2 = [[2, 4, 8], [3, 9, 27]]
columnnames = ['a', 'b', 'c']
df1 = pd.DataFrame()
df2 = pd.DataFrame(data2, columns=['a', 'b', 'c'])
df1 = pd.concat([df1, df2.iloc[0]], axis=1)
df1 = pd.concat([df1, df2.iloc[1]], axis=1)
df1 = df1.transpose()
print(df1)
実行結果
a b c
0 2 4 8
1 3 9 27新しいデータフレームに1行ずつコピーしていく場合はこちらの方がプログラムはすっきりするかもしれません。
データの取得方法をほんのちょっと変えるだけで、SeriesかDataFrameかが変わってしまい、その後の処理に影響が出るだなんて、Pandasはやっぱり奥が深いなと思いました。
次回はリスト内の要素の型を全て変換する方法を勉強します。
ではでは今回はこんな感じで。
コメント