itertools
前回、itertoolsでリストの値の累積和や他の累積計算値を取得する関数accumulateを紹介しました。
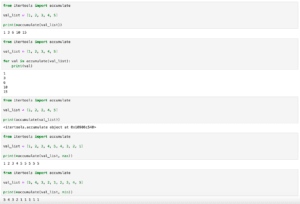
今回はitertoolsの中の文字列のイテレータであるchain、compress、islice、pairwise、zip_longestを紹介します。
ちなみにイテレータなのでアンパックしないとprint関数で表示できないため、「*(アスタリスク)」を使ったアンパックをしていますのでご注意ください。
それでは始めていきましょう。
chain
chainは連続した文字列を一つずつの文字列に分割するイテレータです。
使い方はまずはitertoolsの「chain」をインポートし、「chain(文字列)」として使用します。
from itertools import chain
data = "ABCDEFG"
print(*chain(data))
実行結果
A B C D E F G分かりにくいのでfor文で一つずつ表示してみましょう。
from itertools import chain
data = "ABCDEFG"
for val in chain(data):
print(val)
実行結果
A
B
C
D
E
F
Gちなみにchainは文字列(str型)にしか使うことができず、int型に使うとエラーとなります。
from itertools import chain
data = 1234567
print(*chain(data))
実行結果
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[9], line 5
1 from itertools import chain
3 data = 1234567
----> 5 print(*chain(data))
TypeError: 'int' object is not iterablechainの引数に文字列のリストを渡すとそれぞれの要素に分割します。
from itertools import chain
data = ["ABC", "DEF"]
print(*chain(data))
実行結果
print(*chain(data))この場合、各要素を一つずつの文字列に分割してくれるわけではないので注意です。
もし複数の文字列を要素にもつリストから、全ての要素の文字列を一つずつの文字列に分割したい場合は「chain.from_iterable(リスト)」を用います。
from itertools import chain
data = ["ABC", "DEF"]
print(*chain.from_iterable(data))
実行結果
A B C D E Fcompress
compressは文字列から、セレクタを使って文字を抽出する関数です。
itertoolsの「compress」をインポートして、文字列と0、1からなるリスト(セレクタ)を用いて文字列から文字を抽出します。
from itertools import compress
data = "ABCDEFG"
selector = [1, 0, 0, 1, 0, 1, 1]
print(*compress(data, selector))
実行結果
A D F Gこのようにセレクタの「1」とした文字が抽出されます。
islice
文字列からある範囲の文字を抽出し、一つ一つに分割するのがisliceです。
itertoolsの「islice」をインポートし、「islice(文字列, 開始インデックス, 終了インデックス)」で文字を抽出します。
from itertools import islice
data = "ABCDEFG"
print(*islice(data, 2, 5))
実行結果
C D Epairwise
pairwiseは文字列を一つ一つの文字に分割し、連続する2つの文字をタプルとしてまとめる関数です。
itertoolsの「pairwise」をインポートし、「pairwise(文字列)」として使用します。
from itertools import pairwise
data = "ABCDEFG"
print(*pairwise(data))
実行結果
('A', 'B') ('B', 'C') ('C', 'D') ('D', 'E') ('E', 'F') ('F', 'G')zip_longest
zipは複数のリストや文字列を一つずつ取得し、タプルにするイテレータです。
二つのリストや文字列の長さが違う場合、短い方に合わせられます。
from itertools import zip_longest
data1 = "ABCDEFG"
data2 = "abcde"
print(*zip(data1, data2))
実行結果
('A', 'a') ('B', 'b') ('C', 'c') ('D', 'd') ('E', 'e')zip_longestは長い方に合わせるイテレータです。
itertoolsの「zip_longest」をインポートし、「zip_longest(文字列1, 文字列2)」として使用します。
from itertools import zip_longest
data1 = "ABCDEFG"
data2 = "abcde"
print(*zip_longest(data1, data2))
実行結果
('A', 'a') ('B', 'b') ('C', 'c') ('D', 'd') ('E', 'e')
('F', None) ('G', None)文字列が短く足りない場合は「None」で埋めてくれます。
引数は文字列の代わりにリストでも大丈夫です。
from itertools import zip_longest
data1 = ["A", "B", "C", "D", "E", "F", "G"]
data2 = ["a", "b", "c", "d", "e"]
print(*zip_longest(data1, data2))
実行結果
('A', 'a') ('B', 'b') ('C', 'c') ('D', 'd') ('E', 'e')
('F', None) ('G', None)「fillvalue=値」のオプション引数を追加すると足りない部分をNoneの代わりに指定した文字で埋めてくれます。
from itertools import zip_longest
data1 = "ABCDEFG"
data2 = "abcde"
print(*zip_longest(data1, data2, fillvalue="X"))
実行結果
('A', 'a') ('B', 'b') ('C', 'c') ('D', 'd') ('E', 'e')
('F', 'X') ('G', 'X')次回はenumerate関数の変わった使い方(開始値指定、奇数・偶数インデックスに分割、辞書を作成)を紹介します。
ではでは今回はこんな感じで。
コメント