openCV
前回、openCVで確率的ハフ変換により直線を検出する方法を紹介しました。
今回はopenCVで図形の輪郭を検出する方法を紹介します。
使う画像は前回同様こちらの画像(shapedetection.png)です。

それでは始めていきましょう。
図形を検出:cv2.findContours
図形を検出するには「cv2.findContours(画像, 輪郭の取得方法, 座標の取得方法)」とします。
そして戻り値としては輪郭座標(contours)と輪郭の階層(hierarchy)が戻ってきます。
輪郭の取得方法には以下の5つがあるようです。
- cv2.RETR_EXTERNAL
- cv2.RETR_LIST
- cv2.RETR_CCOMP
- cv2.RETR_TREE
- cv2.RETR_FLOODFILL
また輪郭の階層には以下の4つがあるようです。
- cv2.CHAIN_APPROX_NONE
- cv2.CHAIN_APPROX_SIMPLE
- cv2.CHAIN_APPROX_TC89_L1
- cv2.CHAIN_APPROX_TC89_KCOS
それぞれどのような違いがあるのかはこちらのサイトが詳しいのでよかったら見てみてください。
とりあえず「cv2.RETR_EXTERNAL」と「cv2.CHAIN_APPROX_SIMPLE」を使って試してみましょう。
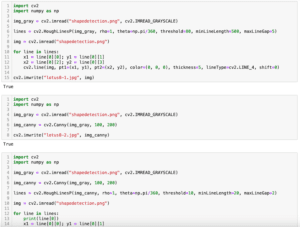
import cv2
img_gray = cv2.imread("shapedetection.png", cv2.IMREAD_GRAYSCALE)
contours, hierarchy = cv2.findContours(img_gray, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
print(contours)
print(hierarchy)
実行結果
(array([[[ 0, 0]],
[[ 0, 439]],
[[599, 439]],
[[599, 0]]], dtype=int32),)
[[[-1 -1 -1 -1]]]4つの点(?)が取得できたようです。
これを最初の図に重ね合わせてみます。
図に書き込む場合は「cv2.drawContours(画像, contours, 書き込む図形の番号, color=(B, G, R), thickness=線の太さ, lineType=線の種類)」とします。
書き込む図形の番号は「-1」にするとすべての図形を書き込みます。
import cv2
img_gray = cv2.imread("shapedetection.png", cv2.IMREAD_GRAYSCALE)
contours, hierarchy = cv2.findContours(img_gray, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
img = cv2.imread("shapedetection.png")
for contour, hi in zip(contours, hierarchy):
print(contour)
print(hierarchy)
boader = cv2.drawContours(img, contours, -1, color=(0, 0, 0), thickness=5, lineType=cv2.LINE_4)
cv2.imwrite("shape9-1.jpg", boader)
実行結果
[[[ 0 0]]
[[ 0 439]]
[[599 439]]
[[599 0]]]
[[[-1 -1 -1 -1]]]
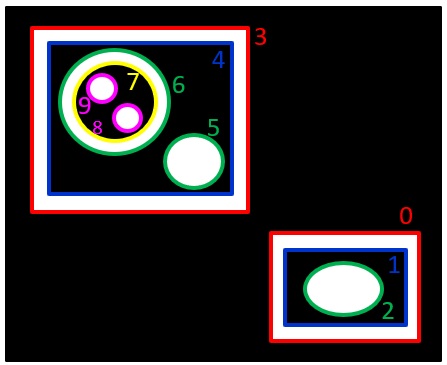
黒先が検出された図形ですが、どうやら外枠の部分が図形と認識されたようです。
これでは思っていたものと違います。
そこで前回、直線を検出したようにCanny法でエッジ検出をしてから図形の検出「cv2.findContours」をしてみましょう。
import cv2
img_gray = cv2.imread("shapedetection.png", cv2.IMREAD_GRAYSCALE)
img_canny = cv2.Canny(img_gray, 100, 200)
contours, hierarchy = cv2.findContours(img_canny, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
print(contours)
実行結果
(array([[[481, 323]],
[[480, 324]],
[[474, 324]],
(中略)
[[132, 111]],
[[132, 38]],
[[130, 36]]], dtype=int32))Canny法によるエッジ検出をやらなかった場合と比べて大量のデータが取得できました。
得られたデータを最初の図に書き込んでみましょう。
import cv2
img_gray = cv2.imread("shapedetection.png", cv2.IMREAD_GRAYSCALE)
img_canny = cv2.Canny(img_gray, 100, 200)
contours, hierarchy = cv2.findContours(img_canny, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
img = cv2.imread("shapedetection.png")
for contour, hi in zip(contours, hierarchy):
print(contour)
print(hierarchy)
boader = cv2.drawContours(img, contours, -1, color=(0, 0, 0), thickness=5, lineType=cv2.LINE_4)
cv2.imwrite("shape9-2.jpg", boader)
実行結果
[[[481 323]]
[[480 324]]
[[474 324]]
(中略)
[[490 324]]
[[483 324]]
[[482 323]]]
[[[ 1 -1 -1 -1]
[ 2 0 -1 -1]
[ 3 1 -1 -1]
[ 4 2 -1 -1]
[ 5 3 -1 -1]
[ 6 4 -1 -1]
[ 7 5 -1 -1]
[-1 6 -1 -1]]]
次回はプログラムやライブラリの場所を探す方法を紹介します。
ではでは今回はこんな感じで。
コメント