Pandas
今回はPandasのデータがBool値(True/False)の場合のデータの抽出方法、そして条件に合う行、列のカウント方法を勉強していきます。
これまで私がPandasのデータとして扱っていたのは数値が中心でした。
しかし、あるデータベースを作成していたときに、Bool値を使って分類しみたら、それをどうやって抽出したらいいのか、カウントしたらいいのか分からなくて調べたので、せっかくだから記事にしようというのが今回は発端。
ということでまずはBool値をもつデータフレームを作成します。
import pandas as pd
import random
num_columns = 5
num_rows = 10
TrueFalse = [True, False]
array_list = []
for i in range(num_rows):
array_list.append(random.choices(TrueFalse, k=num_columns))
columnname_list = [f'column{i}' for i in range(num_columns)]
df = pd.DataFrame(data=array_list, columns=columnname_list)
df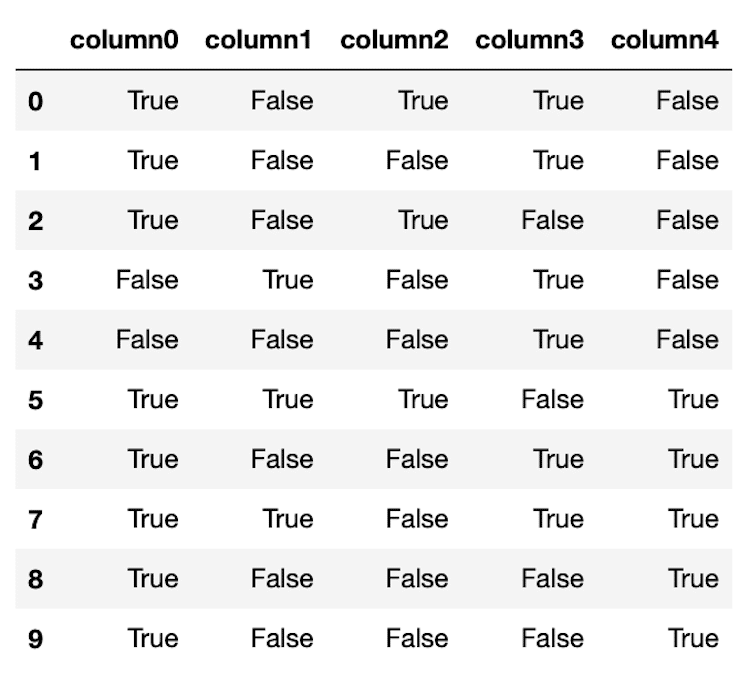
True、Falseをリストに格納し、それを「random.choices」で必要な数だけ抽出し、2次元配列を作成しています。
ちなみにそのままPandasのデータフレームにすると、行列の名前が「0, 1, 2, 3, 4, 5…」と同じ名前になってしまうので、別途、列名用に「columnname_list」を準備しています。
これでランダムにTrue/Falseの値をもつデータフレームができました。
特定の列がTrue、またはFalseの行を取得
まずは特定の列がTrue、もしくはFalseになっている行を取得してみます。
その場合は「df[df[‘カラム名’] == True]」もしくは「df[df[‘カラム名’] == False]」とします。
今回はTrueの場合だけ試してみましょう。
df1 = df[df['column1'] == True]
df1
複数の列の条件を指定する方法
さらに複数の列の条件を指定する場合は「&」(両方とも)、「|」(または)を使用します。
このときそれぞれの条件は括弧で括る必要があるので注意です。
df2 = df[(df['column1'] == True)&(df['column4'] == True)]
df2
df3 = df[(df['column1'] == True)|(df['column4'] == True)]
df3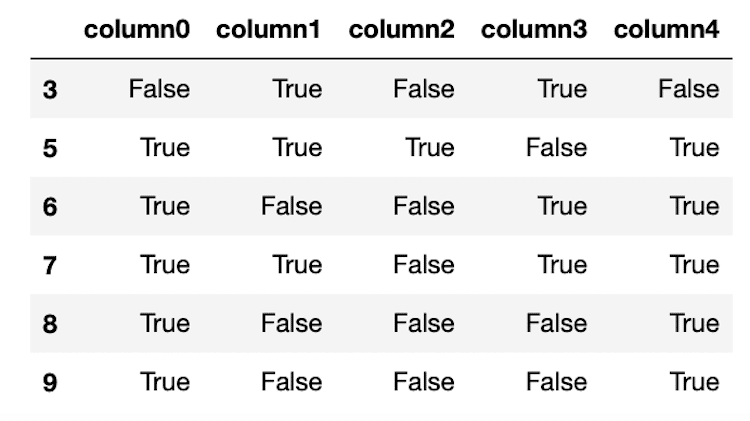
それぞれの列のTrue、もしくはFalseの数をカウント
次にそれぞれの列のTrue、もしくはFalseの数をカウントしてみましょう。
Trueの数を数えるには「(df == True).sum()」とします。
Falseの場合は「(df == False).sum()」です。
print((df == True).sum())
実行結果
column0 8
column1 3
column2 3
column3 6
column4 5
dtype: int64それぞれの行のTrue、もしくはFalseの数をカウント
それぞれの行のTrueの数を数えるには「(df == True).sum(axis=1)」とします。
Falseの場合は「(df == False).sum(axis=1)」です。
print((df == True).sum(axis=1))
実行結果
0 3
1 2
2 2
3 2
4 1
5 4
6 3
7 4
8 2
9 2
dtype: int64特定の列にTrue、もしくはFalseが指定した数だけある行を抽出
最後に特定の列にTrue。もしくはFalseが指定した数だけある行を抽出してみましょう。
「df[(df == True).sum(axis=1) = Trueの数]」、「df[(df == False).sum(axis=1) = Falseの数]」でそれぞれTrueの数、Falseの数を指定した数だけもつ行を取得できます。
また「=」だけでなく「<」(より小さい)、「>」(より大きい)、「<=」(以下)、「>=」(以上)とすることも可能です。
今回はTrueの数が2より大きい行を取得してみます。
df4 = df[(df == True).sum(axis=1) > 2]
df4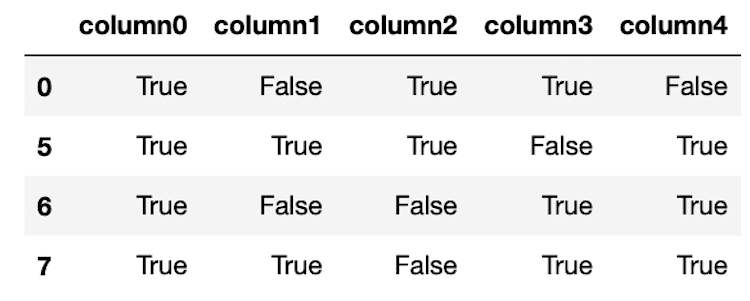
Bool値はあまり使わないので、どうやって抽出したらいいか迷いましたが、これでできるようになりました。
ではでは今回はこんな感じで。
コメント