Pandas
前回、Biopythonで2本の遺伝子やタンパク質の配列間の比較(ペアワイズアライメント)をする方法を紹介しました。
今回はPandasの話題で外れ値を除去したり、置換する方法を紹介します。
それでは始めていきましょう。
外れ値をもったデータを作成するプログラム
まずは外れ値をもったデータが必要なので、そんなデータを作成するプログラムを作ってみました。
import random
import pandas as pd
num = 100
val_range = [10, 20]
outlier_val = 1000
outlier_num = random.randrange(num)
val_list = []
for i in range(num):
if i == outlier_num:
val_list.append([i, outlier_val])
else:
val_list.append([i, random.uniform(val_range[0], val_range[1])])
df = pd.DataFrame(val_list, columns=["x", "y"])
print(df)
print(df.plot.scatter(x="x", y="y"))
実行結果
x y
0 0 13.808903
1 1 19.497257
2 2 17.332677
3 3 18.519145
4 4 14.609500
.. .. ...
95 95 13.393565
96 96 18.504409
97 97 17.751455
98 98 17.368624
99 99 10.373463
[100 rows x 2 columns]
Axes(0.125,0.11;0.775x0.77)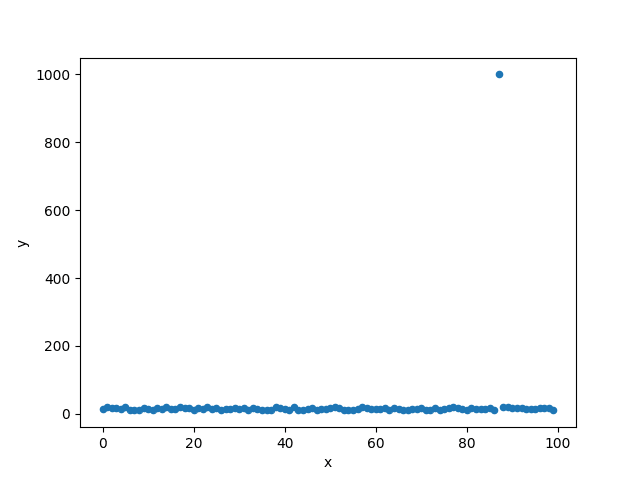
プログラムの概要としては「num = データ数」、「val_range = [値1, 値2]」で外れ値以外の値の範囲、「outlier_val = 外れ値」を設定します。
すると「outlier_num」で外れ値となるデータ番号が設定され、for文で値の設定、最後のPandasのデータフレームに格納しているという感じです。
ちなみに今後、さまざまな値が出てきますが、このプログラムの性質上、外れ値以外の値はランダムなので、毎回違いがあることに注意してください。
データ全体の確認:.describe()
まずデータの中に外れ値があるかどうかを確認します。
先ほどのようにプロットするのも一つの手ですし、データの統計値を見るもの一つの手です。
データの統計値を見るには「データフレーム.describe()」を使います。
import random
import pandas as pd
num = 100
val_range = [10, 20]
outlier_val = 1000
outlier_num = random.randrange(num)
val_list = []
for i in range(num):
if i == outlier_num:
val_list.append([i, outlier_val])
else:
val_list.append([i, random.uniform(val_range[0], val_range[1])])
df = pd.DataFrame(val_list, columns=["x", "y"])
print(df.describe())
実行結果
x y
count 100.000000 100.000000
mean 49.500000 24.594459
std 29.011492 98.573970
min 0.000000 10.179754
25% 24.750000 11.762006
50% 49.500000 14.415880
75% 74.250000 17.636297
max 99.000000 1000.000000countはデータ数、meanは平均値、stdは標準偏差、minは最小値、25%は最小値から数えて25%となる値、50%は最小値から数えて50%となる値が、75%は最小値から数えて75%となる値、maxは最大値です。
ちなみに25%、50%、75%は四分位数と呼ばれ、それぞれ25パーセンタイル(第一四分位数)、50パーセンタイル(第二四分位数)、75パーセンタイル(第三四分位数)とよ呼びます。
データの統計値を始め、概要を見る方法はこちらの記事で紹介していますので、よかったらどうぞ。
この統計値からすると平均値が「24.594459」になっている、また75%が「17.636297」にも関わらず、最大値が「1000」となっているので、外れ値があることが分かります。
外れ値の取得
次に外れ値となる値を取得していきます。
ここでまず使用するのが「.quantile(値)」です。
先ほどの統計値では四分位数(25パーセンタイル、50パーセンタイル、75パーセンタイル)が出てきましたが、「.quantile(値)」を使うと好きなパーセンタイルとなる値を取得できます。
値は0から1の間で指定します。
import random
import pandas as pd
num = 100
val_range = [10, 20]
outlier_val = 1000
outlier_num = random.randrange(num)
val_list = []
for i in range(num):
if i == outlier_num:
val_list.append([i, outlier_val])
else:
val_list.append([i, random.uniform(val_range[0], val_range[1])])
df = pd.DataFrame(val_list, columns=["x", "y"])
quantile9 = df["y"].quantile(0.9)
print(quantile9)
実行結果
18.55377984990959これで90パーセンタイルの値は「18.55377984990959」であると分かりました。
この値を使って、この値以上、つまり外れ値の候補となる値を抽出してみます。
特定の値以上の値をもつデータを抽出するには「df[df[“列”] >= 値]」とします。
import random
import pandas as pd
num = 100
val_range = [10, 20]
outlier_val = 1000
outlier_num = random.randrange(num)
val_list = []
for i in range(num):
if i == outlier_num:
val_list.append([i, outlier_val])
else:
val_list.append([i, random.uniform(val_range[0], val_range[1])])
df = pd.DataFrame(val_list, columns=["x", "y"])
quantile9 = df["y"].quantile(0.9)
df_outlier = df[df["y"] >= quantile9]
print(df_outlier)
実行結果
x y
3 3 19.725857
6 6 19.374549
13 13 19.337465
24 24 19.865614
48 48 19.510822
49 49 18.860829
52 52 19.919411
83 83 19.419082
92 92 1000.000000
97 97 18.785923今回100個のデータを準備していて、90パーセンタイルを指定しているので、残りの10%、つまり10個のデータが抽出できました。
ただここで外れ値の対象となるのは1個ですので、99パーセンタイルにしてみましょう。
import random
import pandas as pd
num = 100
val_range = [10, 20]
outlier_val = 1000
outlier_num = random.randrange(num)
val_list = []
for i in range(num):
if i == outlier_num:
val_list.append([i, outlier_val])
else:
val_list.append([i, random.uniform(val_range[0], val_range[1])])
df = pd.DataFrame(val_list, columns=["x", "y"])
quantile99 = df["y"].quantile(0.99)
df_outlier = df[df["y"] >= quantile99]
print(df_outlier)
print(df_outlier.index.tolist())
実行結果
x y
77 77 1000.0
[77]毎回、データの作成から行なっているので、インデックスが違っていますが、とりあえず外れ値のみを抽出できました。
外れ値のデータを削除する方法
次に外れ値となるデータを削除してみましょう。
先ほどまでに外れ値となる行のインデックスが取得できているので、「データフレーム.drop(インデックス)」で外れ値となるデータの行を削除します。
import random
import pandas as pd
num = 100
val_range = [10, 20]
outlier_val = 1000
outlier_num = random.randrange(num)
val_list = []
for i in range(num):
if i == outlier_num:
val_list.append([i, outlier_val])
else:
val_list.append([i, random.uniform(val_range[0], val_range[1])])
df = pd.DataFrame(val_list, columns=["x", "y"])
quantile99 = df["y"].quantile(0.99)
df_outlier = df[df["y"] >= quantile99]
df = df.drop(df_outlier.index.tolist())
print(df.describe())
x y
count 99.000000 99.000000
mean 49.848485 14.604640
std 28.948005 2.777397
min 0.000000 10.119776
25% 25.500000 12.472751
50% 50.000000 14.006469
75% 74.500000 16.614206
max 99.000000 19.969853データが一つ減ったので、count(データ数)が100から99に一つ減っています。
またmax(最大値)が19.969853となり、飛び抜けて大きな値が無くなったことが分かります。
外れ値を置換する方法
次に外れ値を置換する方法を紹介します。
今回は外れ値以外の平均値に置換することにします。
まず外れ値以外のデータを取得するのに「df_normal = df[df[“x”] < quantile99]」とします。
そして得られたデータの平均値を「average = df_normal[“y”].mean()」で取得する。
そしてその値を使って行と列を指定して値を書き換えるということをします。
ということでこんな感じ。
import random
import pandas as pd
num = 100
val_range = [10, 20]
outlier_val = 1000
outlier_num = random.randrange(num)
val_list = []
for i in range(num):
if i == outlier_num:
val_list.append([i, outlier_val])
else:
val_list.append([i, random.uniform(val_range[0], val_range[1])])
df = pd.DataFrame(val_list, columns=["x", "y"])
quantile99 = df["y"].quantile(0.99)
df_normal = df[df["x"] < quantile99]
average = df_normal["y"].mean()
df_outlier = df[df["y"] >= quantile99]
outlier_num = df_outlier.index.tolist()
for num in outlier_num:
print(df["y"].iloc[num])
df.iloc[num, 1] = average
print(df["y"].iloc[num])
print(df.describe())
実行結果
1000.0
15.034219088827172
x y
count 100.000000 100.000000
mean 49.500000 14.640517
std 29.011492 2.698875
min 0.000000 10.013275
25% 24.750000 12.633835
50% 49.500000 14.086224
75% 74.250000 16.839727
max 99.000000 19.999720「df.iloc[num, 1] = average」が値を書き換えている部分です。
その証拠にその前後で「print(df[“y”].iloc[num])」と値を表示させてみると、置換前は「1000」、置換後は「15.034219088827172」となっています。
ということで値を書き換えることもできました。
ただ今回、データを削除するdropや値を書き換える方法はさらっと紹介しただけなので、次回とその次の記事でそれぞれもう少し詳しく紹介します。
ということで次回はPandasで特定の値をもつデータを削除する方法を紹介します。
ではでは今回はこんな感じで。
コメント