Pandas
前回、PythonのPandasで列方向にデータを追加する方法を紹介しました。
今回はPandasでデータフレーム内の行列のデータ、もしくはデータフレームをリストに変換する方法を紹介します。
まずは今回使用するデータフレームをこんな感じで作成してみました。
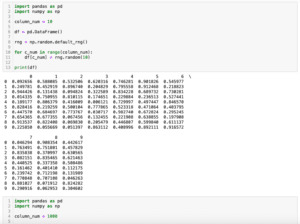
import numpy as np
import pandas as pd
columns_num = 5
index_num =10
rng = np.random.default_rng()
data_dict = {}
for c_num in range(columns_num):
data_dict[c_num] = rng.random(index_num)
df = pd.DataFrame(data_dict)
print(df)
実行結果
0 1 2 3 4
0 0.343731 0.825754 0.930727 0.374056 0.677118
1 0.128025 0.928736 0.336224 0.213639 0.809763
2 0.319691 0.583117 0.844823 0.720393 0.798453
3 0.045584 0.993779 0.304053 0.804798 0.661162
4 0.835423 0.008359 0.068209 0.111025 0.990384
5 0.101579 0.437217 0.085514 0.503745 0.982724
6 0.035009 0.573424 0.702824 0.964584 0.486831
7 0.214964 0.476268 0.015135 0.453965 0.899757
8 0.560960 0.967912 0.682447 0.348058 0.353530
9 0.704706 0.837249 0.489522 0.052787 0.545905NumPyのジェネレータを使ったランダムな値の取得方法はこちらの記事で紹介していますので、良かったらどうぞ。
それでは始めていきましょう。
行、または列のデータをリストに変換する方法
まずは行、または列のデータをリストに変換する方法です。
そのためには行、または列のデータを取得しなければいけないので、取得方法をおさらいします。
列のデータを取得するには「df[列名]」、もしくは「df.loc[:, 列名]」、もしくは「df.iloc[:, 列のインデックス]」です。
「loc」、「iloc」は名前で指定するのかインデックスで指定するのかの違いで、どちらも「行, 列」の順で指定します。
そのため列を指定する場合は、全ての行を示す「:」が必要になります。
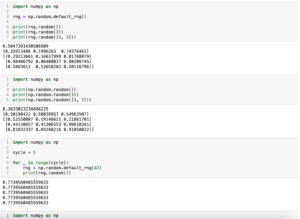
import numpy as np
import pandas as pd
columns_num = 5
index_num =10
rng = np.random.default_rng()
data_dict = {}
for c_num in range(columns_num):
data_dict[c_num] = rng.random(index_num)
df = pd.DataFrame(data_dict)
print(df[1])
print(df.loc[:,1])
print(df.iloc[:,1])
実行結果
0 0.924859
1 0.355486
2 0.665957
3 0.443093
4 0.114464
5 0.213992
6 0.378232
7 0.257210
8 0.066887
9 0.624293
Name: 1, dtype: float64
0 0.924859
1 0.355486
2 0.665957
3 0.443093
4 0.114464
5 0.213992
6 0.378232
7 0.257210
8 0.066887
9 0.624293
Name: 1, dtype: float64
0 0.924859
1 0.355486
2 0.665957
3 0.443093
4 0.114464
5 0.213992
6 0.378232
7 0.257210
8 0.066887
9 0.624293
Name: 1, dtype: float64今回は列名とインデックスが同じなため同じ指定をしているかの様に見えますが、列名を指定しているのかインデックスを指定しているのか異なりますので注意してください。
次に行の指定方法で、行の場合は「loc」、「iloc」で指定します。
またどちらも「行, 列」の順に指定するので、全ての列を指定する場合でも「:」の記述は必要ありません。
import numpy as np
import pandas as pd
columns_num = 5
index_num =10
rng = np.random.default_rng()
data_dict = {}
for c_num in range(columns_num):
data_dict[c_num] = rng.random(index_num)
df = pd.DataFrame(data_dict)
print(df.loc[1])
print(df.iloc[1])
実行結果
0 0.091596
1 0.223889
2 0.278992
3 0.638346
4 0.610433
Name: 1, dtype: float64
0 0.091596
1 0.223889
2 0.278992
3 0.638346
4 0.610433
Name: 1, dtype: float64これで行、列のデータを取得できる様になりましたが、ここからリストに変換していきます。
リストに変換するには「tolist()」を用います。
import numpy as np
import pandas as pd
columns_num = 5
index_num =10
rng = np.random.default_rng()
data_dict = {}
for c_num in range(columns_num):
data_dict[c_num] = rng.random(index_num)
df = pd.DataFrame(data_dict)
print(df.iloc[:,1].tolist())
print(type(df.iloc[:,1].tolist()))
実行結果
[0.43942407486174295, 0.8771415301873634, 0.02957388522208826,
0.9571120251549392, 0.46748167758133785, 0.7979906643549617,
0.4925288655105152, 0.2558565412483216, 0.13534523742945304,
0.14713086604755954]
<class 'list'>import numpy as np
import pandas as pd
columns_num = 5
index_num =10
rng = np.random.default_rng()
data_dict = {}
for c_num in range(columns_num):
data_dict[c_num] = rng.random(index_num)
df = pd.DataFrame(data_dict)
print(df.iloc[1].tolist())
print(type(df.iloc[1].tolist()))
実行結果
[0.5372633392033166, 0.3867517269274322, 0.9177125329230381,
0.978588324302901, 0.39443282561216086]
<class 'list'>またNumPyのndarrayに変換するには「values」を使います。
import numpy as np
import pandas as pd
columns_num = 5
index_num =10
rng = np.random.default_rng()
data_dict = {}
for c_num in range(columns_num):
data_dict[c_num] = rng.random(index_num)
df = pd.DataFrame(data_dict)
print(df.iloc[:,1].values)
print(type(df.iloc[:,1].values))
実行結果
[0.0917893 0.65325175 0.77366836 0.22061223 0.7166594 0.43436658
0.54570977 0.00318846 0.97666076 0.87606926]
<class 'numpy.ndarray'>import numpy as np
import pandas as pd
columns_num = 5
index_num =10
rng = np.random.default_rng()
data_dict = {}
for c_num in range(columns_num):
data_dict[c_num] = rng.random(index_num)
df = pd.DataFrame(data_dict)
print(df.iloc[1].values)
print(type(df.iloc[1].values))
実行結果
[0.56710478 0.32197848 0.13819368 0.94763228 0.95979403]
<class 'numpy.ndarray'>データフレームをリストに変換する方法
次にデータフレームをリストに変換する方法を紹介します。
データフレームそのものをリストに変換したい場合、「tolist()」は使用できません。
import numpy as np
import pandas as pd
columns_num = 5
index_num =10
rng = np.random.default_rng()
data_dict = {}
for c_num in range(columns_num):
data_dict[c_num] = rng.random(index_num)
df = pd.DataFrame(data_dict)
print(df.tolist())
実行結果
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/var/folders/sp/hg7p80kx22s7vct7yb0zl5cm0000gn/T/ipykernel_9444/155335917.py in ?()
11 data_dict[c_num] = rng.random(index_num)
12
13 df = pd.DataFrame(data_dict)
14
---> 15 print(df.tolist())
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/pandas/core/generic.py in ?(self, name)
5985 and name not in self._accessors
5986 and self._info_axis._can_hold_identifiers_and_holds_name(name)
5987 ):
5988 return self[name]
-> 5989 return object.__getattribute__(self, name)
AttributeError: 'DataFrame' object has no attribute 'tolist'なのでこの場合はまず「values」でNumPyのndarrayにしてから、「tolist()」でリストに変換します。
import numpy as np
import pandas as pd
columns_num = 5
index_num =10
rng = np.random.default_rng()
data_dict = {}
for c_num in range(columns_num):
data_dict[c_num] = rng.random(index_num)
df = pd.DataFrame(data_dict)
print(df.values.tolist())
実行結果
[[0.05852210948877512, 0.24151477005320154, 0.13063495501555644,
0.5602935677952059, 0.964490726562927], [0.9691112140470693,
0.2926999936074206, 0.4364222600275778, 0.3251799125125825,
0.422557877964593], [0.4252882862352366, 0.11298654386703011,
0.19525953368269655, 0.5084137438638412, 0.05377913302444581],
[0.3690922805372314, 0.23551782335569227, 0.5177240632655215,
0.01390961554018888, 0.5042079933620565], [0.01106393039440623,
0.07374939170079464, 0.8520858898331931, 0.7368921554065405,
0.5693377029901516], [0.7295033673618672, 0.17838350163980843,
0.5733454030299311, 0.9823683534480646, 0.3936696704111533],
[0.7554784902718905, 0.8503646960976068, 0.5969822113781437,
0.9691218505654735, 0.5977852449057912], [0.9600256223477259,
0.8102336821582697, 0.18010873454083487, 0.41115232414467007,
0.909631088384959], [0.24967412597386163, 0.2548305421603654,
0.0917155083282496, 0.9227244634441589, 0.5678121380442207],
[0.7198645748678513, 0.04899118549740067, 0.5575528199696026,
0.7483127843830311, 0.19012354179409252]]もちろんNumPyのndarrayで問題ない場合は「values」だけでも大丈夫です。
import numpy as np
import pandas as pd
columns_num = 5
index_num =10
rng = np.random.default_rng()
data_dict = {}
for c_num in range(columns_num):
data_dict[c_num] = rng.random(index_num)
df = pd.DataFrame(data_dict)
print(df.values)
実行結果
[[0.36474708 0.91579909 0.2661359 0.69606898 0.39826459]
[0.50532807 0.28258332 0.11945634 0.44421855 0.7014898 ]
[0.03398711 0.88776277 0.28709289 0.76340814 0.1317039 ]
[0.508238 0.83720027 0.54222659 0.48366667 0.93474525]
[0.55726973 0.52218607 0.92646401 0.34656574 0.15969057]
[0.19790845 0.77920173 0.95378627 0.34281471 0.30064298]
[0.5104838 0.57371311 0.44369035 0.11085468 0.44793074]
[0.23222917 0.75086722 0.33467574 0.84794882 0.48604119]
[0.01964661 0.20081193 0.3797879 0.52765067 0.22401209]
[0.6255855 0.55400334 0.17497108 0.53705719 0.05897552]]標準のリストを使うかNumPyのndarrayを使うかはその後の処理で使い分ければいいでしょう。
次回はPythonでパワーポイントを作成できるpython-pptxを紹介します。

ではでは今回はこんな感じで。
コメント