Pandas
前回、Pythonでネスト(複数の階層)された辞書の作成方法を紹介しました。
今回はPandasで「FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. 」の警告への対処法を紹介します。
それでは始めていきましょう。
警告が発生するパターンの把握
まずはどういった時に警告が発生するのか、そのパターンを把握していきます。
例えばこんなパターンです。
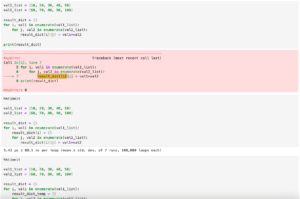
import pandas as pd
column_names = ["A", "B", "C"]
data1 = [[1.0, 2.0, 3.0]]
data2 = [[4, 5, 6], [7, 8, 9]]
df = pd.DataFrame(columns=column_names)
df = pd.concat([df, pd.DataFrame(data1, columns = column_names)])
df = pd.concat([df, pd.DataFrame(data2, columns = column_names)])
print(df)
実行結果
A B C
0 1.0 2.0 3.0
0 4.0 5.0 6.0
1 7.0 8.0 9.0
/var/folders/sp/hg7p80kx22s7vct7yb0zl5cm0000gn/T/ipykernel_34086/
3205198988.py:10: FutureWarning: The behavior of DataFrame
concatenation with empty or all-NA entries is deprecated. In a
future version, this will no longer exclude empty or all-NA columns
when determining the result dtypes. To retain the old behavior,
exclude the relevant entries before the concat operation.
df = pd.concat([df, pd.DataFrame(data1, columns = column_names)])警告が発生するのは2つのデータフレームを「concat」で連結した時です。
その警告の内容としては、
FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation. df = pd.concat([df, pd.DataFrame(data1, columns = column_names)])
そしてChatGPTに翻訳してもらうとこんな感じでした。
FutureWarning: 空のエントリやすべてがNA(欠損値)のエントリを含むDataFrameの連結動作は非推奨となりました。将来のバージョンでは、結果のデータ型(dtypes)を決定する際に、空の列やすべてがNAの列を除外しなくなります。以前の動作を維持するには、連結操作の前に該当するエントリを除外してください。
ということでデータフレームが空だったり、また欠損値だけだったりする場合、それを連結することは非推奨となるということです。
確かに「df = pd.DataFrame(columns=column_names)」で空のデータフレームを作成し、その後2回「concat」でデータをもつデータフレームを連結しています。
ということで対処法を後で紹介しますが、実はこの警告、ほとんど同じでも出ないパターンもあるのです。
それがこんなパターンです。
import pandas as pd
column_names = ["A", "B", "C"]
data1 = [[1, 2, 3]]
data2 = [[4, 5, 6], [7, 8, 9]]
df = pd.DataFrame(columns=column_names)
df = pd.concat([df, pd.DataFrame(data1, columns = column_names)])
df = pd.concat([df, pd.DataFrame(data2, columns = column_names)])
print(df)
実行結果
A B C
0 1 2 3
0 4 5 6
1 7 8 9何が違うかというと最初の例では「data1」に入っている値が「float型」で、今回の例では「int型」です。
なぜかは分かりませんが、空のデータフレームに「int型」の値をもったデータフレームを連結する場合は警告がでないようです。
ちなみに空でないデータフレームに「float型」の値をもったデータフレームを連結する場合も警告はでません。
import pandas as pd
column_names = ["A", "B", "C"]
data1 = [[1, 2, 3]]
data2 = [[4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]
df = pd.DataFrame(columns=column_names)
df = pd.concat([df, pd.DataFrame(data1, columns = column_names)])
df = pd.concat([df, pd.DataFrame(data2, columns = column_names)])
print(df)
実行結果
A B C
0 1 2 3
0 4.0 5.0 6.0
1 7.0 8.0 9.0ということで空でないデータフレームを用意すれば、確かに警告は出なくなるわけです。
対処法
とはいいつつも、空のデータフレームを作って、そこにデータを随時追加していくのはなかなか便利なので止められません。
でどうするかというと、実は問題は空のデータフレームの作り方にあるので、そこを変えていきます。
つまりこの部分です。
df = pd.DataFrame(columns=column_names)空のデータフレームですが、全くの空な訳ではなく、列名を入れています。
これを列名も入れない完全な空のデータフレームにします。
import pandas as pd
column_names = ["A", "B", "C"]
data1 = [[1.0, 2.0, 3.0]]
data2 = [[4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]
df = pd.DataFrame()
df = pd.concat([df, pd.DataFrame(data1, columns = column_names)])
df = pd.concat([df, pd.DataFrame(data2, columns = column_names)])
print(df)
実行結果
A B C
0 1.0 2.0 3.0
0 4.0 5.0 6.0
1 7.0 8.0 9.0するとこのように警告が出ずに処理が完了します。
もちろん値が「int型」であっても問題なく処理が完了します。
import pandas as pd
column_names = ["A", "B", "C"]
data1 = [[1, 2, 3]]
data2 = [[4, 5, 6], [7, 8, 9]]
df = pd.DataFrame()
df = pd.concat([df, pd.DataFrame(data1, columns = column_names)])
df = pd.concat([df, pd.DataFrame(data2, columns = column_names)])
print(df)
実行結果
A B C
0 1 2 3
0 4 5 6
1 7 8 9良かれと思って空のデータフレームに情報を入れてしまうのですが、それは実は必要ないというお話でした。
次回はNumPyのGeneratorを使った場合のリストからランダムに要素を抽出する方法を紹介します。
ではでは今回はこんな感じで。
コメント