SciPy
前回、PythonのSciPyでcurve_fitを用いてカーブフィッティングをする方法を紹介しました。
今回は同じくSciPyのcurve_fitを使って、ピークフィッティングする方法を紹介します。
基本となるグラフをガウス関数を使ってこんな感じで作成してみました。
import numpy as np
import matplotlib.pyplot as plt
import random
x_min = 0
x_max = 100
def gauss(x_list, a=1, m=0, s=1):
y_list = [a * np.exp(-(x - m)**2 / (2*s**2)) for x in x_list]
return y_list
x_list = np.arange(x_min, x_max, 1)
y_list = gauss(x_list, random.random(), random.randint(x_min, x_max+1), random.uniform(0, 10))
fig = plt.figure()
plt.clf()
plt.scatter(x_list, y_list)
plt.show()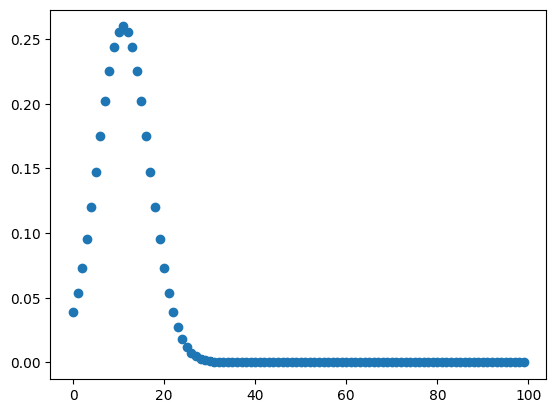
このプログラムでは「x_min」から「x_max」の間でガウス関数を使ってピークを出力してくれます。
ガウス関数の変数を「random.random()」、「random.randint(x_min, x_max+1)」、 「random.uniform(0, 10)」で決めているので、形状はランダムになります。
また前回お話しした通り、curve_fit関数ではXの値のリストを入力して、Yの値をリストで出力する関数である必要があるので、のちのcurve_fit関数でも使用するgauss関数の作り方に注意してください。
def gauss(x_list, a=1, m=0, s=1):
y_list = [a * np.exp(-(x - m)**2 / (2*s**2)) for x in x_list]
return y_listそれでは始めていきましょう。
curve_fitでピークフィッティングする方法
curve_fitでピークフィッティングするには、前回のカーブフィッティングと同様「curve_fit(フィッティングする関数, フィッティングしたいX値のリスト, フィッティングしたいY値のリスト)」とします。
そして実際のフィッティングカーブを取得するには、先ほどのフィッティングする関数のX値のリストはそのままに変数のところに「*popt」を追加します。
from scipy.optimize import curve_fit
popt, pcov = curve_fit(gauss, x_list, y_list)
fig = plt.figure()
plt.clf()
plt.scatter(x_list, y_list)
plt.plot(x_list, gauss(x_list, *popt))
plt.show()
実行結果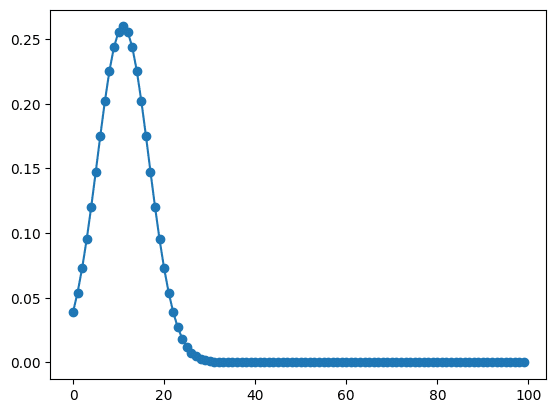
グラフを作成する部分とピークフィッティングの部分をあわせて書くとこんな感じになります。
import numpy as np
import matplotlib.pyplot as plt
import random
from scipy.optimize import curve_fit
x_min = 0
x_max = 100
def gauss(x_list, a=1, m=0, s=1):
y_list = [a * np.exp(-(x - m)**2 / (2*s**2)) for x in x_list]
return y_list
x_list = np.arange(x_min, x_max, 1)
y_list = gauss(x_list, random.random(), random.randint(x_min, x_max+1), random.uniform(0, 10))
popt, pcov = curve_fit(gauss, x_list, y_list)
fig = plt.figure()
plt.clf()
plt.scatter(x_list, y_list)
plt.plot(x_list, gauss(x_list, *popt))
plt.show()find_peaksと合わせてフィッティング精度を上げる方法
ただ実は上記の方法ではうまくフィッティングできずピークが検出されないことも多いです。
import numpy as np
import matplotlib.pyplot as plt
import random
from scipy.optimize import curve_fit
x_min = 0
x_max = 100
def gauss(x_list, a=1, m=0, s=1):
y_list = [a * np.exp(-(x - m)**2 / (2*s**2)) for x in x_list]
return y_list
x_list = np.arange(x_min, x_max, 1)
y_list = gauss(x_list, random.random(), random.randint(x_min, x_max+1), random.uniform(0, 10))
popt, pcov = curve_fit(gauss, x_list, y_list)
fig = plt.figure()
plt.clf()
plt.scatter(x_list, y_list)
plt.plot(x_list, gauss(x_list, *popt))
plt.show()
実行結果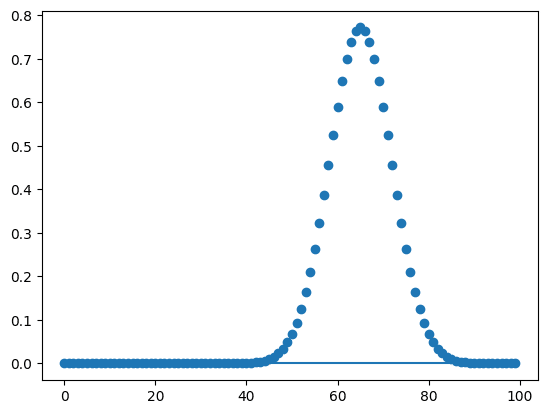
もしフィッティングするピークの変数の値が大体でも分かっているのなら、それを引数に与えると精度が増します。
その際は「curve_fit(フィッティングする関数, Xの値のリスト, Yの値のリスト, p0=変数の初期値)」とします。
import numpy as np
import matplotlib.pyplot as plt
import random
from scipy.optimize import curve_fit
x_min = 0
x_max = 100
def gauss(x_list, a=1, m=0, s=1):
y_list = [a * np.exp(-(x - m)**2 / (2*s**2)) for x in x_list]
return y_list
x_list = np.arange(x_min, x_max, 1)
parameter = [random.random(), random.randint(x_min, x_max+1), random.uniform(0, 10)]
y_list = gauss(x_list, parameter[0], parameter[1], parameter[2])
popt, pcov = curve_fit(gauss, x_list, y_list, p0=parameter)
fig = plt.figure()
plt.clf()
plt.scatter(x_list, y_list)
plt.plot(x_list, gauss(x_list, *popt))
plt.show()
実行結果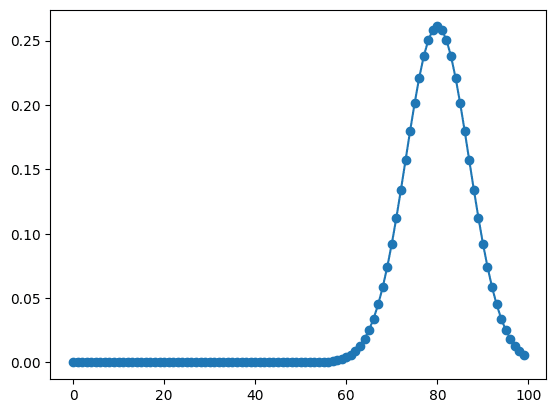
全てが分からなくても、ピーク位置のような重要なパラメータの初期値を与えるだけでも精度はかなり向上します。
import numpy as np
import matplotlib.pyplot as plt
import random
from scipy.optimize import curve_fit
x_min = 0
x_max = 100
def gauss(x_list, a=1, m=0, s=1):
y_list = [a * np.exp(-(x - m)**2 / (2*s**2)) for x in x_list]
return y_list
x_list = np.arange(x_min, x_max, 1)
parameter = [random.random(), random.randint(x_min, x_max+1), random.uniform(0, 10)]
y_list = gauss(x_list, parameter[0], parameter[1], parameter[2])
popt, pcov = curve_fit(gauss, x_list, y_list, p0=([1, parameter[1], 1]))
fig = plt.figure()
plt.clf()
plt.scatter(x_list, y_list)
plt.plot(x_list, gauss(x_list, *popt))
plt.show()
実行結果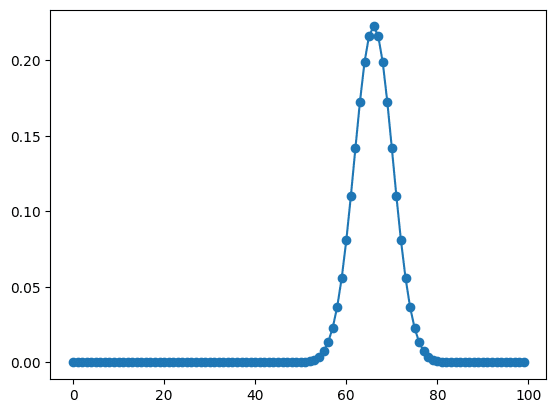
ピーク位置に関しては「SciPy.signal」の「find_peaks()」を使えば簡単に取得できます。
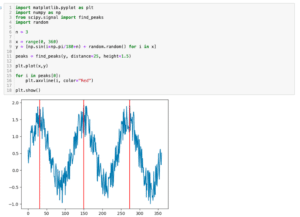
import numpy as np
import matplotlib.pyplot as plt
import random
from scipy.optimize import curve_fit
from scipy.signal import find_peaks
x_min = 0
x_max = 100
def gauss(x_list, a=1, m=0, s=1):
y_list = [a * np.exp(-(x - m)**2 / (2*s**2)) for x in x_list]
return y_list
x_list = np.arange(x_min, x_max, 1)
parameter = [random.random(), random.randint(x_min, x_max+1), random.uniform(0, 10)]
y_list = gauss(x_list, parameter[0], parameter[1], parameter[2])
peaks, _ = find_peaks(y_list)
popt, pcov = curve_fit(gauss, x_list, y_list, p0=([1, x_list[peaks][0], 1]))
fig = plt.figure()
plt.clf()
plt.scatter(x_list, y_list)
plt.plot(x_list, gauss(x_list, *popt))
plt.show()
実行結果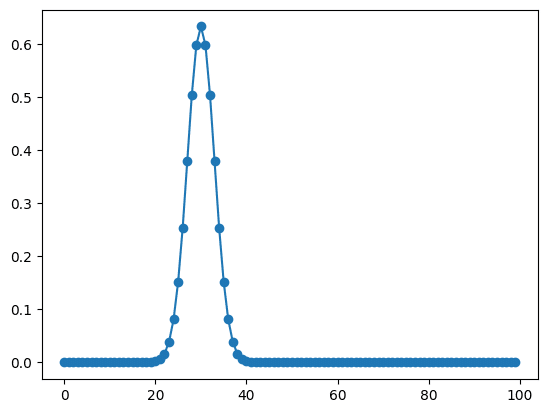
複数のピークをフィッティングする方法
ここまで来たら複数のピークフィッティングも試してみましょう。
まず複数のピークをもつグラフを作成するには、それぞれのピークを作成し、足し合わせることで作成できます。
y_list = np.zeros_like(x_list)
for _ in range(num_peaks):
parameter = [random.random(), random.randint(x_min, x_max+1), random.uniform(0, 10)]
y_list_temp = gauss(x_list, parameter[0], parameter[1], parameter[2])
y_list = y_list + np.array(y_list_temp)また「find_peaks()」で取得したピーク情報を使って、複数のピークにフィッティングさせるには、for関数を使って一つずつピークフィッティングさせていきます。
fit_results = []
for peak in peaks:
popt, pcov = curve_fit(gauss, x_list, y_list, p0=(1, x_list[peak], 1))
fit_results.append(gauss(x_list, *popt))ということで全体としてはこんな感じになりました。
import numpy as np
import matplotlib.pyplot as plt
import random
from scipy.optimize import curve_fit
from scipy.signal import find_peaks
x_min = 0
x_max = 100
num_peaks =3
def gauss(x_list, a=1, m=0, s=1):
y_list = [a * np.exp(-(x - m)**2 / (2*s**2)) for x in x_list]
return y_list
x_list = np.arange(x_min, x_max, 1)
y_list = np.zeros_like(x_list)
for _ in range(num_peaks):
parameter = [random.random(), random.randint(x_min, x_max+1), random.uniform(0, 10)]
y_list_temp = gauss(x_list, parameter[0], parameter[1], parameter[2])
y_list = y_list + np.array(y_list_temp)
peaks, _ = find_peaks(y_list)
fit_results = []
for peak in peaks:
popt, pcov = curve_fit(gauss, x_list, y_list, p0=(1, x_list[peak], 1))
fit_results.append(gauss(x_list, *popt))
fig = plt.figure()
plt.clf()
plt.scatter(x_list, y_list)
for fit in fit_results:
plt.plot(x_list, fit)
plt.show()
実行結果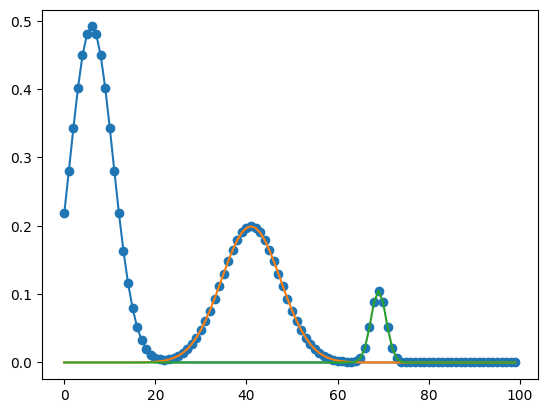
実は複数のピークをもつグラフを作成するプログラム自体もかなり厳し目に作成してしまう(範囲ギリギリでピークをもつグラフを作ってしまったり…)ことと、パラメータのうち2つを固定してしまっていることから、そこまで精度良くピークフィッティングをしてくれなかったりします。
とりあえず今回はここまでとして、またフィッティング精度を上げられる方法が出てきましたら紹介したいと思います。
次回はsubprocessを使ってPython上でターミナルやコマンドプロンプトのコマンドを実行する方法を紹介します。
ではでは今回はこんな感じで。
コメント