Pythonでデータを表示する際の困りごと
Pythonでデータを扱いだすと困ることとして、データの表示形式があります。
例えば、時間と気温をデータ化したとします(値は適当です)。
とりあえず辞書に格納し、表示させた例がこちらです。
dataset = {}
dataset["time"] = ["8:00", "9:00", "10:00", "11:00", "12:00"]
dataset["temp"] = [20.8, 21.5, 22.3, 24.7, 25.2]
print(dataset["time"])
print(dataset["temp"])
実行結果
['8:00', '9:00', '10:00', '11:00', '12:00']
[20.8, 21.5, 22.3, 24.7, 25.2]今回は5つのデータだけなので、どれが何番目のデータか簡単に分かりますが、多くなってくると、どのデータが対応するのか分かりにくくなります。
もし表形式になってくれていれば、分かりやすいと思いませんか?
では表形式にするために、上記の実行結果をエクセルにコピペしてみます。
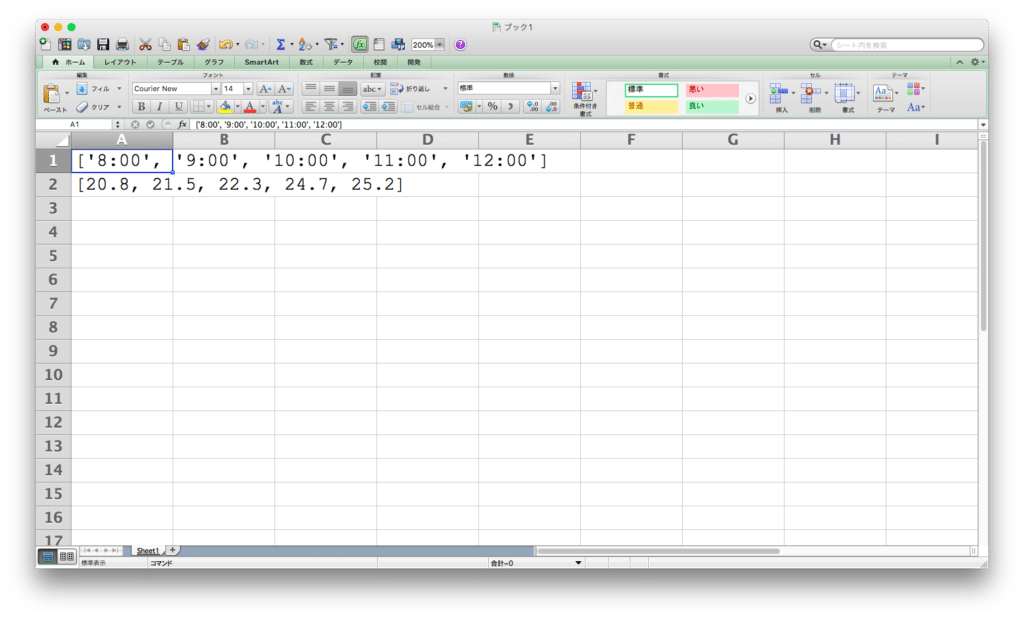
なかなか思ったようには表示してくれず、2行に別れていますが、列に関しては、1つのセルに入ってしまっています。
これでは、1つ1つ手作業でセルに入れていく必要が生じてしまいます。
だったら最初からエクセルを使えばいいわけで。
また見栄えだけの問題ではなく、データをさらに処理しようとした時、Excelで結果を確認したり、処理すると言うこともあるでしょう。
もちろんPythonで全てを終えるのが理想的ですが、Pythonの技術が未熟な時は難しい処理に関しては、慣れているExcelで処理した方が早かったりします。
そんな時、コピペしただけで、エクセルのセルにそれぞれ値が入ってくれた方が、後に処理するのが楽なわけです。
そんな時に知っておくと良い関数がtabulateです。
ちなみにtabulateは日本語で「表にする」だそうです。
そのまんまで、分かりやすいですね。
tabulateをインストール
tabulateはPythonの基本パッケージには入っていないので、別途インストールする必要があります。
インストール方法は前に紹介していますが、今一度紹介します。

まずはAnaconda-navigatorを起動します。

左側の「Environment」をクリック。

矢印のプルダウンメニューを「Not installed」に変更。
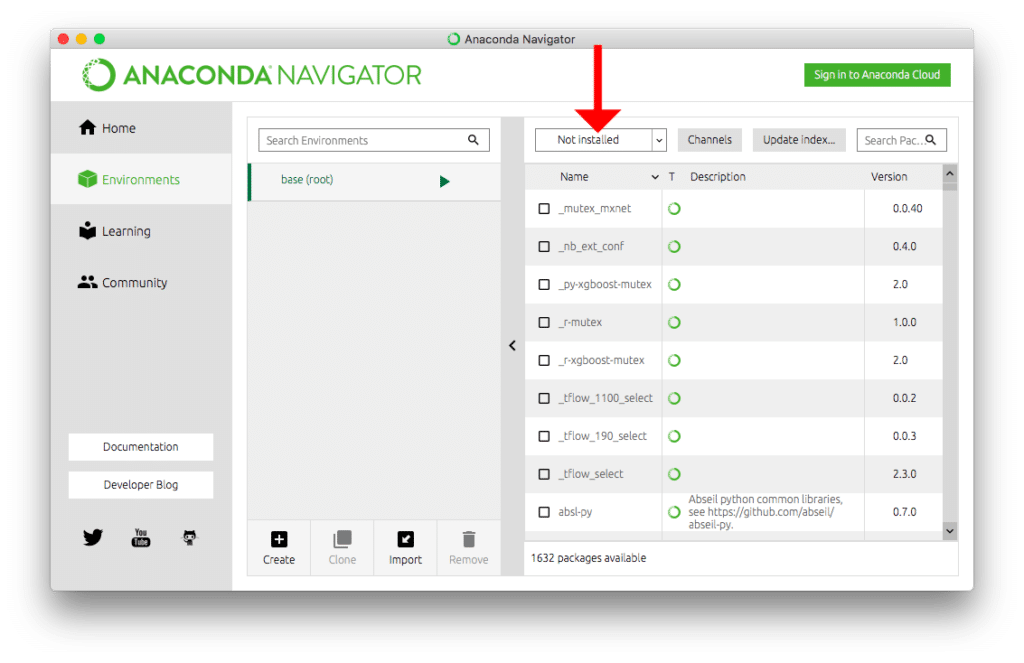
もしくは右上の検索ボックスで「tabulate」を検索し、tabulateのチェックボックスにチェックを入れ、「Apply」をクリック。
するとインストールが開始されるので、しばし待ちます。
画面が更新されたら「Apply」をクリック。
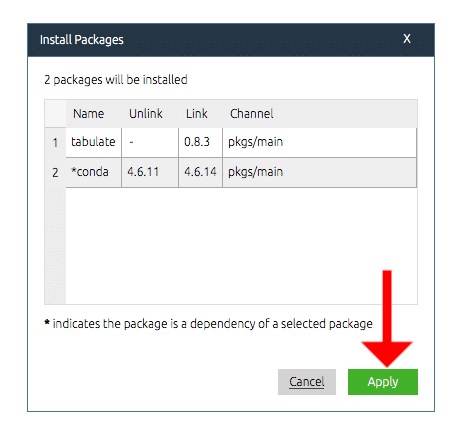
これでインストール完了です。
tabulateの使い方
まずはimportしますが、tabulate以外にもIPython.displayのHTMLとdisplayを使いますので、こちらもimportしておきます。
import tabulate
from IPython.display import HTML, display先ほどのデータを使い、一度出力してみます。
import tabulate
from IPython.display import HTML, display
dataset["time"] = ["8:00", "9:00", "10:00", "11:00", "12:00"]
dataset["temp"] = [20.8, 21.5, 22.3, 24.7, 25.2]
headers = ["time", "temp"]
table = [dataset["time"], dataset["temp"]]
display(HTML(tabulate.tabulate(table, headers, tablefmt="html")))
実行結果
綺麗なテーブル表示にはなっていますが、思ったようにはできていません。
1行目にヘッダー(headers)、2行目に時間(dataset[“time”])、3行目に温度(dataset[“temp”])となってしまっています。
ヘッダーに従って、timeの列には時間を、tempの列には温度を表示してほしいわけです。
そこで使うのが、numpyという数値計算ライブラリです。
こちらはAnacondaを使っている人はすでにインストールされています。
そこでnumpyをimportしますが、これは慣例的にnpと打つだけで使えるようにしてimportします。
import tabulate
from IPython.display import HTML, display
import numpy as npimport X as Yとすると、XというライブラリをYという名前で使うことができます。
つまり今回の場合は、numpyとタイプしなければいけないところを省略形のnpとタイプするだけで、numpyとタイプしたのと同じことになるわけです。
今回はnumpyの中のtransposeという関数を用います。
transposeは行と列を入れ替える関数です。
ちょっとやってみましょう。
import numpy as np
dataset["time"] = ["8:00", "9:00", "10:00", "11:00", "12:00"]
dataset["temp"] = [20.8, 21.5, 22.3, 24.7, 25.2]
table1 = [dataset["time"], dataset["temp"]]
table2 = np.array(table1).transpose()
print(table1)
print(table2)
実行結果
[['8:00', '9:00', '10:00', '11:00', '12:00'], [20.8, 21.5, 22.3, 24.7, 25.2]]
[['8:00' '20.8']
['9:00' '21.5']
['10:00' '22.3']
['11:00' '24.7']
['12:00' '25.2']]table1ではdataset[“time”]とdataset[“temp”]を格納したので、インデックス0に時間が、インデックス1に温度が格納され、2次元配列が生成されています。
table2では行と列を入れ替えたので、時間の1つ目と温度の1つ目がインデックス0に、時間の2つ目と温度の2つ目がインデックス1へと時間と温度の組み合わせの2次元配列へと変換されています。
ちなみにnp.array()にリストを入れることによって、通常のリストからnumpyのリストへと変換しています。
transposeのようなnumpyライブラリの関数を使う際には、このように変換する必要があるので注意してください。
そのうちにnumpyに関しても解説をしますが、とりあえず今回はnp.array()が必要だというくらいに留めておいてください。
それではこの変換したデータを用いて、テーブル表示してみましょう。
import tabulate
from IPython.display import HTML, display
import numpy as np
dataset["time"] = ["8:00", "9:00", "10:00", "11:00", "12:00"]
dataset["temp"] = [20.8, 21.5, 22.3, 24.7, 25.2]
headers = ["time", "temp"]
table = [dataset["time"], dataset["temp"]]
display(HTML(tabulate.tabulate(np.array(table).transpose(), headers, tablefmt="html")))
実行結果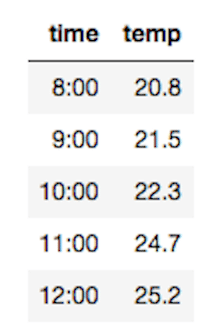
timeの列に時間が、tempの列に温度が表示されました。
ではこれをExcelにコピペしてみましょう。
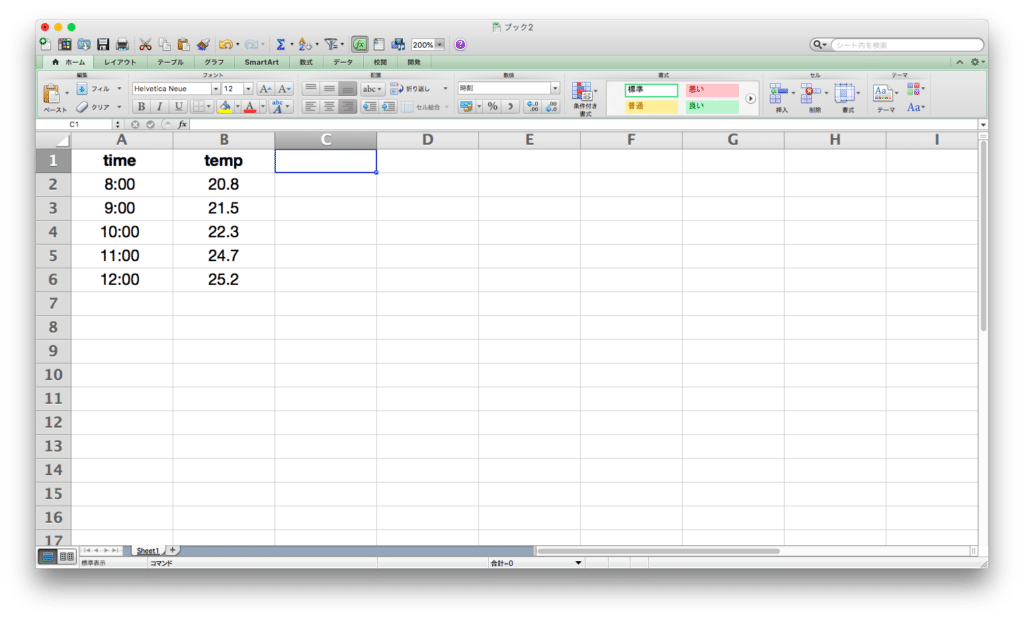
ちゃんとそれぞれの値が別々のセルにコピペできました。
ここで先ほどのコマンドの解説をしてみます。
ちょっとややこしいので、それぞれ分解してみました。
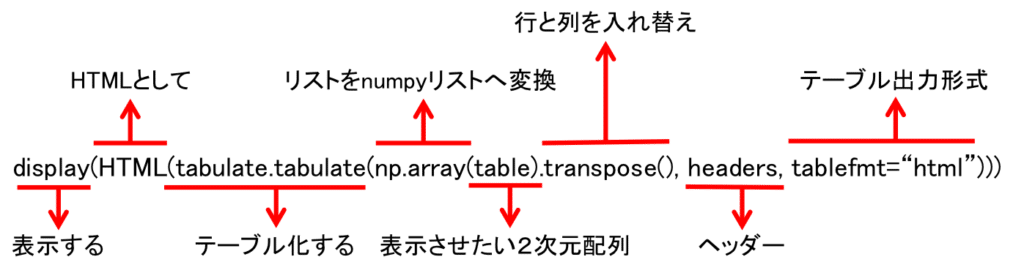
長くて分かりにくいコマンドでも、1つずつ分解することで理解が進みますので、今後、こういったコマンドは1つずつどういう意味か考えてみることをお勧めします。
これで綺麗なテーブル表示ができ、Excelとの連携が簡単になりました。
次回は連番を作る関数、range関数に関して解説をしていきます。

ということで今回はこんな感じで。
コメント