BeautifulSoup
前回、Webページ解析ライブラリBeautifulSoupのインストールとリンクのテキスト、URLの取得を行いました。
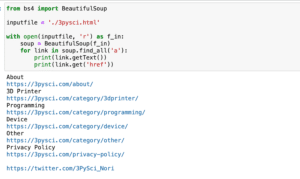
今回は特定のブログ記事を解析して、見出しを取得してみましょう。
今回用いる記事はこちらです。
この記事を書いている時にちょうどアップされた記事で、見出しがh1からh4まで使われており、バランスが良かったのでこちらの記事を選択しました。
それでは始めていきましょう。
ページの保存
まずはページの保存を行いましょう。
前々回、こちらの記事で解説したurllibを使ってローカル(PC上)に保存します。
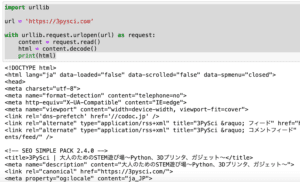
プログラムはこんな感じです。
import urllib
url = 'https://3pysci.com/dx-1/'
html_out = './dx-1.html'
urllib.request.urlretrieve(url, html_out)これで記事をhtmlファイル(dx-1.html)としてローカルに保存することができました。
見出しの説明
次に見出しを取得していきたいのですが、htmlで使用できる見出しはh1からh6までの6つの見出しがあります。
全部表示してみるとこんな感じです。

もちろんそれぞれのウェブサイトでデザインの設定が異なります。
h1はページのタイトルなど基本的に1つです。
h2以降はh2の中にh3、h3の中にh4と段階的に下位の見出しが入っていく構成になるのが通常です。
こうすることでGoogleなどのクローラー(ウェブサイトの情報を収集するロボット)が、ウェブサイトの構成を理解しやすいようになっています。
ただし人によっては、文字のスタイルの違いだけだと勘違いして、h3の中にh2が入っているなど、見出しとしての活用をしていないこともあるので注意です。
何はともあれ今回取得するタグはこの「h1」から「h6」になります。
見出しを取得するプログラム
それでは見出しを取得するプログラムを見ていきましょう。
from bs4 import BeautifulSoup
inputfile = './dx-1.html'
heading_list = ['h1', 'h2', 'h3', 'h4', 'h5', 'h6']
with open(inputfile, 'r') as f_in:
soup = BeautifulSoup(f_in)
for heading in heading_list:
print(f'-----{heading}-----')
for contents in soup.find_all(heading):
print(contents.getText())BeautifulSoupをインポートして(from bs4 import BeautifulSoup)、インプットするファイルの定義をしています(inputfile = ‘./dx-1.html’)。
また見出し(heading)は先ほど解説したh1からh6までなので、それをリストに格納しています(heading_list = [‘h1’, ‘h2’, ‘h3’, ‘h4’, ‘h5’, ‘h6’])。
そして前回同様、ファイルとして読み込んだ後(with open(inputfile, ‘r’) as f_in:)、BeautifulSoupで解析をします(soup = BeautifulSoup(f_in))。
for文を使って、見出しのタグを一つずつ取得し(for heading in heading_list:)、「.find_all」を使って見出しのタグと一致する部分を取得し(for contents in soup.find_all(heading):)、そのテキストを取得し、表示しています(print(contents.getText()))。
これを実行するとこうなりました。
-----h1-----
Pythonで始めるなんちゃってDX その1:表の項目を抽出するプログラム
-----h2-----
DX(デジタルトランスフォーメーション)
このプログラムでできること
使い方
プログラムの解説
注意すべき点
コメント
-----h3-----
プログラム全体
ライブラリのインポート
filenameGet関数
fileProcess関数
main関数
コメントする コメントをキャンセル
-----h4-----
fileProcess関数 前半:データの抽出と保存
fileProcess関数 後半:項目ファイルの作成
-----h5-----
-----h6-----確かにそれぞれ見出しが取得できました。
解析したいページの見出しを作る場合に活用できそうです。
知らなかったこと
今回、自分の記事の見出しの解析をしてみて知らなかったことが一点ありました。
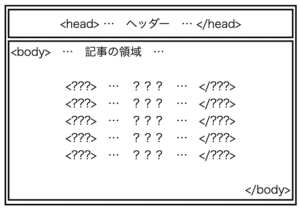
それは「コメント」にh2タグが、「コメントする コメントをキャンセル」にh3タグが使われていることです。
画面でいうとこの部分になります。

この部分は他の見出しのように手動で設定しているわけではなく、使っているWordPressのテンプレート(SWELL)で設定されているためこのように見出しタグが使われていることを全然知りませんでした。
ということで自分のプログでも知らないことはたくさんあると思うので、このように解析してみるのも新しい発見があって面白いことだなぁと思いました。
次回は記事全文を取得する方法を試してみたいと思います。
ではでは今回はこんな感じで。
コメント