Pandas
前回、Pythonのpickleライブラリを使ってオブジェクトをそのまま保存・読み込みする方法を紹介しました。
今回はPandasで列名が重複している列を取り除く方法を紹介します。
それでは始めていきましょう。
どういう時に列名が重複するのか?
まず列名が重複するのはどんな時か見てみましょう。
例えばデータフレームを一つ作って、そこに同じ列名で別のデータを追加した場合、列が書き換えられるだけで同じ列名の列が2つ存在するということにはなりません。
import pandas as pd
a = [1, 2, 3, 4, 5]
b = [2, 4, 6, 8, 10]
df = pd.DataFrame()
df["a"] = a
print(df)
df["a"] = b
print(df)
実行結果
a
0 1
1 2
2 3
3 4
4 5
a
0 2
1 4
2 6
3 8
4 10ちなみに2回目に追加する場合は同じデータ数でないとエラーとなります。
import pandas as pd
a = [1, 2, 3, 4, 5]
b = [2, 4, 6, 8, 10, 12]
df = pd.DataFrame()
df["a"] = a
print(df)
df["a"] = b
print(df)
実行結果
a
0 1
1 2
2 3
3 4
4 5
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[4], line 11
7 df["a"] = a
9 print(df)
---> 11 df["a"] = b
13 print(df)
(中略)
ValueError: Length of values (6) does not match length of index (5)列名が重複した列が発生するのは、例えばconcatなどを使い、2つのデータフレームを結合させた場合です。
import pandas as pd
a = [1, 2, 3, 4, 5]
b = [2, 4, 6, 8, 10]
c = [3, 6, 9, 12, 15]
d = [4, 8, 12, 16, 20]
e = [5, 10, 15, 20, 25]
df1 = pd.DataFrame({"a":a, "b":b, "c":c})
df2 = pd.DataFrame({"a":a, "d":d, "e":e})
df = pd.concat([df1, df2], axis=1)
print(df)
実行結果
a b c a d e
0 1 2 3 1 4 5
1 2 4 6 2 8 10
2 3 6 9 3 12 15
3 4 8 12 4 16 20
4 5 10 15 5 20 25そして今回はこの重複した2つの列の1つを削除し、1つにするにはどうしたらいいかという問題です。
ちなみに重複した列名でデータを取得すると、両方の列が取得されます。
import pandas as pd
a = [1, 2, 3, 4, 5]
b = [2, 4, 6, 8, 10]
c = [3, 6, 9, 12, 15]
d = [4, 8, 12, 16, 20]
e = [5, 10, 15, 20, 25]
df1 = pd.DataFrame({"a":a, "b":b, "c":c})
df2 = pd.DataFrame({"a":a, "d":d, "e":e})
df = pd.concat([df1, df2], axis=1)
print(df["a"])
実行結果
a a
0 1 1
1 2 2
2 3 3
3 4 4
4 5 5列名が重複した列を取り除く方法
列名が重複した列を取り除くには「df.loc[:, ~df.columns.duplicated()]」を使います。
import pandas as pd
a = [1, 2, 3, 4, 5]
b = [2, 4, 6, 8, 10]
c = [3, 6, 9, 12, 15]
d = [4, 8, 12, 16, 20]
e = [5, 10, 15, 20, 25]
df1 = pd.DataFrame({"a":a, "b":b, "c":c})
df2 = pd.DataFrame({"a":a, "d":d, "e":e})
df = pd.concat([df1, df2], axis=1)
df = df.loc[:,~df.columns.duplicated()]
print(df)
実行結果
a b c d e
0 1 2 3 4 5
1 2 4 6 8 10
2 3 6 9 12 15
3 4 8 12 16 20
4 5 10 15 20 25「df.loc[行, 列]」で特定の行、特定の列のデータが取得できます。
ちなみに行や列に「:」を使うと、全ての行、または全ての列になります。
そのため先ほどの「df.loc[:,~df.columns.duplicated()]」では、行は全ての行を取得しています。
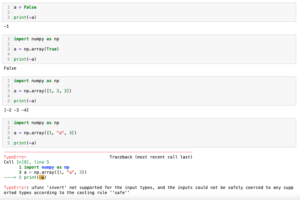
そして列としては「~df.columns.duplicated()」を指定していますが、「~(チルダ)」のない「df.columns.duplicated()」では、各列が重複しているかしていないかをbool値(True/False)で取得できます。
そして「~(チルダ)」をつけるとその反対の結果が得られます。
この「~(チルダ)」の働きに関しては次回解説しますので、今回はそんなもんだと思ってもらえれば助かります。
ということでこんな感じ。
import pandas as pd
a = [1, 2, 3, 4, 5]
b = [2, 4, 6, 8, 10]
c = [3, 6, 9, 12, 15]
d = [4, 8, 12, 16, 20]
e = [5, 10, 15, 20, 25]
df1 = pd.DataFrame({"a":a, "b":b, "c":c})
df2 = pd.DataFrame({"a":a, "d":d, "e":e})
df = pd.concat([df1, df2], axis=1)
print(df.columns.duplicated())
print(~df.columns.duplicated())
実行結果
[False False False True False False]
[ True True True False True True]そして「df.loc[:,~df.columns.duplicated()]」ではこの結果が「True」になったところだけ取得されるため、重複していない列のみが取得されるというわけです。
ロガーで取ったデータなどを複数統合すると、どうしても時間の列など共通の列が複数存在してしまうので、そんな時に重複を削除するというのが非常に有用です。
次回は今回出てきた「~(チルダ)」が一体どういうものなのか色々と試してみたいと思います。
ではでは今回はこんな感じで。
コメント