C言語
前回、C言語での変数の定義とprintf関数を学んでみました。
今回は前回の中で少しハマった文字と文字列に関していろいろ試していこうと思います。
前回、printf関数でHello World!を出力したプログラムはこうでした。
#include <stdio.h>
int main(void)
{
printf("Hello World!");
}
実行結果
Hello World!そしてPython使いとしてやりそうなミスはこんな感じです。
#include <stdio.h>
int main(void)
{
printf('Hello World!');
}
実行結果
string2.c:5:12: warning: multi-character character constant [-Wmultichar]
printf('Hello World!');
^
(中略)
string2.c:5:12: note: treat the string as an argument to avoid this
printf('Hello World!');
^
"%s",
4 warnings generated.どこが違うか分かりますか?
ダブルクォーテーションとシングルクォーテーション
実は「Hello World!」を括っているのが「”(ダブルクォーテーション)」か「’(シングルクォーテーション)」かの違いです。
Pythonではダブルクォーテーションもシングルクォーテーションもほぼ同じものとして使うことができました。
(特定の条件下では異なる意味をもつ場合もありますが)
C言語では明確に異なり、シングルクォーテーションで囲まれたものは文字(一文字だけの文字 例 ‘x’)、ダブルクォーテーションで囲まれたものは文字列(例 “xyz”)と分けられます。
つまり「Hello World!」は「文字列」であるため、シングルクォーテーションは使えないというわけです。
そしてもう一つprintf関数自体としてもシングルクォーテーションはint型として入力するためのもののようで、エラーが出力されます。
#include <stdio.h>
int main(void)
{
printf('x');
}
実行結果
printf8.c:5:12: warning: incompatible integer to pointer conversion passing 'int' to parameter of type 'const char *' [-Wint-conversion]
printf('a');
^~~
(以下略)ではどういう時にシングルクォーテーションとダブルクォーテーションを使い分けるのか?
それは変数の定義の時です。
#include <stdio.h>
int main(void)
{
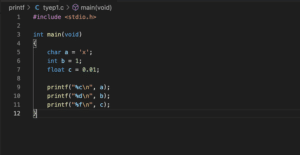
char a = 'x';
char b[] = "xyz";
char c[] = "x";
printf("%c\n",a);
printf("%s\n",b);
printf("%s\n",c);
}
実行結果
x
xyz
x「char a = ‘x’;」では文字なので、シングルクォーテーションを使うことができます。
次に「char b[] = “xyz”;」では文字列なので、シングルクォーテーションは使えずに、ダブルクォーテーションを使う必要があります。
「b」の後ろの角括弧[ ]がありますが、これは次の項目で説明します。
最後に「char c[] = “x”;」は一文字なのですが、文字列として扱っているため、ダブルクォーテーションを使っています。
そのためそれぞれの変換指定子は「%c(文字)」、「%s(文字列)」、「%s(文字列)」となっているわけです。
文字と文字列の変数を定義する方法
それでは先ほどのプログラムで角括弧[ ]の意味とは何か確認していきましょう。
文字の時には必要なくて、文字”列”の場合には必要、つまりこの二つの違いに角括弧が必要かどうかの意味がありそうです。
その違いとは文字の数にあります。
文字では必ず1個の定数、文字列ではその文字列依存で不定数です。
つまり角括弧は本来ならば数字が入るものなのです。
ということで変数を準備した後に文字列を格納してみましょう。
#include <stdio.h>
int main(void)
{
char a[4];
a[0] = 'x';
a[1] = 'y';
a[2] = 'z';
a[3] = '\0';
printf("%s", a);
}
実行結果
xyzついでにPythonでも何となく書いてみます。
a = ''
a = 'xyz'
print(a)
実行結果
xyz全然違いますね。
C言語では最初に「変数名[文字数+1]」で格納する場所を確保します。
そして文字列そのものを一度に格納できないため、文字を一つずつ格納していきます。
最後に「文字列はここまで」という印(終端文字、NULL文字と呼ばれるらしい)で、これも一文字分に含まれるため、最初に設定する文字の数が「文字数+1」となるわけです。
Pythonではとりあえず「a = ”」で文字列(文字も可)の変数を定義し、そこに「xyz」を代入するだけで「a = ‘xyz’」という文字列が入った変数を作ることができます。
文字の個数と代入する数
それでは文字列の文字の数(つまり角括弧の中の数字)は、過不足なく入れなければいけないのでしょうか?
例えば少なく入れて表示させてみます。
#include <stdio.h>
int main(void)
{
char a[4];
a[0] = 'x';
a[1] = 'y';
a[2] = '\0';
printf("%s", a);
}
実行結果
xy少ないことに関しては問題なく表示することができました。
次に指定した数より多い文字数を入れてみましょう。
#include <stdio.h>
int main(void)
{
char a[4];
a[0] = 'x';
a[1] = 'y';
a[2] = 'z';
a[3] = 'X';
a[4] = '\0';
printf("%s", a);
}
実行結果
string7.c:11:5: warning: array index 4 is past the end of the array (which contains 4 elements) [-Warray-bounds]
a[4] = '\0';
^ ~
string7.c:5:5: note: array 'a' declared here
char a[4];
^
1 warning generated.
xyzX5つ目の文字を入れようとしたところでエラーになりました。
つまり指定した数より少ないのは問題ないけども、多いのはエラーとなるということです。
終端文字や文字数を入力せず文字列を変数に代入する方法
実は終端文字や文字数を入力せずに文字列を変数に代入する方法があります。
それはこのように変数の定義時に文字列も定義することです。
#include <stdio.h>
int main(void)
{
char a[] = "xyz";
printf("%s", a);
}
実行結果
xyzこの場合は自動で終端文字を追加し、文字数を設定してくれます。
ちなみに終端文字を含めた文字数を定義しても大丈夫です。
#include <stdio.h>
int main(void)
{
char a[4] = "xyz";
printf("%s", a);
}
実行結果
xyzまた話はずれますが、終端文字、文字数の両方を追加してもエラーにならず出力してくれます。
#include <stdio.h>
int main(void)
{
char a[4] = "xyz\0";
printf("%s", a);
}
実行結果
xyzこの文字列の扱いに関しては、思ったよりもPythonとC言語との隔たりが大きいのを感じました。
そこら辺は慣れていくしかないと思うので、どんどんC言語を学んでいきましょう。
次回はC言語での四則演算を勉強していきましょう。
ではでは今回はこんな感じで。
コメント