Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」の「タイタニック号乗客の生存予測」の訓練用データセットをLinearSVCモデルを使って機械学習してみました。
今回は訓練用データセットで機械学習させたモデルを使って、テスト用データセットで乗客の生存予測データを作成していきましょう。
ということでまずは前回のおさらいで、訓練用データセットを使って機械学習モデルを作成していきます。
<セル1>
import pandas as pd
train = pd.read_csv("train.csv")
train
実行結果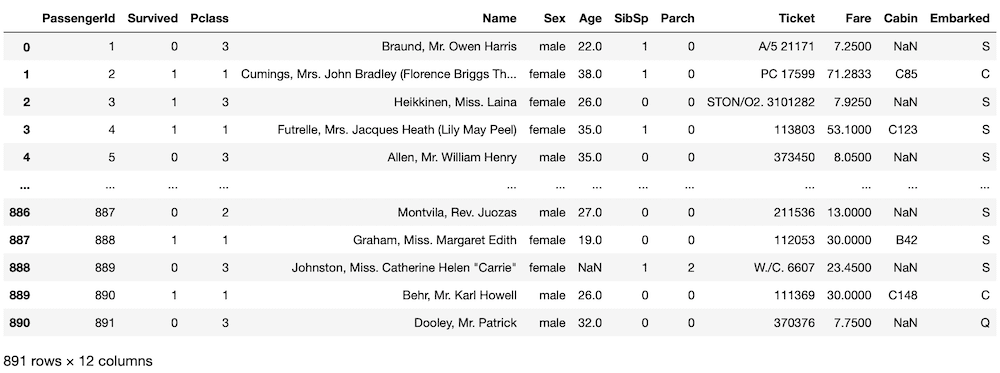
次に「Sex(性別)」の項目を「male」、「female」から「0」、「1」に変換します。
<セル2>
train.loc[train["Sex"] == "male", "Sex"] = 0
train.loc[train["Sex"] == "female", "Sex"] = 1
train
実行結果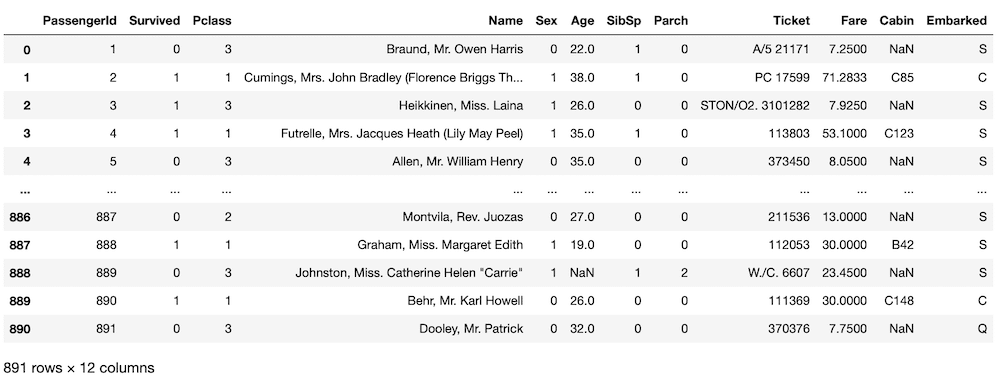
そしてLinearSVCモデルを使って機械学習させます。
今回使用する特徴量としては「Pclass」、「Sex」、「SibSp」、「Parch」、「Fare」の6種類です。
<セル3>
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x = train.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare"]]
y = train["Survived"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC(max_iter=10000000)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.8100558659217877テスト用データセットを使って生存予想をさせる
次にテスト用データセットを読み込んで、生存予想データを作成していきます。
<セル4>
test = pd.read_csv("test.csv")
test
実行結果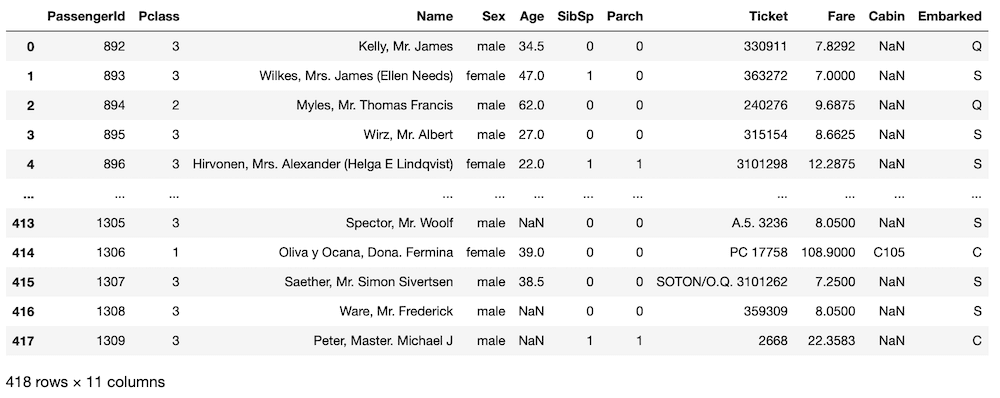
テスト用データセットも「Sex(性別)」の項目を「male」、「female」から「0」、「1」に変更していきます。
<セル5>
test.loc[test["Sex"] == "male", "Sex"] = 0
test.loc[test["Sex"] == "female", "Sex"] = 1
test
実行結果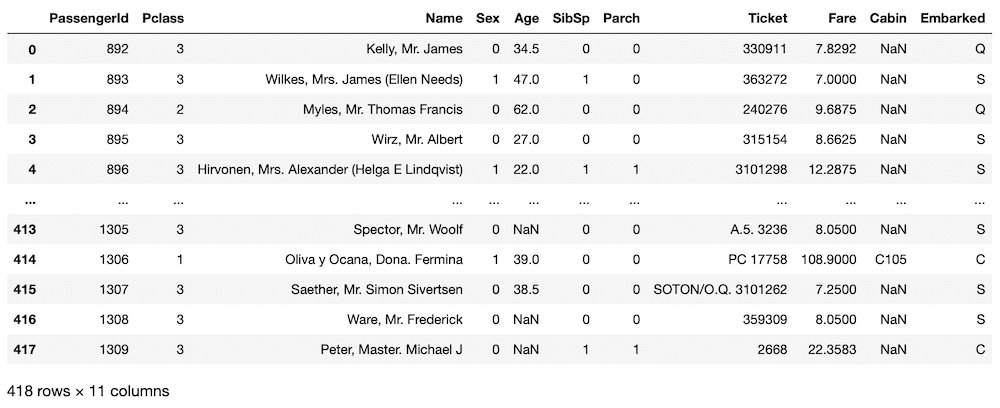
次に使用する特徴量を変数x_testsetに格納した後、先ほど作成した機械学習モデルに入力し、予想させます。
<セル6>
x_testset = test.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare"]]
pred = model.predict(x_testset)
print(pred)
実行結果
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-7-a9e3ff8dae75> in <module>
1 x_testset = test.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare"]]
2
----> 3 pred = model.predict(x_testset)
4 print(pred)
(中略)
/opt/anaconda3/lib/python3.7/site-packages/sklearn/utils/validation.py in _assert_all_finite(X, allow_nan, msg_dtype)
98 msg_err.format
99 (type_err,
--> 100 msg_dtype if msg_dtype is not None else X.dtype)
101 )
102 # for object dtype data, we only check for NaNs (GH-13254)
ValueError: Input contains NaN, infinity or a value too large for dtype('float64').何とエラーが出てしまいました。
どうやらテスト用データセット中の使用した特徴量のどれかに欠損値(NaN)が紛れ込んでいるようです。
これは確認していなかった自分が悪いですね…
ということでテスト用データセットのそれぞれの特徴量における欠損値の個数を確認します。
<セル7>
test.isnull().sum()
実行結果
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64どうやら「Fare」のデータで1つ欠損値があるようです。
ということで「Fare」を除いて再度試してみましょう。
<セル8>
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x = train.loc[:, ["Pclass", "Sex", "SibSp", "Parch"]]
y = train["Survived"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC(max_iter=10000000)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.7932960893854749そして再度予想させてみます。
<セル9>
x_testset = test.loc[:, ["Pclass", "Sex", "SibSp", "Parch"]]
pred = model.predict(x_testset)
print(pred)
実行結果
[0 1 0 0 1 0 1 0 1 0 0 0 1 0 1 1 0 0 1 1 0 0 1 0 1 0 1 0 0 0 0 0 1 1 0 0 1
1 0 0 0 0 0 1 1 0 0 0 1 1 0 0 1 1 0 0 0 0 0 1 0 0 0 1 0 1 1 0 0 1 1 0 1 0
1 0 0 1 0 1 0 0 0 0 0 0 1 1 1 0 1 0 1 0 0 0 1 0 1 0 1 0 0 0 1 0 0 0 0 0 0
1 1 1 1 0 0 1 0 1 1 0 1 0 0 1 0 1 0 0 0 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0
0 0 1 0 0 1 0 0 1 1 0 1 1 0 1 0 0 1 0 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 1 0 1
0 1 0 0 0 0 0 0 0 0 0 0 1 0 1 1 0 0 1 0 0 1 0 1 0 0 0 0 1 0 0 1 0 1 0 1 0
1 0 1 1 0 1 0 0 0 1 0 0 0 0 0 0 1 1 1 1 0 0 0 0 1 0 1 1 1 0 0 0 0 0 0 0 1
0 0 0 1 1 0 0 0 0 1 0 0 0 1 1 0 1 0 0 0 0 1 0 1 1 1 0 0 0 0 0 0 1 0 0 0 0
1 0 0 0 0 0 0 0 1 1 0 0 0 1 0 0 0 1 1 1 0 0 0 0 0 0 0 0 1 0 1 0 0 0 1 0 0
1 0 0 0 0 0 0 0 0 0 1 0 1 0 1 0 1 1 0 0 0 1 0 1 0 0 1 0 1 1 0 1 1 0 1 1 0
0 1 0 0 1 1 1 0 0 0 0 0 1 1 0 1 0 0 0 0 0 1 0 0 0 1 0 1 0 0 1 0 1 0 0 0 0
0 1 1 1 1 1 0 1 0 0 0]今度は無事予想できました。
予想データを提出用に整形する
ただこのままではKaggleに予想データを提出することができません。
提出するために予想データを整形していきましょう。
最終的な形としては、「gender_submission.csv」にある形式です。
つまり1列目に「PassengerId」、2列目に「Survived」があるこの形。

ということで、まずはPassePandasのデータフレームに入れ込んでいきます。
<セル10>
submit_data = pd.DataFrame()
submit_data["PassengerId"] = test["PassengerId"]
submit_data["Survived"] = pred
submit_data
実行結果
これでできたかなと思ったのですが、実はこれでは間違った形式のため、ファイルのアップロードに失敗します。
次回ファイルのアップロードに失敗した場合どうなるのかお見せするため、とりあえずこのまま提出用のcsvファイルとして出力しておきます。
<セル11>
submit_data.to_csv("./submit_data_fail.csv")
実行結果実行結果は何も表示されませんが、ファイルが作成されるので、開いて形式を確認してみましょう。

先ほど確認した「gender_submission.csv」と違い、最初の列にインデックス番号が付加されてしまっています。
これだけでデータは受け付けてもらえません。
ということで「PassengerId」のところをインデックス番号として使うよう変更して、csvファイルに出力します。
<セル12>
submit_data_fixed = submit_data.set_index("PassengerId")
submit_data_fixed.to_csv("./submit_data_success.csv")
実行結果こちらも実行結果は何も表示されず、ファイルが作成されます。
ファイルを開いて形式を確認してみましょう。

今回はインデックス番号が付加されずに出力されました。
これで提出用予想データの作成が完了しました。
次回は作成した予想データ(失敗用も成功用も)を提出してみましょう。
どんな順位になるのか楽しみですが、今回はこんな感じで。
コメント