NumPy
前回、NumPyで配列を連結する方法(np.hstack、np.vstack、np.dstack、np.concatenate、np.block)を紹介しました。
今回はNumPyでヒストグラムのビンを任意に作成する方法(np.ditigize)を紹介します。
それでは始めていきましょう。
np.digitizeの基本
np.digitizeを使うには、ヒストグラムのビンに分類するためのデータ、そしてどの様に分類するかを指定するビンが必要になります。
今回、この様に準備しました。
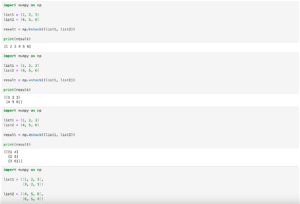
data = [-0.2, 0.3, 2, 2.7, 3.2, 4.8, 8.0]
bins = [0, 1, 2, 3, 4, 5, 10]np.digitizeの使い方としては「np.digitize(データ, ビン)」です。
import numpy as np
data = [-0.2, 0.3, 2, 2.7, 3.2, 4.8, 8.0]
bins = [0, 1, 2, 3, 4, 5, 10]
index_list = np.digitize(data, bins)
print(index_list)
実行結果
[0 1 3 3 4 5 6]返り値はビンのリストに対応したインデックスです。
つまり「-0.2」の場合はビンの「0」より下の値なのでインデックスとして「0」が返ってきます。
「0.3」はビンの「0」と「1」の間なので、インデックスとして「1」、同様に「2.7」は「3」、「3.2]は「4」、 「4.8]は「5」、 「8.0]は「10」となります。
ちょうどビンの値と被る「2」に関してはビンの値の「2」から「3」の間と判定され、インデックスは「3」となります。
ちなみに返ってくる値はインデックスですので、どのビンに分類されるか値を取得したい場合はリストからインデックスを使って値を取得する必要があります。
import numpy as np
data = [-0.2, 0.3, 2, 2.7, 3.2, 4.8, 8.0]
bins = [0, 1, 2, 3, 4, 5, 10]
index_list = np.digitize(data, bins)
print(index_list)
print(np.array(bins)[index_list])
実行結果
[0 1 3 3 4 5 6]
[ 0 1 3 3 4 5 10]またビンのリストの最大値を超えた値がデータのリストにある場合、インデックスは「最大のインデックス+1」となってしまうため、値を取得できなくなることに注意してください。
import numpy as np
data = [-0.2, 0.3, 2, 2.7, 3.2, 4.8, 8.0, 15]
bins = [0, 1, 2, 3, 4, 5, 10]
index_list = np.digitize(data, bins)
print(index_list)
print(np.array(bins)[index_list])
実行結果
[0 1 3 3 4 5 6 7]
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Cell In[51], line 10
6 index_list = np.digitize(data, bins)
8 print(index_list)
---> 10 print(np.array(bins)[index_list])
IndexError: index 7 is out of bounds for axis 0 with size 7ビンの値と被る場合の処理:right
ビンの値にちょうど被る場合の値の処理については「right」というオプション引数を使うことで制御することができます。
デフォルトは「right=False」で、その場合、ビンの値が昇順だと被った値が左端になる様なビンに分類されます。
import numpy as np
data = [-0.2, 0.3, 2, 2.7, 3.2, 4.8, 8.0]
bins = [0, 1, 2, 3, 4, 5, 10]
index_list = np.digitize(data, bins, right=False)
print(index_list)
実行結果
[0 1 3 3 4 5 6]この場合、ビンの値と被る「2」はビンのリストの「2」と「3」の間に分類されるため、インデックスとしては「3」となります。
ビンの値が降順だった場合、被った値が右端になる様なビンに分類されます。
import numpy as np
data = [-0.2, 0.3, 2, 2.7, 3.2, 4.8, 8.0]
bins = [10, 5, 4, 3, 2, 1, 0]
index_list = np.digitize(data, bins, right=False)
print(index_list)
実行結果
[7 6 4 4 3 2 1]この場合、ビンの値と被る「2」はビンのリストの「3」と「2」の間に分類されるため、インデックスとしては「4」となります。
「right=True」の場合は逆の結果となります。
つまりビンの値が昇順だと被った値が右端になる様なビンに分類されます。
import numpy as np
data = [-0.2, 0.3, 2, 2.7, 3.2, 4.8, 8.0]
bins = [0, 1, 2, 3, 4, 5, 10]
index_list = np.digitize(data, bins, right=True)
print(index_list)
実行結果
[0 1 2 3 4 5 6]逆にビンの値が降順だと被った値が左端になる様なビンに分類されます。
import numpy as np
data = [0.3, 2, 2.7, 3.2, 4.8, 8.0]
bins = [10, 5, 4, 3, 2, 1, 0]
index_list = np.digitize(data, bins, right=True)
print(index_list)
実行結果
[6 5 4 3 2 1]まとめるとこんな感じです。
| right=False(デフォルト) | right=True | |
| ビンのリストが昇順 | 被った値が左端になるビン | 被った値が右端になるビン |
| ビンのリストが降順 | 被った値が右端になるビン | 被った値が左端になるビン |
次回はmatplotlibのspecgramを使って時間周波数解析をする方法を紹介します。
ではでは今回はこんな感じで。
コメント