データ解析支援ライブラリPandas
前回、ランダムなデータファイルを作るプログラムを作成してみました。
今回はそのプログラムで作成したデータをデータ解析支援ライブラリPandasを使って読み込み、グラフ表示してみたいと思います。
ちなみにPandas自体はデータの読み込み、グラフ表示だけではなく、データを解析するための様々なコマンドが備えられています。
その細かな解説はまた後ほどすることにして、とりあえず使ってみるという精神で進めていきましょう。
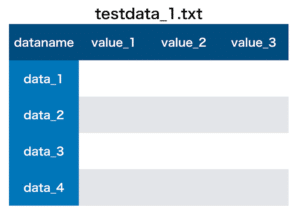
今回使ったデータセットはこちら。
もしこの記事と全く同じ結果を得たい方は、こちらのデータセットを使ってみてください。
それでは始めていきましょう。
ライブラリのインポートとセッティング
今回使うライブラリは「os」、「pandas」、「matplotlib」です。
ということでインポート部分はこんな感じ。
import os
import pandas as pd
from matplotlib import pyplot as plt「pandas」は慣例的に「pd」としてインポートされるので、それに倣っておきます。
「matplotlib」はいつも通り「Pyplot」を「plt」としてインポートしておきます。
次に「file_ext = “.txt”」を追加します。
import os
import pandas as pd
from matplotlib import pyplot as plt
file_ext = ".txt"こちらは後ほど読み込むファイルを選定するために使います。
今回の場合は拡張子が「.txt」というファイルのみ読み込むようにプログラムするということです。
もし拡張子が「.csv」のファイルを読み込みたい場合は、 「file_ext = “.csv”」と変更してください。
ファイル名の取得
では次にファイル名の取得を行なっていきます。
その部分はこんな感じ。
filename = []
for f in os.listdir("./"):
if f[-4:] == file_ext:
filename.append(f)
print(filename)「filename = []」でファイル名を格納するための空のリストを作ります。
「for f in os.listdir(“./”):」で現在いるフォルダの中のフォルダ名・ファイル名を全て取得し、一つずつ変数fに格納します。
ただこのままでは目的のファイル以外のものまで取得してしまうので、「if f[-4:] == file_ext:」で変数file_extと同じ、つまり拡張子が「.txt」のファイルのみ次の処理に進ませます。
ここまでで目的のファイルが取得できているので、そのファイル名をリストfilenameに格納します。
最後に「print(filename)」でちゃんと目的のファイル名が取得できているか確認してみました。
実行結果
['testdata_9.txt', 'testdata_8.txt', 'testdata_10.txt', 'testdata_5.txt', 'testdata_4.txt', 'testdata_6.txt', 'testdata_7.txt', 'testdata_3.txt', 'testdata_2.txt', 'testdata_1.txt']順番はおかしいですが、とりあえず必要なファイル名が取得できているので、次に進むことにしましょう。
ちなみに「print(filename)」は確認用だったので、行の先頭に「#」をつけてコメントアウトしておきます。
Pandasでのデータ読み込み
ここからPandasを使う部分に入っていきます。
このセクションではファイル名を一つ取得し、そのファイル名をもつファイルをPandasで開き、そのデータを表示してみましょう。
その部分のプログラムはこんな感じ。
for f in filename:
df = pd.read_csv(f)
print(df)「for f in filename:」でリストfilenameにあるファイル名を一つ取得し、変数fに入れます。
そして「df = pd.read_csv(f)」でファイルを開き、その中のデータを変数dfに入れます。
ということで、PandasでCSVファイルを読み込む方法は「pd.read_csv(ファイル名)」となります。
そして格納したデータを「print(df)」で表示しています。
これをリストfilenameに格納されているファイル名に対して繰り返すというわけです。
ということでここまでのプログラムはこうなります。
filename = []
for f in os.listdir("./"):
if f[-4:] == file_ext:
filename.append(f)
# print(filename)
for f in filename:
df = pd.read_csv(f)
print(df)
実行結果
dataname value_1 value_2 value_3 value_4 value_5 value_6
0 data_1 77 6 94 78 13 69
1 data_2 74 93 26 64 48 8
2 data_3 70 14 92 11 61 71
3 data_4 52 85 14 35 44 62
4 data_5 62 84 8 15 67 11
5 data_6 9 85 30 95 4 55
6 data_7 59 12 9 16 42 11
7 data_8 37 86 86 26 32 22
8 data_9 16 58 62 64 33 98
9 data_10 8 87 56 32 65 99
dataname value_1 value_2 value_3 value_4 value_5 value_6
0 data_1 75 45 18 33 56 22
1 data_2 87 1 46 69 91 54
2 data_3 27 46 63 57 79 78
3 data_4 18 34 12 83 66 40
4 data_5 80 84 43 65 60 89
5 data_6 32 66 7 56 34 92
6 data_7 77 83 67 54 21 57
7 data_8 79 88 42 49 74 38
8 data_9 64 93 50 79 38 57
9 data_10 87 39 76 84 55 91...(以下省略)これでちゃんとデータが読み込めたことが確認できました。
確認できたので、print(df)はコメントアウトしておきます。
グラフの表示
Pandasを使った場合、グラフの表示は簡単です。
「df.plot()」 だけでグラフを表示することができます。
つまりここまでのプログラムはこんな感じ。
filename = []
for f in os.listdir("./"):
if f[-4:] == file_ext:
filename.append(f)
# print(filename)
for f in filename:
df = pd.read_csv(f)
# print(df)
df.plot()
実行結果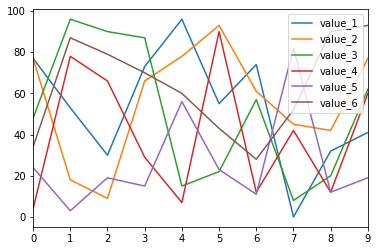
こんなグラフが10個表示されたら成功です。
これにそれぞれのグラフにタイトルをつけるのですが、そのタイトルはそれぞれのファイル名としてみましょう。
その場合は「plt.title()」を追加し、括弧の中はファイル名、つまり今回の場合は変数fを入れます。
filename = []
for f in os.listdir("./"):
if f[-4:] == file_ext:
filename.append(f)
# print(filename)
for f in filename:
df = pd.read_csv(f)
# print(df)
df.plot()
plt.title(f)
実行結果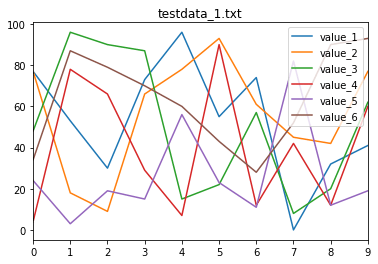
こんなファイルでタイトルがそれぞれ違うグラフが得られたら成功です。
あとは一つずつ保存するのは面倒なので、自動保存のコマンド「plt.savefig()」を追加しておきましょう。
filename = []
for f in os.listdir("./"):
if f[-4:] == file_ext:
filename.append(f)
# print(filename)
for f in filename:
df = pd.read_csv(f)
# print(df)
df.plot()
plt.title(f)
plt.savefig(f[:-4] + ".png")これを実行すると、グラフが自動でフォルダに保存されます。
ちなみに「f[:-4] + “.png”」としたのは、変数fは拡張子を含んだファイル名なので、その拡張子部分(後ろから4文字)を除いた部分に画像用の拡張子「.png」を追加するという操作をしています。
グラフの見栄えを整える
最後にグラフの見栄えを整えていきましょう。
今、得られているグラフはこんな感じ。
実はX軸が数字になってしまっているので、ここをデータ名に変えましょう。
この時の問題点はデータをPandasで読み込む時のこのコマンドにあります。
df = pd.read_csv(f)またちなみに各ファイルの中のデータはこんな感じになっています。
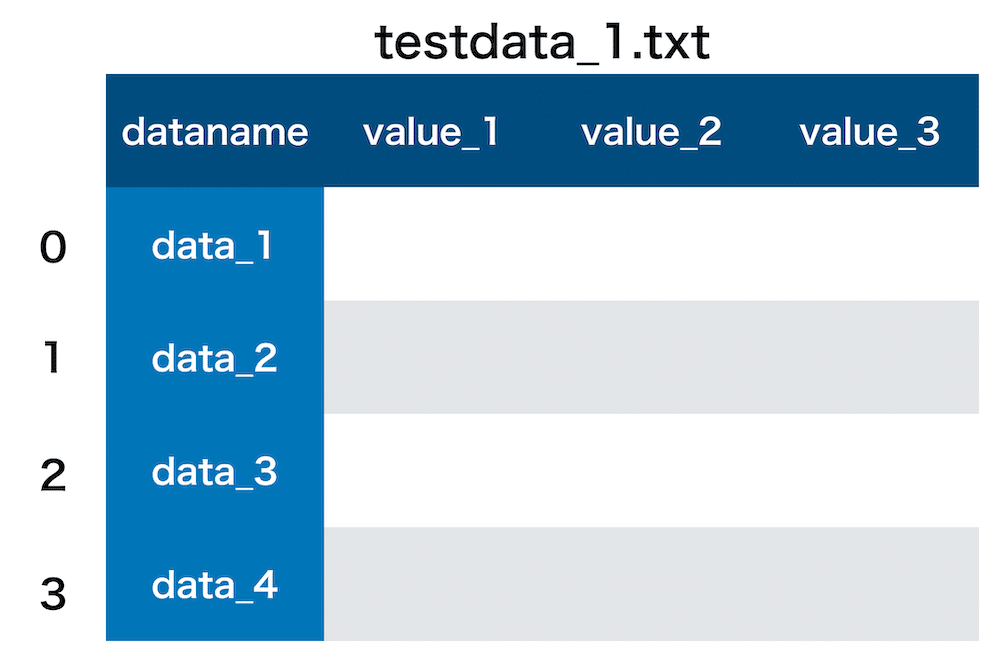
現在のコマンドだと「dataname」の列もデータの一部として判断されていて、それぞれのデータのインデックスが左の「0 1 2 3 …」というように割り振られています。
でも本当は「dataname」の列をインデックスとして使いたいわけです。
そのためコマンドはこうなります。
df = pd.read_csv(f, index_col = 0)「index_col = 0」を追加するとその数字の列がインデックスとして認識されます。
ということで書き直したプログラムがこちら。
filename = []
for f in os.listdir("./"):
if f[-4:] == file_ext:
filename.append(f)
# print(filename)
for f in filename:
df = pd.read_csv(f, index_col = 0)
# print(df)
df.plot()
plt.title(f)
plt.savefig(f[:-4] + ".png")
実行結果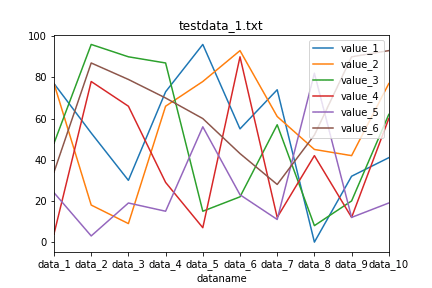
X軸が各データ名に変わったグラフが10個できたと思います。
ただ今度はX軸のデータ名がちょっと窮屈になってしまっています。
そこでX軸のデータ名を90度回転させて縦書きにしてみましょう。
そのコマンドはこんな感じ。
plt.xticks(rotation=90)で書き換えて、実行してみます。
filename = []
for f in os.listdir("./"):
if f[-4:] == file_ext:
filename.append(f)
# print(filename)
for f in filename:
df = pd.read_csv(f, index_col = 0)
# print(df)
df.plot()
plt.title(f)
plt.xticks(rotation=90)
plt.savefig(f[:-4] + ".png")
実行結果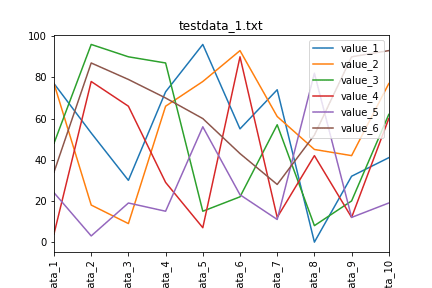
X軸のデータ名が縦書きになったグラフが10個得られました。
とりあえず今回はPandasを使って、データを読み込み、グラフとして表示するということをやってみました。
やはりいつも使っている方法とは違うので、戸惑った箇所はあるのですが、思ったより使いやすいかもしれないというのが個人的な感触です。
単純なデータ(例えば時間と温度、湿度くらいのデータ)だったら、Pandasを使う利点はそれほどないかもしれませんが、複数の値が一つのデータに含まれていて、さらにそのデータが大量にある場合はPandasを使う格好の場面になるでしょう。
とりあえずデータをランダムに作り出すプログラムもできたことですし、Pandasを勉強する体制は整ってきたなと。
また機会があれば、Pandasの解説をしていきたと思います。
ということで今回はこんな感じで。
コメント