nanとは?
今回は前に作成したダミーデータのファイルを生成するプログラムをアップデートしていきます。
アップデートする方向としては「nan」という値をランダムに入れるということです。
ここで疑問。
「nan」とは何か?
読み方としてはそのまま「ナン」と呼びます。
ちなみに「Nan」と最初の文字を大文字で書くこともあります。
Wikipediaによると
NaN(Not aNumber、非数、ナン)は、コンピュータにおいて、主に浮動小数点演算の結果として、不正なオペランドを与えられたために生じた結果を表す値またはシンボルである。
https://ja.wikipedia.org/wiki/NaN
とのことです。
このままだとよく分かりませんが、要するに計算できない計算、例えば0で割るという割り算は数学上してはいけない計算になります。
このような場合の結果が「nan」というわけです。
ただこれから行うデータ解析では「取得できなかった値」、つまりは「欠損値」として扱われています。
ちなみにこの「欠損値」という考え方の場合、「0」とは大きな違いがあるので注意してください。
「0」は「0」という値が取得できたことを示しています。
そして「nan」は値が取得できなかったことを示しています。
この違いは覚えておいてください。
これからPandasを使ってデータ解析を行なっていくと、この「nan」という値が出てきます。
そこでこの「nan」の扱い方を解説するためのダミーデータを作成するためのプログラムを今回作成するということです。
ダミーデータ作成プログラムのおさらい
まずは前に作ったダミーデータ作成プログラムをおさらいしてみます。
最初にはcsvとrandomライブラリをインポートしています(インポート部)。
import csv
import random次にはセッティング部です。
ファイル名、行名、列名用の設定、ファイル数、行数、列数の設定、ランダム数の範囲を指定しています。
#Settings
file_name_head = "testdata_"
file_name_end = ""
file_ext = ".txt"
data_name_head = "data_"
data_name_end = ""
value_name_head = "value_"
value_name_end = ""
index_name = "dataname"
no_files = 10
rows = 10
columns = 6
random_range = [0, 99]最後はプログラム部です。
#Main
for no_file in range(no_files):
filename = file_name_head + str(no_file + 1) + file_name_end + file_ext
# print(filename)
f = open(filename, "w")
writer = csv.writer(f)
header = [index_name]
for column in range(columns):
valuename = value_name_head + str(column + 1) + value_name_end
header.append(valuename)
writer.writerow(header)
for row in range(rows):
data = []
dataname = data_name_head + str(row + 1) + data_name_end
data.append(dataname)
for column in range(columns):
data.append(random.randint(random_range[0], random_range[1]))
writer.writerow(data)
f.close()
print("Done")ファイル名、列名を書き出して、その後、リスト「data」に行データとして行名、数値を列数分入れて書き出しています。
これを書き換えていきます。
nanデータを書き出すプログラムへ変更
まずnanを書き出すのにnumpyが必要なので、こちらをインポートします。
ということでインポート部はこんな感じ。
import csv
import random
import numpy as np次にセッティング部です。
#Settings
file_name_head = "testdata_"
file_name_end = ""
file_ext = ".txt"
data_name_head = "data_"
data_name_end = ""
value_name_head = "value_"
value_name_end = ""
index_name = "dataname"
no_files = 1
rows = 10
columns = 5
random_range = [0, 100]
nan_val = [100]「random_range = [0, 100]」が[0, 99]から[0, 100]に変更して、そして一番最後に「nan_val = [100]」という行を追加しました。
これはランダムに取得した数が100だった場合に、その数をnanにするプログラムにするためです。
また「nan_val」をリストにしているのは、「nan」が出現する確率を上げたい時に複数の数字を設定できるようにしたかったからです。
現在だと1/101の確率でnanが出現することになります。
次にプログラム部です。
#Main
for no_file in range(no_files):
filename = file_name_head + str(no_file + 1) + file_name_end + file_ext
# print(filename)
f = open(filename, "w")
writer = csv.writer(f)
header = [index_name]
for column in range(columns):
valuename = value_name_head + str(column + 1) + value_name_end
header.append(valuename)
writer.writerow(header)
for row in range(rows):
data = []
dataname = data_name_head + str(row + 1) + data_name_end
data.append(dataname)
for column in range(columns):
random_val = random.randint(random_range[0], random_range[1])
if random_val in nan_val:
random_val = np.nan
print(random_val)
data.append(random_list)
writer.writerow(data)
f.close()
print("Done")変更点はこの部分。
random_val = random.randint(random_range[0], random_range[1])
if random_val in nan_val:
random_val = np.nan
print(random_val)
data.append(random_list)元々はこうでした。
for column in range(columns):
data.append(random.randint(random_range[0], random_range[1]))つまり下の行のプログラムでランダムに数を取得し、変数random_valに格納します。
random_val = random.randint(random_range[0], random_range[1])そして次のプログラムで、変数randam_valに格納した数字がリストnan_valに含まれていた場合、変数random_valをnanに書き換え(np.nan)ています。
if random_val in nan_val:
random_val = np.nan
print(random_val)
data.append(random_val)「print(random_val)」は書き出すデータに「nan」が含まれているか確認するため、数値を出力してみました。
最後にリストdataにrandom_valを格納しています。
そして最後の「writer.writerow(data)」で書き出しているというわけです。
プログラムを実行して、nanが入ったデータが得られるか試してみる
プログラムが作成できたので試してみましょう。
ということで1回目。
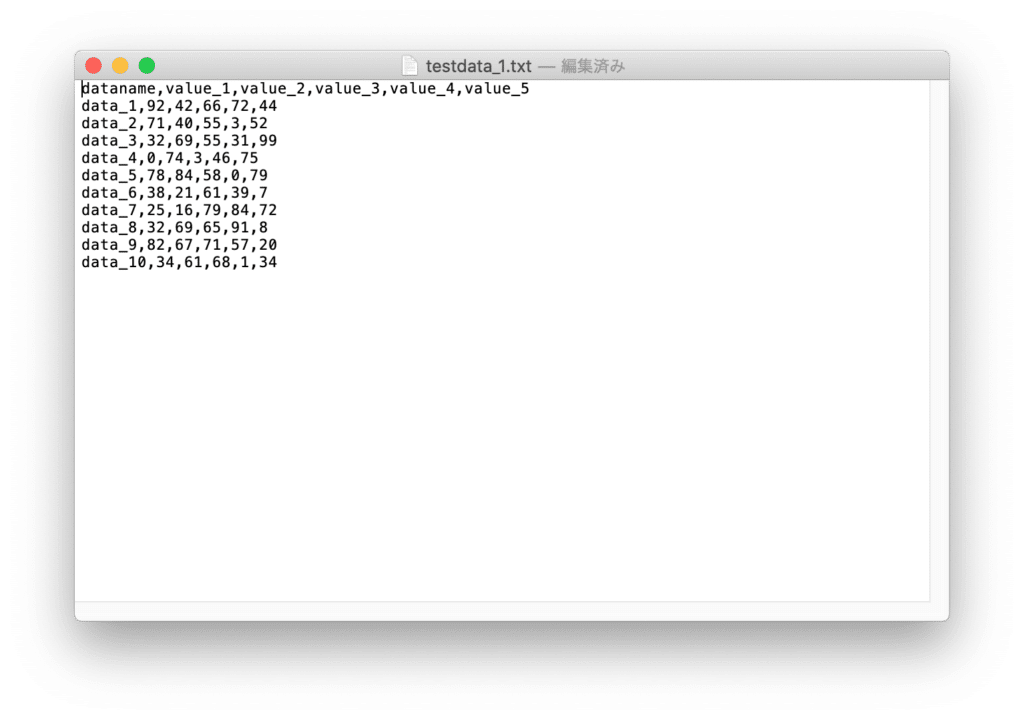
「nan」は入りませんでした。
2回目。
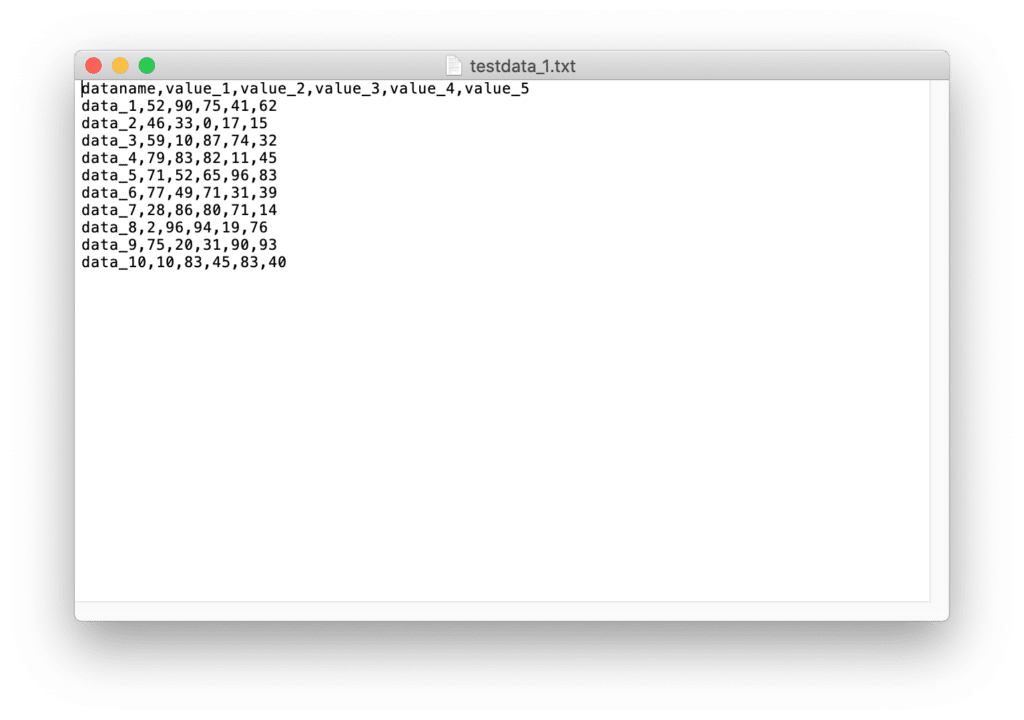
2回目も入りませんでした…
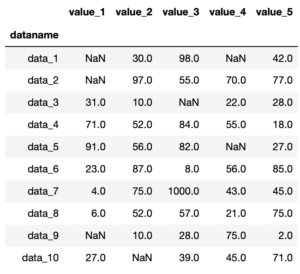
3回目。
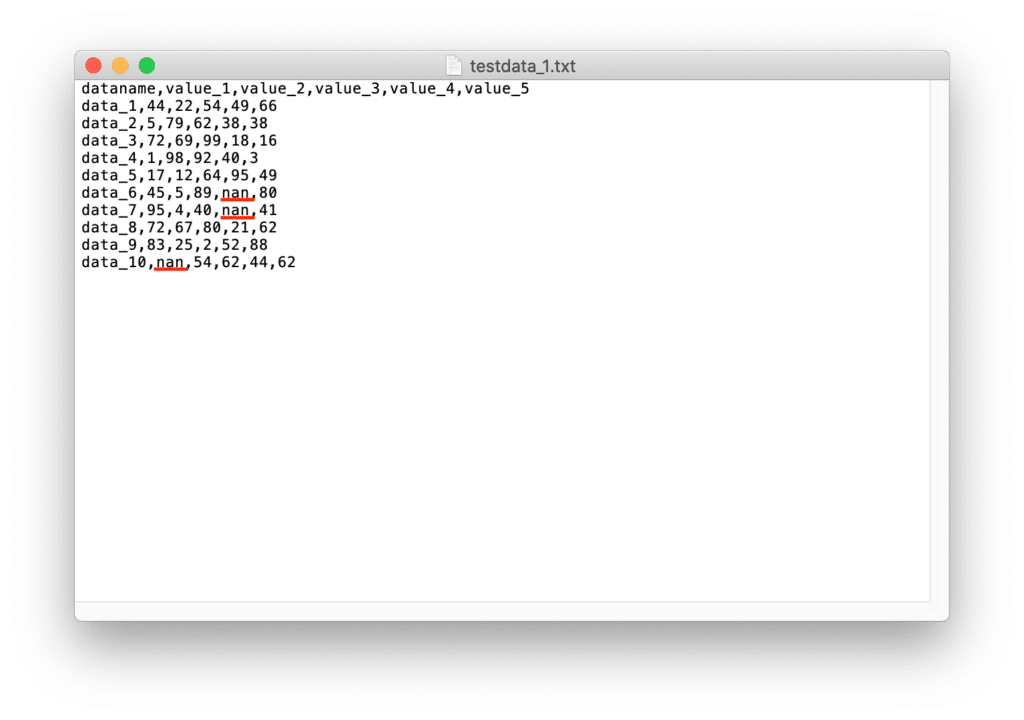
3箇所に「nan」が入りました。
これで今回作成したプログラムの目的達成です。
ということで次回はPandasでnan入りのデータの処理方法を試していきましょう。
ではでは今回はこんな感じで。
コメント