Pandas
今回はPythonのデータ解析支援ライブラリPandasでよくやる操作として、データフレーム、もしくはシリーズの連結、重複の削除、そして再インデックスするという流れを紹介します。
ちなみにデータフレームの連結に関してはこちらの記事でも解説していますので、よかったらどうぞ。
それでは始めていきましょう。
事前準備
まずは連結するデータを準備します。
import pandas as pd
import numpy as np
columnname = ['A', 'B', 'C']
data1 = np.array([[1, 2, 3], [2, 4, 6], [3, 6, 9]])
data2 = np.array([[3, 6, 9],[4, 8, 12], [5, 10, 15]])
df1 = pd.DataFrame(columns=columnname, data=data1)
df2 = pd.DataFrame(columns=columnname, data=data2)A、B、Cという列名を持ったデータフレームを2つ作成し、一つは「[1, 2, 3], [2, 4, 6], [3, 6, 9]」というデータ、もう一つは「[3, 6, 9],[4, 8, 12], [5, 10, 15]」というデータを格納しています。
表示させて確認してみるとこんな感じです。
df1
実行結果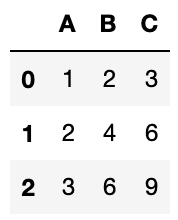
df2
実行結果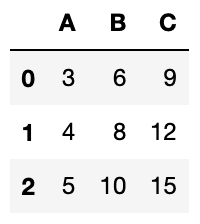
df1の3番目のデータととdf2の1番目のデータは同じデータになっていて、連結させると重複するようになっています。
データフレーム同士の連結:concat
まずは準備した二つのデータフレームdf1とdf2を連結してみましょう。
データフレームを連結するには「pd.concat([データフレーム1, データフレーム2])」で連結します。
df_new1 = pd.concat([df1, df2])
df_new1
実行結果
ちなみに「pd.concat([データフレーム1, データフレーム2, データフレーム3])」とすることで3つ以上のデータフレームを一度に連結することも可能です。
しかしconcatではデータフレームとシリーズの連結をすることもできますが、思ったようにいかないこともしばしばです。
df_new2 = pd.concat([df1, df2.iloc[1]])
df_new2
実行結果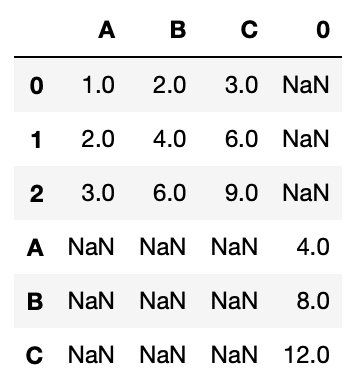
今回の場合はdf2の一部をシリーズをデータフレームdf1に新しい行として追加したかったのですが、新しい行、列に追加されてしまいました。
データフレームとシリーズの連結:append
データフレームに対して、新しい行としてシリーズを追加したい場合は「append」を使う方がスムーズにいくでしょう。
使い方としては「データフレーム.append(シリーズ)」です。
df_new3 = df1.append(df2.iloc[1])
df_new3
実行結果
appendでデータフレーム同士の連結
ちなみにappendでは「データフレーム1.append(データフレーム2)」とすることで、データフレーム同士の連結もできます。
df_new4 = df1.append(df2)
df_new4
実行結果
重複したデータの削除:drop_duplicates()
今回のdf1とdf2を連結するとデータの重複が発生します。
この重複を削除するには、「データフレーム.drop_duplicates()」を用います。
df_new1 = pd.concat([df1, df2])
df_new4 = df_new1.drop_duplicates()
df_new4
実行結果
インデックス番号の振り直し:reset_index()
データを連結したり、重複を削除するとインデックス番号がぐちゃぐちゃになってしまいます。
そこでデータを整形した後はインデックス番号を振り直すとデータが使いやすくなります。
インデックス番号を振り直すには「データフレーム.reset_index()」を使います。
df_new5 = df_new4.reset_index()
df_new5
実行結果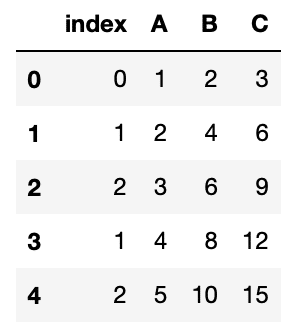
新しくインデックス番号が振られましたが、前のインデックス番号も列として残ってしまっています。
前のインデックス番号を参照したい場合はいいのですが、邪魔になる場合は「drop=True」のオプションを付けることで古いインデックス番号を削除することもできます。
df_new6 = df_new4.reset_index(drop=True)
df_new6
実行結果
また上記2つの例では重複を削除したデータフレームを新しいデータフレームに格納していますが、データフレームを上書きするということもできます。
その場合は「inplace=True」のオプションを追加します。
df_new4.reset_index(drop=True, inplace=True)
df_new4
実行結果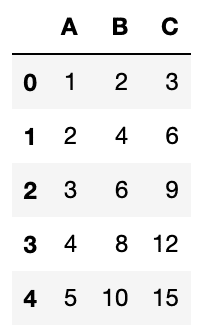
これでデータフレームの連結、重複の削除、インデックス番号の振り直しの一連の流れができました。
複数のデータフレームを使い出すとやる流れだと思うので、知っておくと便利かもしれません。
次回はすっかり忘れていたシリーズに関して、作成、要素の追加・削除を勉強してみましょう。
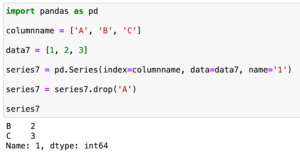
ではでは今回はこんな感じで。
コメント