データ解析支援ライブラリPandas
前回はデータ解析支援ライブラリPandasのassignで列を、appendで列を追加する方法を解説しました。
今回は追加するという流れでデータフレームを連結する方法を解説していきたいと思います。
ということで今回もまずは準備から。
今回はデータフレームを連結する方法ということで、複数のデータを準備しました。
こちらのデータをダウンロードして、展開すると以下の4つのファイルが入っています。
- python-pandas-10_data1.txt
- python-pandas-10_data2.txt
- python-pandas-10_data3.txt
- python-pandas-10_data4.txt
とりあえずこの4つのデータを読み込んで表示してみましょう。
import pandas as pd
df1 = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df2 = pd.read_csv("python-pandas-10_data2.txt", index_col=0)
df3 = pd.read_csv("python-pandas-10_data3.txt", index_col=0)
df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
df1
実行結果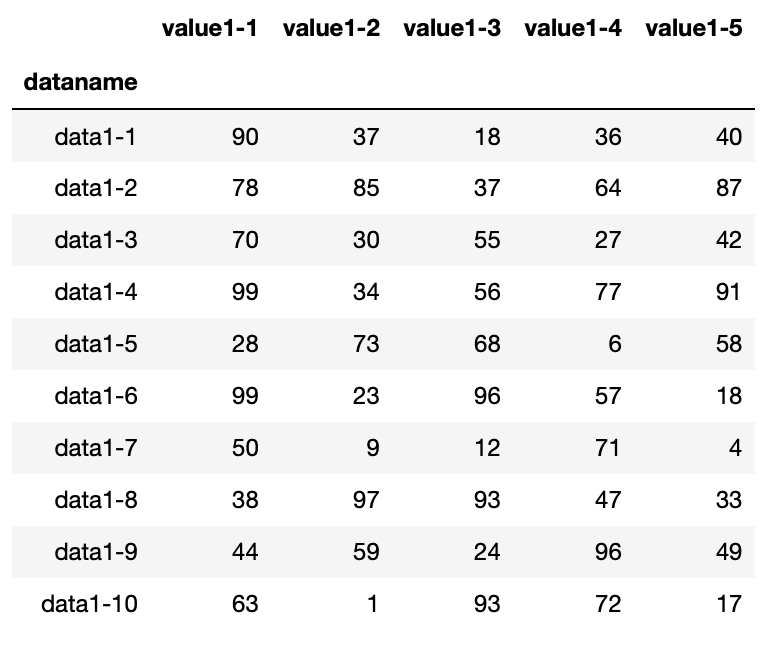
mport pandas as pd
df1 = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df2 = pd.read_csv("python-pandas-10_data2.txt", index_col=0)
df3 = pd.read_csv("python-pandas-10_data3.txt", index_col=0)
df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
df2
実行結果
mport pandas as pd
df1 = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df2 = pd.read_csv("python-pandas-10_data2.txt", index_col=0)
df3 = pd.read_csv("python-pandas-10_data3.txt", index_col=0)
df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
df3
実行結果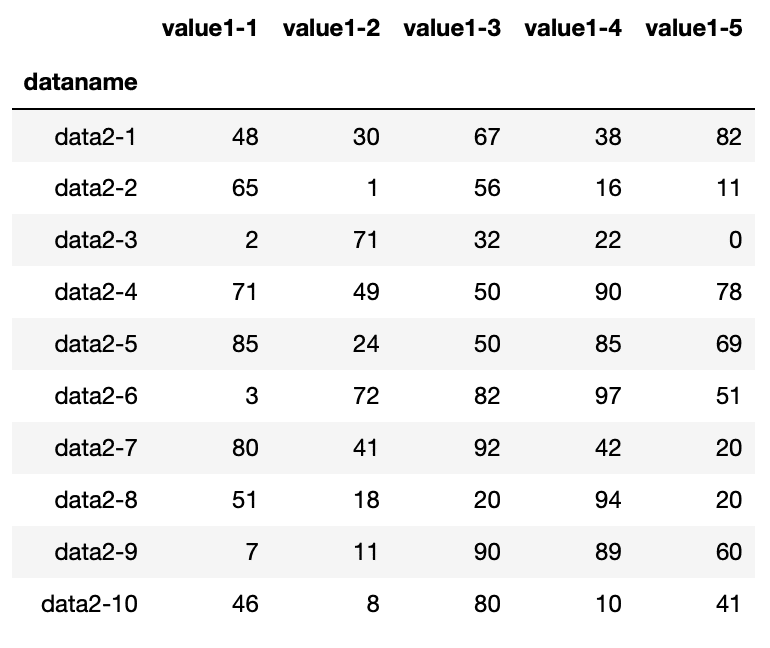
mport pandas as pd
df1 = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df2 = pd.read_csv("python-pandas-10_data2.txt", index_col=0)
df3 = pd.read_csv("python-pandas-10_data3.txt", index_col=0)
df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
df4
実行結果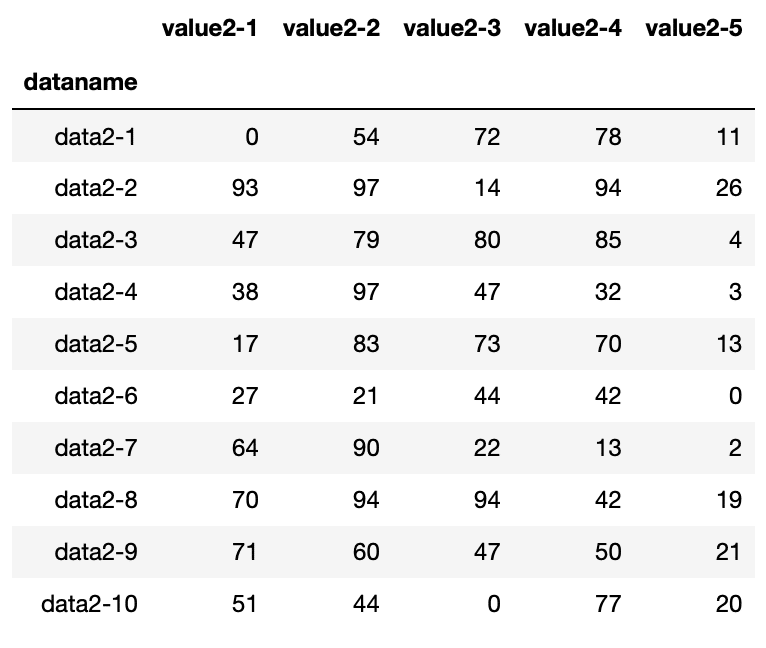
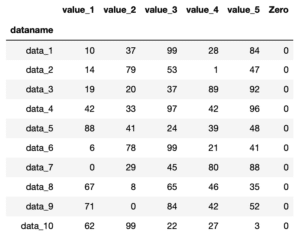
同じように見えますが、違うのは列名や行名です。
1番「python-pandas-10_data1.txt」のデータは、列名が「value_1-X」、行名が「data_1-X」となっています。
2番「python-pandas-10_data2.txt」のデータは、列名が「value_1-X」、行名が「data_2-X」となっています。
3番「python-pandas-10_data3.txt」のデータは、列名が「value_2-X」、行名が「data_1-X」となっています。
4番「python-pandas-10_data4.txt」のデータは、列名が「value_2-X」、行名が「data_2-X」となっています。
つまり1番と2番では列名は同じで、行名は違い、1番と3番では列名が異なり、行名が同じ、1番と4番では列名も行名も異なるということです。
では試していきましょう。
concatでデータフレームを連結:列名が同じで行名が違う場合
データフレームを連結するには、concatというコマンドを用い、「データフレーム名 = pd.concat([データフレーム1, データフレーム2])」とします。
まずは列名が同じで行名が違う、1番のデータと2番のデータを連結してみましょう。
その場合、「df_12 = pd.concat[(df1, df2)]」となります。
ということで試してみましょう。
import pandas as pd
df1 = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df2 = pd.read_csv("python-pandas-10_data2.txt", index_col=0)
df3 = pd.read_csv("python-pandas-10_data3.txt", index_col=0)
df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
df_12 = pd.concat([df1, df2])
df_12
実行結果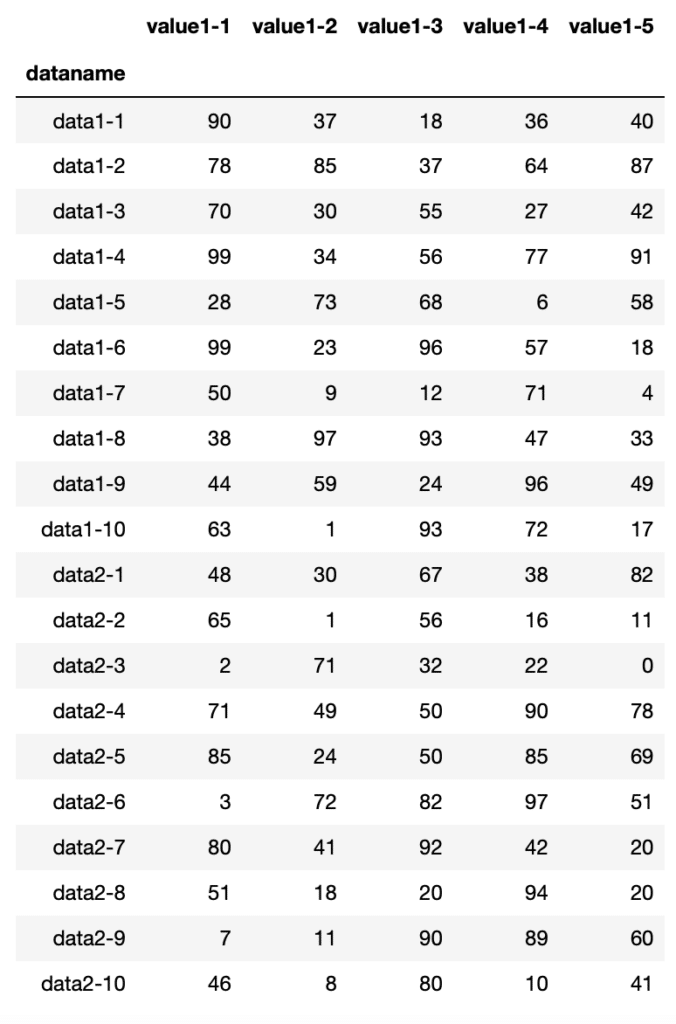
列名が同じなので縦に連結されました。
concatでデータフレームを連結:列名が違い、行名が同じ場合
列名が同じで、行名が異なる場合、縦に連結されました。
では列名が違い、行名が同じ場合、自動で横に連結されるのでしょうか?
ということで1番と3番のデータを連結してみましょう。
「df_13 = pd.concat([df1, df3])」を追加して、実行してみます。
import pandas as pd
df1 = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df2 = pd.read_csv("python-pandas-10_data2.txt", index_col=0)
df3 = pd.read_csv("python-pandas-10_data3.txt", index_col=0)
df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
df_13 = pd.concat([df1, df3])
df_13
実行結果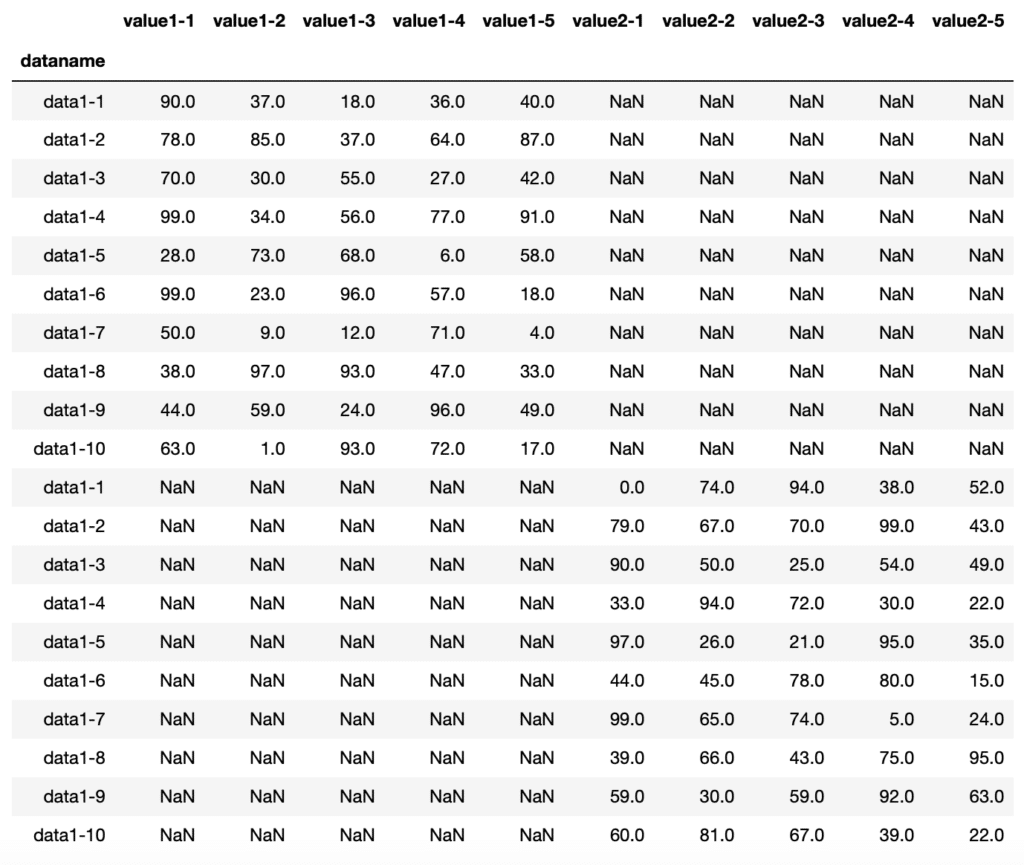
なんと予想に反して、行も列も新しいものだと認識されてしまいました。
実はconcatのコマンドは、縦に連結するのが基本なのです。
横に連結するには、オプションとしてaxis=1を追加します。
つまり「df_13 = pd.concat([df1, df3], axis=1)」とする必要があるわけです。
import pandas as pd
df1 = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df2 = pd.read_csv("python-pandas-10_data2.txt", index_col=0)
df3 = pd.read_csv("python-pandas-10_data3.txt", index_col=0)
df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
df_13 = pd.concat([df1, df3], axis=1)
df_13
実行結果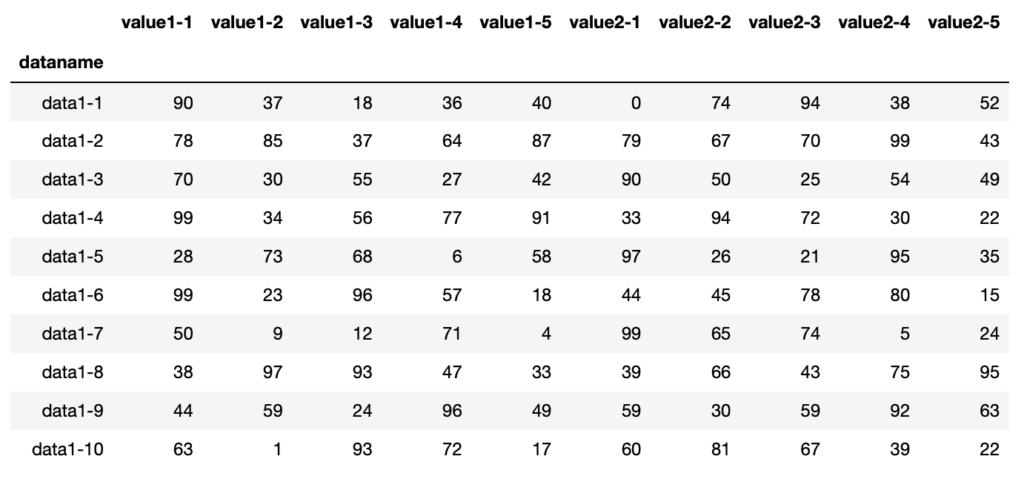
横に連結する場合はaxis=1、では縦に連結する場合は?
先ほど横に連結するためのオプションはaxis=1を追加すると解説しました。
では縦に連結する場合はどうしたらいいのでしょうか?
答えはaxis=0となります。
再度、1番と2番のデータを連結して試してみましょう。
まずはオプションなし。
import pandas as pd
df1 = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df2 = pd.read_csv("python-pandas-10_data2.txt", index_col=0)
df3 = pd.read_csv("python-pandas-10_data3.txt", index_col=0)
df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
df_12 = pd.concat([df1, df2])
df_12
実行結果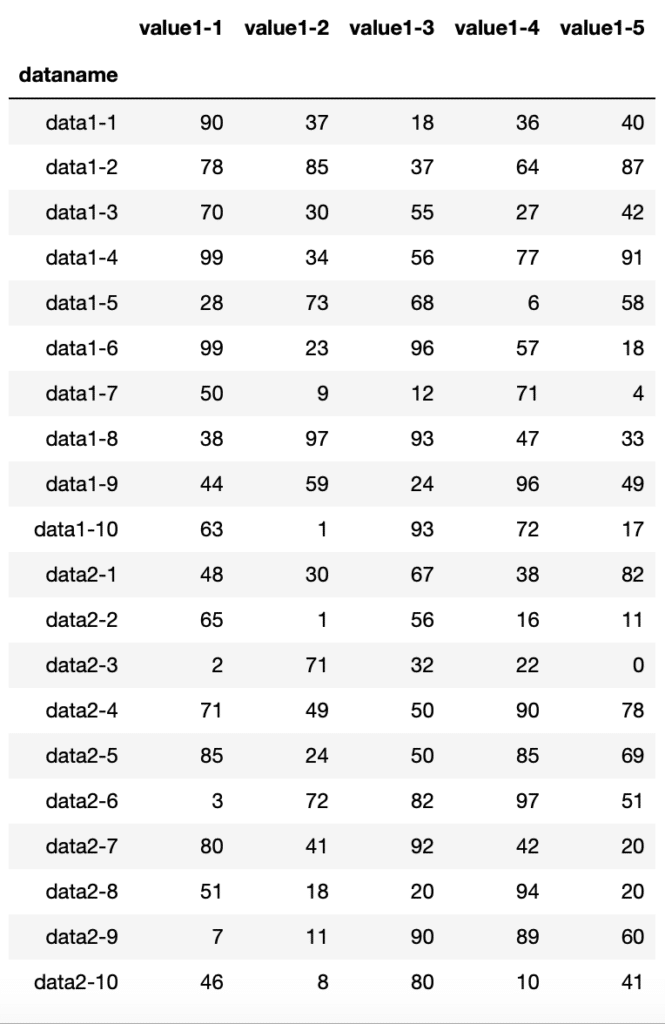
次にオプションとして、axis=0を追加してみます。
import pandas as pd
df1 = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df2 = pd.read_csv("python-pandas-10_data2.txt", index_col=0)
df3 = pd.read_csv("python-pandas-10_data3.txt", index_col=0)
df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
df_12 = pd.concat([df1, df2], axis=0)
df_12
実行結果
オプションがない場合と同じ結果になりました。
次にオプションとして、axis=1を追加してみましょう。
import pandas as pd
df1 = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df2 = pd.read_csv("python-pandas-10_data2.txt", index_col=0)
df3 = pd.read_csv("python-pandas-10_data3.txt", index_col=0)
df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
df_12 = pd.concat([df1, df2], axis=1)
df_12
実行結果
横に追加するのですが、行名が一致していないので、縦にも横にも新しい場所に追加されました。
axis=0が縦に追加、axis=1が横に追加としたら、axis=2とするとどうなるでしょうか?
import pandas as pd
df1 = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df2 = pd.read_csv("python-pandas-10_data2.txt", index_col=0)
df3 = pd.read_csv("python-pandas-10_data3.txt", index_col=0)
df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
df_12 = pd.concat([df1, df2], axis=2)
df_12
実行結果
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-36-8edfddc30224> in <module>
6 df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
7
----> 8 df_12 = pd.concat([df1, df2], axis=2)
9
10 df_12
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/reshape/concat.py in concat(objs, axis, join, join_axes, ignore_index, keys, levels, names, verify_integrity, sort, copy)
253 verify_integrity=verify_integrity,
254 copy=copy,
--> 255 sort=sort,
256 )
257
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/reshape/concat.py in __init__(self, objs, axis, join, join_axes, keys, levels, names, ignore_index, verify_integrity, copy, sort)
368 axis = DataFrame._get_axis_number(axis)
369 else:
--> 370 axis = sample._get_axis_number(axis)
371
372 # Need to flip BlockManager axis in the DataFrame special case
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/generic.py in _get_axis_number(cls, axis)
409 except KeyError:
410 pass
--> 411 raise ValueError("No axis named {0} for object type {1}".format(axis, cls))
412
413 @classmethod
ValueError: No axis named 2 for object type <class 'pandas.core.frame.DataFrame'>そんな値はないとエラーが表示されました。
concatでデータフレームを連結:列名も行名も違う場合
次に列名も行名も違う場合を試してみましょう。
ということで1番のデータと4番のデータを連結してみます。
まずはオプションなし、つまり縦に連結してみましょう。
import pandas as pd
df1 = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df2 = pd.read_csv("python-pandas-10_data2.txt", index_col=0)
df3 = pd.read_csv("python-pandas-10_data3.txt", index_col=0)
df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
df_14 = pd.concat([df1, df4])
df_14
実行結果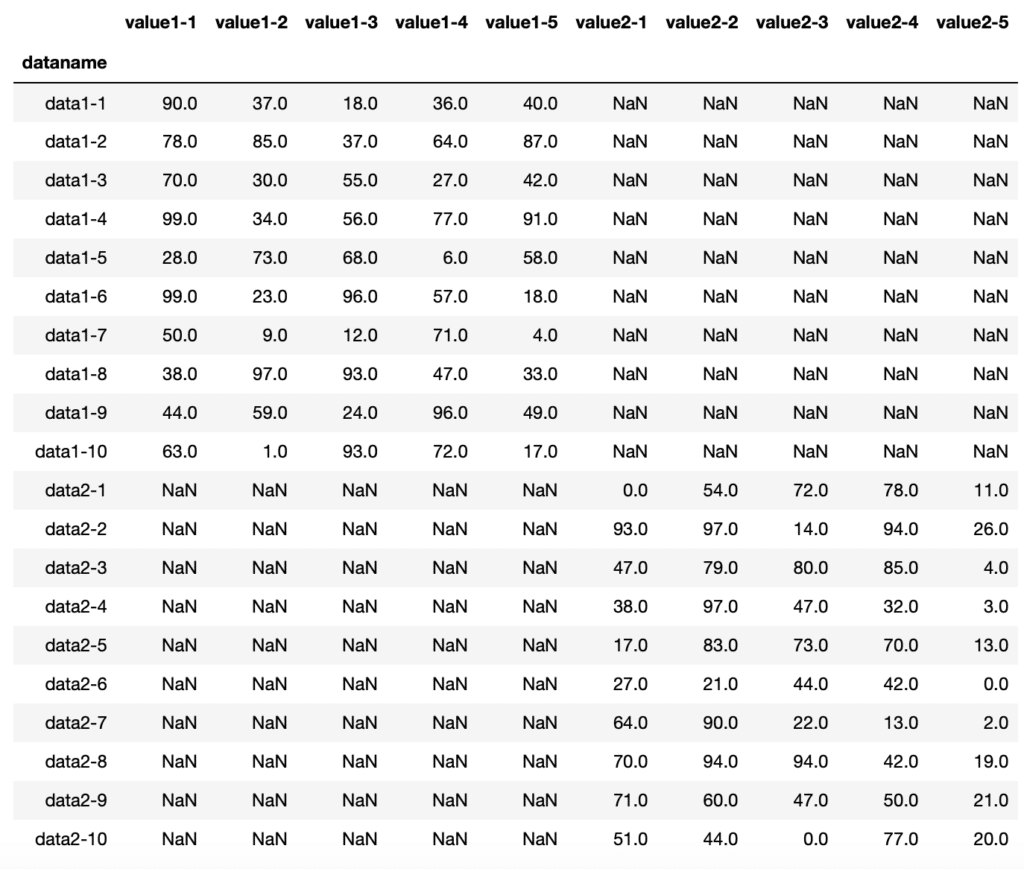
一致しないので、縦にも横にも新しい場所に追加されました。
次にaxis=1、つまり横に追加してみましょう。
import pandas as pd
df1 = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df2 = pd.read_csv("python-pandas-10_data2.txt", index_col=0)
df3 = pd.read_csv("python-pandas-10_data3.txt", index_col=0)
df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
df_14 = pd.concat([df1, df4], axis=1)
df_14
実行結果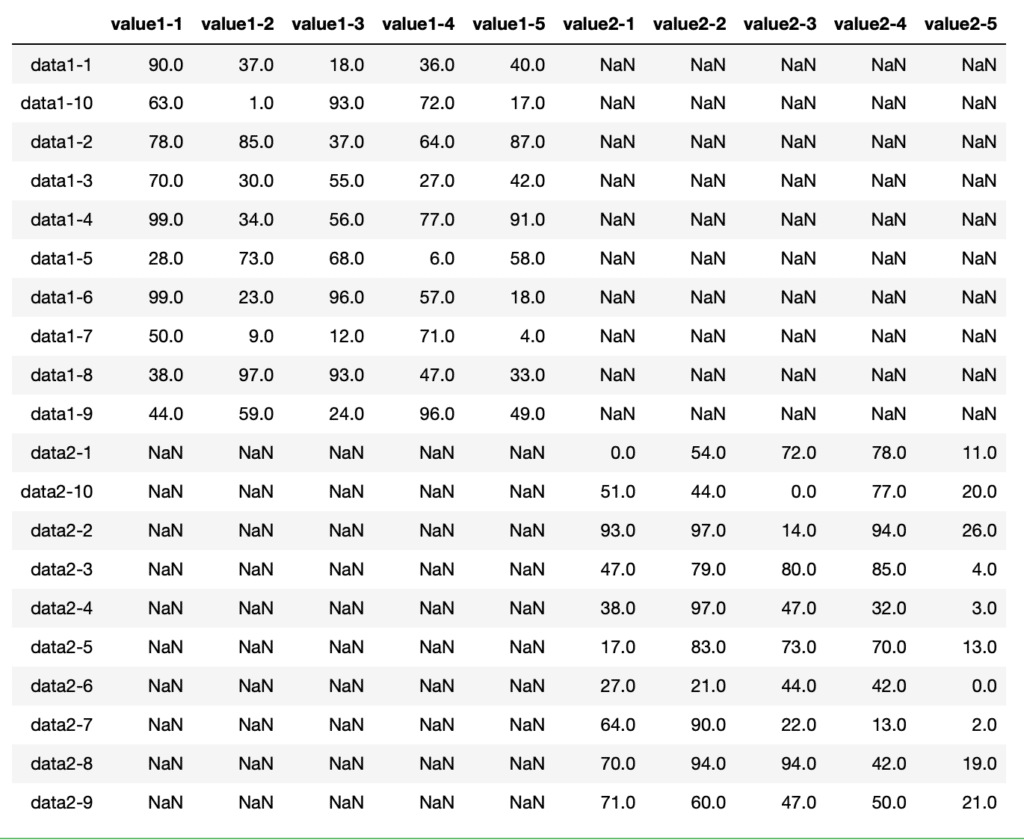
こちらも縦でも横でも名前は一致しないので、新しい場所に連結されました。
concatでデータフレームを連結:列名も行名も同じ場合
最後に列名も行名も同じ場合を試してみましょう。
つまり1番のデータと1番のデータを連結してみます。
まずはオプションなしで、縦に連結してみます。
import pandas as pd
df1 = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df2 = pd.read_csv("python-pandas-10_data2.txt", index_col=0)
df3 = pd.read_csv("python-pandas-10_data3.txt", index_col=0)
df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
df_11= pd.concat([df1, df1])
df_11
実行結果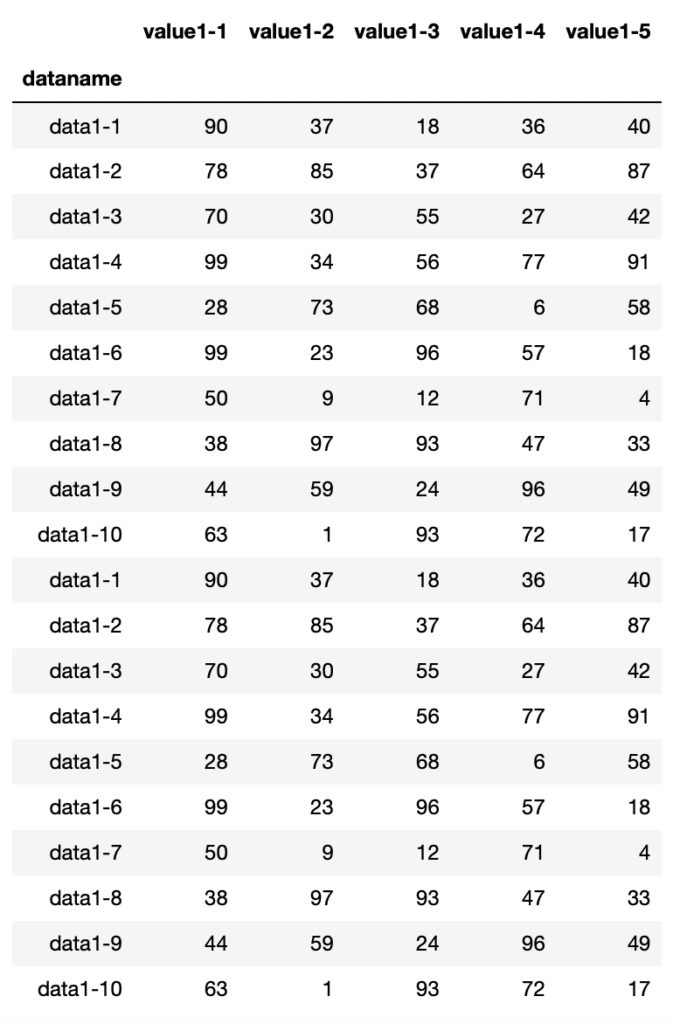
全く同じデータを連結しても大丈夫なのは少し驚きました。
とりあえずちゃんと縦に連結できています。
では横に連結する、つまりオプションとしてaxis=1を追加してみましょう。
import pandas as pd
df1 = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df2 = pd.read_csv("python-pandas-10_data2.txt", index_col=0)
df3 = pd.read_csv("python-pandas-10_data3.txt", index_col=0)
df4 = pd.read_csv("python-pandas-10_data4.txt", index_col=0)
df_11= pd.concat([df1, df1], axis=1)
df_11
実行結果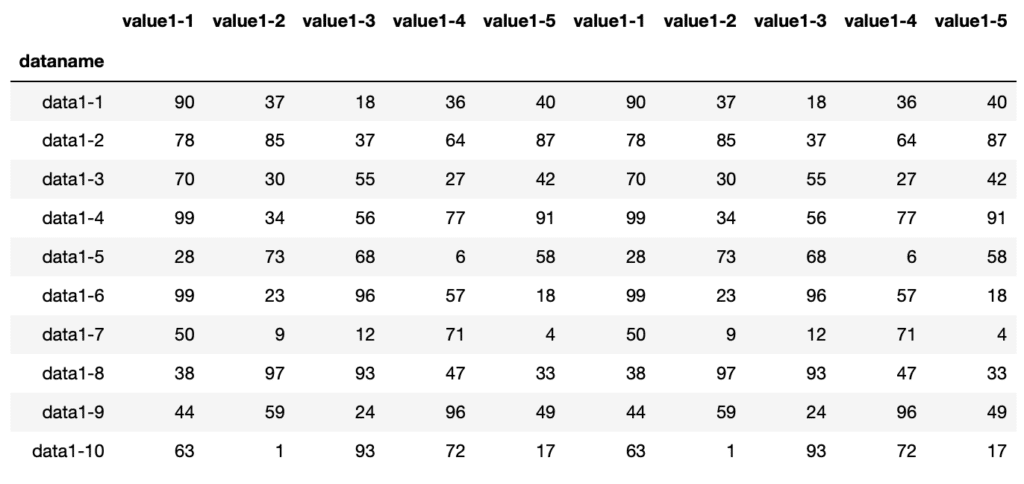
こちらも問題なく横に連結できました。
ということで今回はconcatというコマンドを使って、データフレームを連結する方法を解説しました。
ただここで少し疑問が生まれます。
今回のように同じ行名、列名を含むデータを連結すると、同じ行名、列名が複数回含まれてしまうこともあります。
例えばすぐ上の同じ行名、列名をもつデータを横に連結した例では、実行結果として「value_1-1」が2回、「value_1-2」が2回…といったように同じ列名が2回ずつ含まれています。
これがどのように処理されるのか?
次回色々と試してみたいと思います。
ということで今回はこんな感じで。
コメント