機械学習ライブラリScikit-learn
前回はseabornライブラリを使って、複雑なグラフを簡単に描く方法を解説しました。
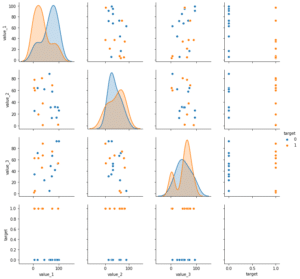
今回は機械学習ライブラリScikit-learn (sklearn)というものを使って、機械学習を体験してみます。
機械学習とは最近色々ニュースで話題になっているAI(人工知能:Artificial intelligence)を作り出す手法の一つだと思ってもらえればいいです。
というよりも私自身もあまり詳しいわけではないので、「データと結果を使ってコンピュータに学習させて判断できるようにする」くらいしか分かっていなかったりします。
とりあえず後はやっていくうちに理解していきましょう。
ということで進めていきましょう。
Scikit-learnのインストール
まずは機械学習ライブラリScikit-learnをインストールしましょう。
Launchpad(ロケットマーク)をクリック。

Anaconda-Navogatorをクリック。

左のメニューの「Environments」をクリック。

真ん中上の「installed」と書かれたプルダウンメニューをクリックして、「Not installed」に変える。
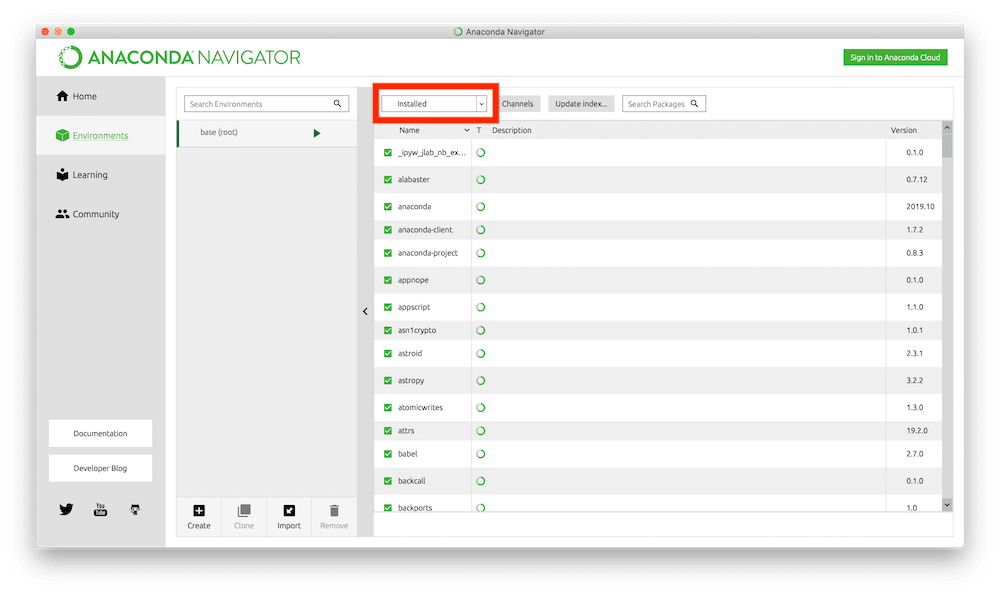
もしまだ「Scikit-learn」がインストールされていなければ、ここに表示されます。
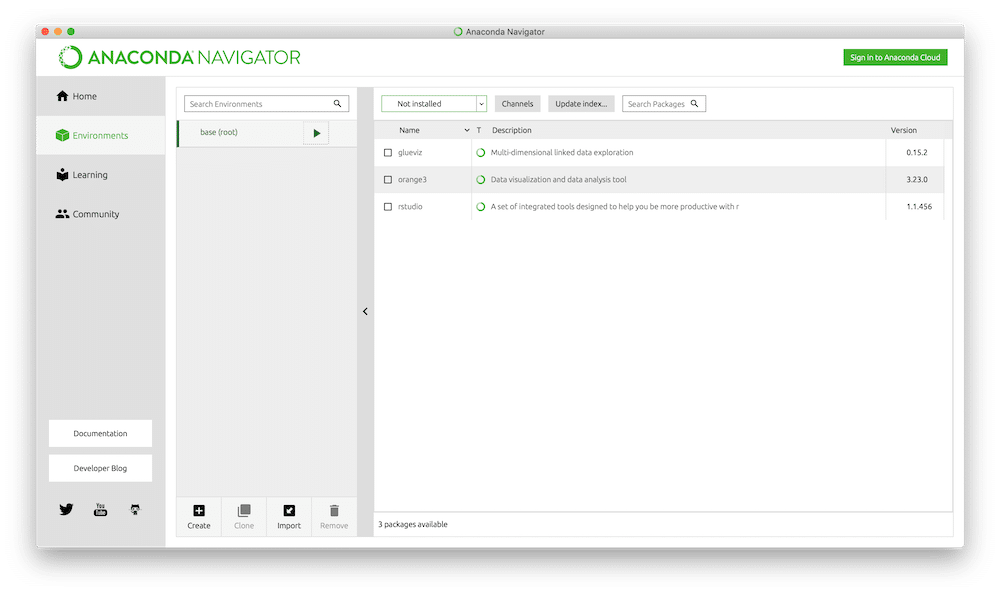
私の場合はもうインストールされているので、「installed」にありました。
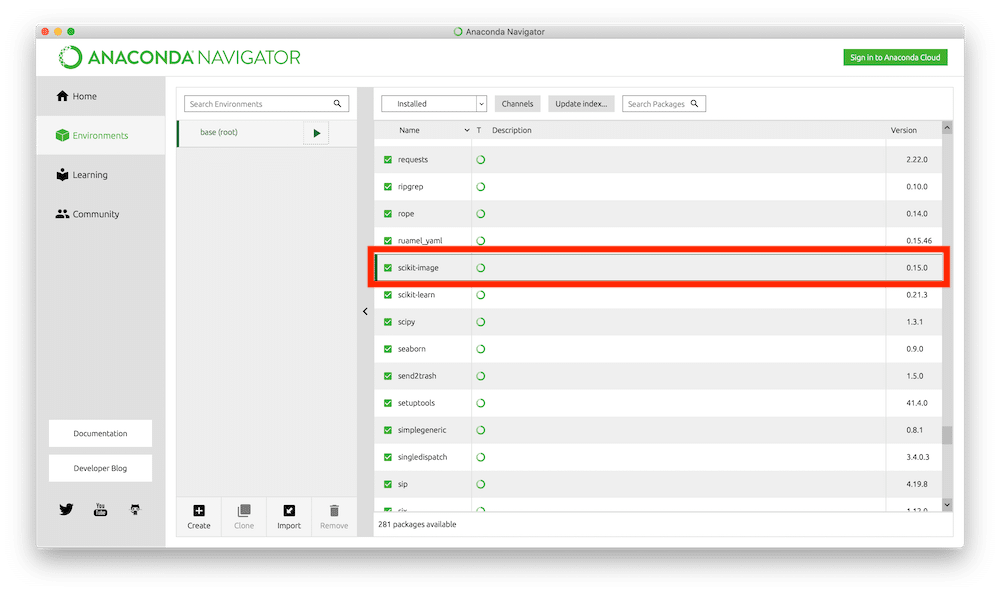
もしインストールされていなかったら、「Scikit-learn」の前にあるチェックボックスにチェックをいれ、右下の「Apply」をクリックします。
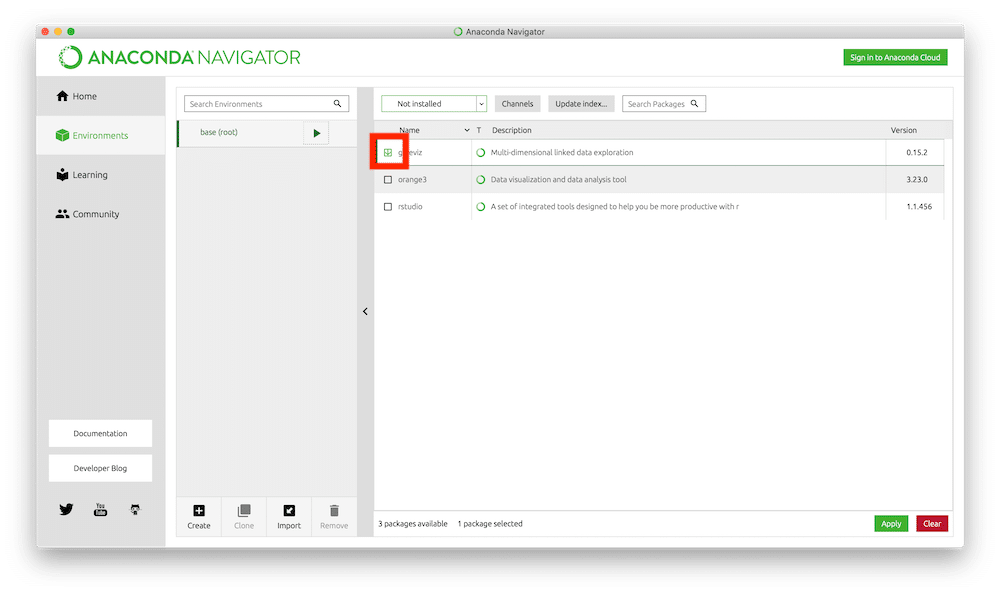
インストールウインドウが出てきますので、右下の「Apply」をクリックします。
これで先ほどの「installed」のリストに「Scikit-learn」があればインストール完了です。
Irisデータのインポート
それでは機械学習を始めていきましょう。
といっても普通、機械学習をするためのデータを持っている人はいませんよね。
そんな人のため、というよりも導入としてScikit-learnの中にいくつかデータが準備されています。
今回はそのうちの一つ、Iris(アヤメ)のデータセットを使って機械学習に触れていきましょう。
まずは次のようにScikit-learnのデータセットをインポートする必要があります。
from sklearn.datasets import load_iris
iris = load_iris()ちなみに「iris = load_iris()」の最初のirisは変数なので、別にdataでも構いません。
「load_iris()」でirisデータセットを読み込み、変数「iris」に格納しているというわけです。
ちゃんと読み込めたかデータセットのキーを確認してみましょう。
今回は次々とセルを変えていきますので、セル番号を記載しておきます。
<セル1>
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.keys())
実行結果
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])まずはこのデータセットの解説が記載されている「DESCR」を見てみます。
<セル2>
print(iris.DESCR)
実行結果
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
(以下略)「Number of Instances:150」というのはデータが150個あるという意味です。
「Number of Attributes:4 numeric」というのは4種類のデータがあるという意味。
その4つが「sepal length:がく片の長さ」、「sepal width:がく片の幅」、「petal length:花びらの長さ」、「petal width:花びらの幅」です。
そして「class」、つまり分類が「Iris-Setosa」、「Iris-Versicolour」、「Iris-Virginica」という3種類のアヤメの種に分類されるというわけです。
ということは今回は4つのデータ「sepal length」「sepal width」「petal length」「petal width」から3種類のアヤメ「Iris-Setosa」「Iris-Versicolour」「Iris-Virginica」のうちどのアヤメなのかを当てるということです。
データの確認
他に格納されているデータも見ておきましょう。
<セル3>
print(iris.data)
実行結果
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
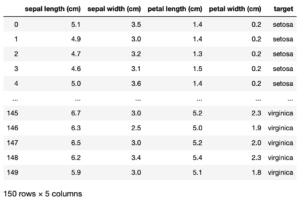
(以下略)これが「sepal length」「sepal width」「petal length」「petal width」の数値データです。
このように分類に使うデータのことを「特徴量」といいます。
<セル4>
print(iris.target)
実行結果
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]これが3種類のアヤメ「Iris-Setosa」「Iris-Versicolour」「Iris-Virginica」を示しています。
名前の代わりに数値データにしてあるようです。
<セル5>
print(iris.target_names)
実行結果
['setosa' 'versicolor' 'virginica']これが3種類のアヤメの名前です。
つまり先ほどの「iris.target」の「0」が「setosa」、「1」が「versicolor」、「2」が「virginica」となります。
<セル6>
print(iris.feature_names)
実行結果
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']これが「がく片の長さ」などの特徴の名前です。
<セル7>
print(iris.filename)
実行結果
/opt/anaconda3/lib/python3.7/site-packages/sklearn/datasets/data/iris.csvこれは今読み込んでいるデータの場所です。
ということで実際、機械学習で用いるデータは、
- iris.data:特徴のデータ
- iris.feature_names:特徴の名前
- iris.target:アヤメの種類のデータ
- iris.target_names:アヤメの種類の名前
の4つです。
さて初めての機械学習ですし、じっくり解説を進めていきたいので、今回はここまでとします。
次回はこのアヤメのデータを使って、機械学習をとりあえず試してみることにします。
ということで今回はこんな感じで。
コメント