機械学習ライブラリScikit-learn
前回、機械学習ライブラリScikit-learnのボストンの住宅価格を予想するのにデータを標準化、正規化をした後、LassoモデルとElasticNetモデルで機械学習をしてみました。
今回は同じようにして標準化、正規化したデータを使って、Ridgeモデル、SVRモデルで機械学習を行ってみます。
ちなみにSVRモデルはこちらの記事で解説したように、オプションで”linear”と”rbf”という二つモデルを選択できるので、今回も両方試してみることにします。
ということでまずはいつも通りデータの読み込みから。
<セル1>
from sklearn.datasets import load_boston
import pandas as pd
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df["MEDV"] = boston.target
df
実行結果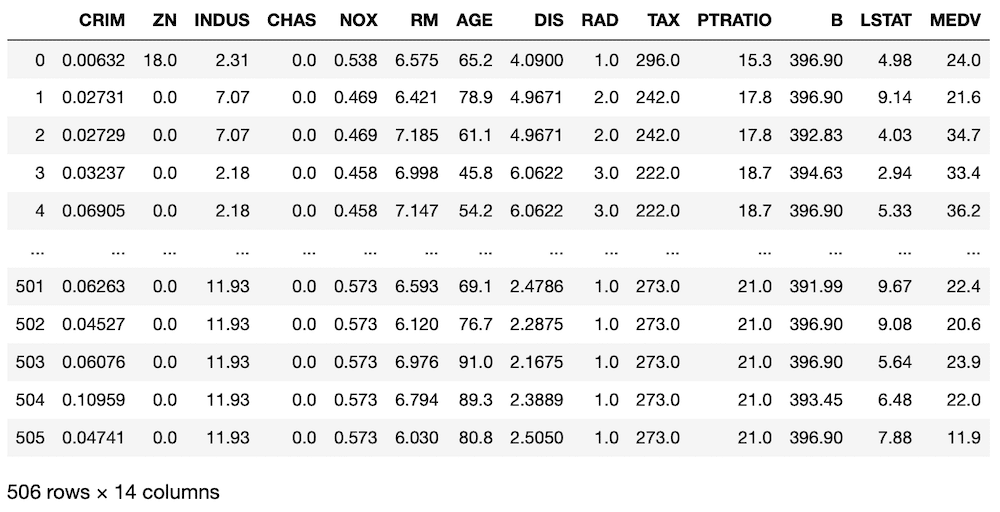
そして前回同様、データを正規化と標準化しておきます。
<セル2>
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
x = df.loc[:, ["CRIM", "RM", "LSTAT"]]
y = df.loc[:, "MEDV"]
std_model = StandardScaler()
x_std = std_model.fit_transform(x)
norm_model = MinMaxScaler()
x_norm = norm_model.fit_transform(x)これで準備は完了です。
比較用のLinearRegressionモデル
前回同様、今回もLinearRegressionモデルを比較用のモデルとして使用します。
ということで前回分かりやすく組み替えたプログラムを基にRidgeモデルとSVRモデルを追加していきます。
そのLinearRegressionモデルのプログラムはこちらです。
<セル3>
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
import numpy as np
trial = 100
pred_lr_score = []; pred_std_lr_score =[]; pred_norm_lr_score = []
for i in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
x_std_train, x_std_test, y_std_train, y_std_test = train_test_split(x_std, y, test_size=0.2, train_size=0.8)
x_norm_train, x_norm_test, y_norm_train, y_norm_test = train_test_split(x_norm, y, test_size=0.2, train_size=0.8)
model_lr = LinearRegression()
model_lr.fit(x_train, y_train)
pred_lr = model_lr.predict(x_test)
pred_lr_score.append(r2_score(y_test, pred_lr))
model_std_lr = LinearRegression()
model_std_lr.fit(x_std_train, y_std_train)
pred_std_lr = model_std_lr.predict(x_std_test)
pred_std_lr_score.append(r2_score(y_std_test, pred_std_lr))
model_norm_lr = LinearRegression()
model_norm_lr.fit(x_norm_train, y_norm_train)
pred_norm_lr = model_norm_lr.predict(x_norm_test)
pred_norm_lr_score.append(r2_score(y_norm_test, pred_norm_lr))
pred_lr_ave = np.average(np.array(pred_lr_score))
pred_std_lr_ave = np.average(np.array(pred_std_lr_score))
pred_norm_lr_ave = np.average(np.array(pred_norm_lr_score))
print(pred_lr_ave, pred_std_lr_ave, pred_norm_lr_ave)
実行結果
0.62531653766934 0.631091439828992 0.6262056101754784これではこのプログラムにRidgeモデルとSVRモデルを組み込んでいいきましょう。
Ridgeモデル、SVRモデルを組み込む
まずはライブラリのインポートです。
今回、RidgeモデルとSVRモデルを組み込むので、そのモデルのライブラリのインポートを行います。
from sklearn.linear_model import Ridge
from sklearn.svm import SVR次にそれぞれのモデルの処理を追加していきます。
ただし最初に書いたように、SVRモデルではさらに”linear”モデルと”rbf”モデルを選択しますので、3つのモデルを組み込むことになります。
まずはRidgeモデルの処理はこんな感じ。
model_rd = Ridge()
model_rd.fit(x_train, y_train)
pred_rd = model_rd.predict(x_test)
pred_rd_score.append(r2_score(y_test, pred_rd))
model_std_rd = Ridge()
model_std_rd.fit(x_std_train, y_std_train)
pred_std_rd = model_std_rd.predict(x_std_test)
pred_std_rd_score.append(r2_score(y_std_test, pred_std_rd))
model_norm_rd = Ridge()
model_norm_rd.fit(x_norm_train, y_norm_train)
pred_norm_rd = model_norm_rd.predict(x_norm_test)
pred_norm_rd_score.append(r2_score(y_norm_test, pred_norm_rd))最初の4行が標準化も正規化もしない処理、真ん中の4行が標準化したデータの処理、下の4行が正規化したデータの処理です。
同じようにSVRモデルも組み込んでいきます。
model_svr_lr = SVR(kernel='linear')
model_svr_lr.fit(x_train, y_train)
pred_svr_lr = model_en.predict(x_test)
pred_svr_lr_score.append(r2_score(y_test, pred_svr_lr))
model_std_svr_lr = SVR(kernel='linear')
model_std_svr_lr.fit(x_std_train, y_std_train)
pred_std_svr_lr = model_std_svr_lr.predict(x_std_test)
pred_std_svr_lr_score.append(r2_score(y_std_test, pred_std_svr_lr))
model_norm_svr_lr = SVR(kernel='linear')
model_norm_svr_lr.fit(x_norm_train, y_norm_train)
pred_norm_svr_lr = model_norm_svr_lr.predict(x_norm_test)
pred_norm_svr_lr_score.append(r2_score(y_norm_test, pred_norm_svr_lr))
model_svr_rbf = SVR(kernel='rbf', gamma="scale")
model_svr_rbf.fit(x_train, y_train)
pred_svr_rbf = model_svr_rbf.predict(x_test)
pred_svr_rbf_score.append(r2_score(y_test, pred_svr_rbf))
model_std_svr_rbf = SVR(kernel='rbf', gamma="scale")
model_std_svr_rbf.fit(x_std_train, y_std_train)
pred_std_svr_rbf = model_std_svr_rbf.predict(x_std_test)
pred_std_svr_rbf_score.append(r2_score(y_std_test, pred_std_svr_rbf))
model_norm_svr_rbf = SVR(kernel='rbf', gamma="scale")
model_norm_svr_rbf.fit(x_norm_train, y_norm_train)
pred_norm_svr_rbf = model_norm_svr_rbf.predict(x_norm_test)
pred_norm_svr_rbf_score.append(r2_score(y_norm_test, pred_norm_svr_rbf))上3つの段落がSVRの”linear”モデル用、下の3つの段落がSVRの”rbf”モデルようです。
後は平均値の計算、表示を加えるとこんな感じになります。
<セル3>
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Ridge
from sklearn.svm import SVR
from sklearn.metrics import r2_score
import numpy as np
trial = 100
pred_lr_score = []; pred_std_lr_score =[]; pred_norm_lr_score = []
pred_rd_score = []; pred_std_rd_score = []; pred_norm_rd_score = []
pred_svr_lr_score = []; pred_std_svr_lr_score = []; pred_norm_svr_lr_score = []
pred_svr_rbf_score = []; pred_std_svr_rbf_score = []; pred_norm_svr_rbf_score = []
for i in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
x_std_train, x_std_test, y_std_train, y_std_test = train_test_split(x_std, y, test_size=0.2, train_size=0.8)
x_norm_train, x_norm_test, y_norm_train, y_norm_test = train_test_split(x_norm, y, test_size=0.2, train_size=0.8)
model_lr = LinearRegression()
model_lr.fit(x_train, y_train)
pred_lr = model_lr.predict(x_test)
pred_lr_score.append(r2_score(y_test, pred_lr))
model_std_lr = LinearRegression()
model_std_lr.fit(x_std_train, y_std_train)
pred_std_lr = model_std_lr.predict(x_std_test)
pred_std_lr_score.append(r2_score(y_std_test, pred_std_lr))
model_norm_lr = LinearRegression()
model_norm_lr.fit(x_norm_train, y_norm_train)
pred_norm_lr = model_norm_lr.predict(x_norm_test)
pred_norm_lr_score.append(r2_score(y_norm_test, pred_norm_lr))
model_rd = Ridge()
model_rd.fit(x_train, y_train)
pred_rd = model_rd.predict(x_test)
pred_rd_score.append(r2_score(y_test, pred_rd))
model_std_rd = Ridge()
model_std_rd.fit(x_std_train, y_std_train)
pred_std_rd = model_std_rd.predict(x_std_test)
pred_std_rd_score.append(r2_score(y_std_test, pred_std_rd))
model_norm_rd = Ridge()
model_norm_rd.fit(x_norm_train, y_norm_train)
pred_norm_rd = model_norm_rd.predict(x_norm_test)
pred_norm_rd_score.append(r2_score(y_norm_test, pred_norm_rd))
model_svr_lr = SVR(kernel='linear')
model_svr_lr.fit(x_train, y_train)
pred_svr_lr = model_en.predict(x_test)
pred_svr_lr_score.append(r2_score(y_test, pred_svr_lr))
model_std_svr_lr = SVR(kernel='linear')
model_std_svr_lr.fit(x_std_train, y_std_train)
pred_std_svr_lr = model_std_svr_lr.predict(x_std_test)
pred_std_svr_lr_score.append(r2_score(y_std_test, pred_std_svr_lr))
model_norm_svr_lr = SVR(kernel='linear')
model_norm_svr_lr.fit(x_norm_train, y_norm_train)
pred_norm_svr_lr = model_norm_svr_lr.predict(x_norm_test)
pred_norm_svr_lr_score.append(r2_score(y_norm_test, pred_norm_svr_lr))
model_svr_rbf = SVR(kernel='rbf', gamma="scale")
model_svr_rbf.fit(x_train, y_train)
pred_svr_rbf = model_svr_rbf.predict(x_test)
pred_svr_rbf_score.append(r2_score(y_test, pred_svr_rbf))
model_std_svr_rbf = SVR(kernel='rbf', gamma="scale")
model_std_svr_rbf.fit(x_std_train, y_std_train)
pred_std_svr_rbf = model_std_svr_rbf.predict(x_std_test)
pred_std_svr_rbf_score.append(r2_score(y_std_test, pred_std_svr_rbf))
model_norm_svr_rbf = SVR(kernel='rbf', gamma="scale")
model_norm_svr_rbf.fit(x_norm_train, y_norm_train)
pred_norm_svr_rbf = model_norm_svr_rbf.predict(x_norm_test)
pred_norm_svr_rbf_score.append(r2_score(y_norm_test, pred_norm_svr_rbf))
pred_lr_ave = np.average(np.array(pred_lr_score))
pred_std_lr_ave = np.average(np.array(pred_std_lr_score))
pred_norm_lr_ave = np.average(np.array(pred_norm_lr_score))
pred_rd_ave = np.average(np.array(pred_rd_score))
pred_std_rd_ave = np.average(np.array(pred_std_rd_score))
pred_norm_rd_ave = np.average(np.array(pred_norm_rd_score))
pred_svr_lr_ave = np.average(np.array(pred_svr_lr_score))
pred_std_svr_lr_ave = np.average(np.array(pred_std_svr_lr_score))
pred_norm_svr_lr_ave = np.average(np.array(pred_norm_svr_lr_score))
pred_svr_rbf_ave = np.average(np.array(pred_svr_rbf_score))
pred_std_svr_rbf_ave = np.average(np.array(pred_std_svr_rbf_score))
pred_norm_svr_rbf_ave = np.average(np.array(pred_norm_svr_rbf_score))
print(pred_lr_ave, pred_std_lr_ave, pred_norm_lr_ave, pred_rd_ave, pred_std_rd_ave, pred_norm_rd_ave, pred_svr_lr_ave, pred_std_svr_lr_ave, pred_norm_svr_lr_ave, pred_svr_rbf_ave, pred_std_svr_rbf_ave, pred_norm_svr_rbf_ave)だいぶ長くなってしまいましたが、これでプログラムの方は終了です。
このプログラムを使って、分析してみましょう。
Ridgeモデル、SVRモデルに対する標準化、正規化の効果を見てみる
それではRidgeモデル、SVRモデルに対する標準化、正規化の効果を検討してみましょう。
いつも通りプログラムで100回試行して平均値を出し、それを5回試してみます。
| 標準化 or 正規化 | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 | |
| LinearRegression | なし | 0.63279 | 0.63513 | 0.62773 | 0.63113 | 0.62727 |
| LinearRegression | 標準化 | 0.63688 | 0.63244 | 0.60750 | 0.61951 | 0.63610 |
| LinearRegression | 正規化 | 0.62583 | 0.63386 | 0.63390 | 0.62354 | 0.63466 |
| Ridge | なし | 0.63296 | 0.63523 | 0.62789 | 0.63127 | 0.62739 |
| Ridge | 標準化 | 0.63692 | 0.63253 | 0.60766 | 0.61962 | 0.63618 |
| Ridge | 正規化 | 0.62588 | 0.63329 | 0.63347 | 0.62676 | 0.63333 |
| SVR liner | なし | 0.62792 | 0.63280 | 0.62395 | 0.62263 | 0.62129 |
| SVR liner | 標準化 | 0.62511 | 0.62161 | 0.59314 | 0.60226 | 0.62539 |
| SVR liner | 正規化 | 0.51381 | 0.52113 | 0.52473 | 0.52715 | 0.51042 |
| SVR rbf | なし | 0.58457 | 0.57878 | 0.57156 | 0.57537 | 0.57568 |
| SVR rbf | 標準化 | 0.71911 | 0.72245 | 0.70059 | 0.70598 | 0.71844 |
| SVR rbf | 正規化 | 0.71198 | 0.73217 | 0.72606 | 0.72414 | 0.72570 |
今回もデータが膨大になってしまいましたので、前回同様色分けしてみましょう。
標準化、正規化していないデータを基準として、標準化、正規化をしたデータがよくなった場合は青色、悪くなった場合は赤色で示してみましす。
ということでまずはLinearRegressionモデルから。
| 標準化 or 正規化 | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 | |
| LinearRegression | なし | 0.63279 | 0.63513 | 0.62773 | 0.63113 | 0.62727 |
| LinearRegression | 標準化 | 0.63688 | 0.63244 | 0.60750 | 0.61951 | 0.63610 |
| LinearRegression | 正規化 | 0.62583 | 0.63386 | 0.63390 | 0.62354 | 0.63466 |
LinearRegressionモデルの場合、標準化すると2:3でわずかに標準化、正規化しない方がいいという結果になりました。
しかし値を見てみるとほとんど差がないので、これまで同様標準化、正規化の効果はあまりみられていないといっていいでしょう。
次にRidgeモデルです。
| 標準化 or 正規化 | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 | |
| Ridge | なし | 0.63296 | 0.63523 | 0.62789 | 0.63127 | 0.62739 |
| Ridge | 標準化 | 0.63692 | 0.63253 | 0.60766 | 0.61962 | 0.63618 |
| Ridge | 正規化 | 0.62588 | 0.63329 | 0.63347 | 0.62676 | 0.63333 |
Ridgeモデルの場合、2:3でわずかに標準化、正規化しない方がいいという結果になりました。
しかしこちらも値的にはほとんど差がないので、標準化、正規化の効果はなかったとみるのが正しそうです。
最後にSVRモデルです。
| 標準化 or 正規化 | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 | |
| SVR liner | なし | 0.62792 | 0.63280 | 0.62395 | 0.62263 | 0.62129 |
| SVR liner | 標準化 | 0.62511 | 0.62161 | 0.59314 | 0.60226 | 0.62539 |
| SVR liner | 正規化 | 0.51381 | 0.52113 | 0.52473 | 0.52715 | 0.51042 |
| SVR rbf | なし | 0.58457 | 0.57878 | 0.57156 | 0.57537 | 0.57568 |
| SVR rbf | 標準化 | 0.71911 | 0.72245 | 0.70059 | 0.70598 | 0.71844 |
| SVR rbf | 正規化 | 0.71198 | 0.73217 | 0.72606 | 0.72414 | 0.72570 |
SVRのlinearモデルでは1:4で標準化しない方がいい、そして0:5で正規化しない方がいいという結果になりました。
値を見てみると標準化の方はわずかに悪くなっている回が多いので、効果がないか、少し悪影響があるくらいだと考えられます。
しかし正規化の方は値もかなり悪くなっており、相性が悪いことが分かります。
SVRのrbfモデルでは、標準化も正規化も5:0でよくなっています。
また値も0.57程度から、0.72程度まで一気に改善されています。
この0.72という値は他のモデルでは出てきていないくらい良い数値となっており、標準化、正規化で大幅に改善されたと見ていいでしょう。
また5回ともなのでまぐれ当たりではないとも言えます。
標準化、正規化で改善するモデルはないんじゃないかとヒヤヒヤしましたが、何とかなって良かったです。
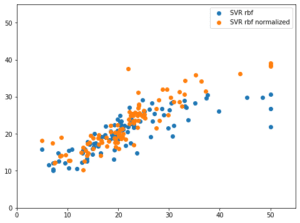
せっかく改善されるモデルも見つかったことなので、次回は正解の値と予想された値をプロットしてみて、スコアが違うとどれくらいの予想値の違いが出てくるのか可視化してみたいと思います。
ということで今回はこんな感じで。
コメント