tweepy
これまでにPythonのTwitter API制御ライブラリtweepyを使って色々なことをしてきました。
ただ色々なことができるようになったのはいいのですが、反面APIの利用回数制限に引っかかる場面が出てきました。
APIの利用回数制限は、APIの利用者がAPIを使いすぎてサーバーに負荷をかけすぎないようにするためにあります。
TwitterのAPI利用回数制限に関しては、こちらのページをご覧ください。

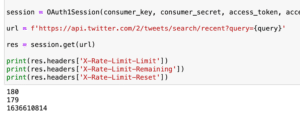
例えばこちらの記事で使用した特定のワードを検索する「api.search(q=’検索ワード’)」の場合は15分間に180回使用できます。
この回数制限をオーバーしてしまうと、特定の時間(大体のものは15分、時に3時間など)はAPIを使用できなくなってしまいます。
先ほどの記事では1回プログラムを実行すると「api.search(q=’検索ワード’)」を使用するのは1回だけです。
と言うことはこのプログラムを15分間に180回しようしない限りは回数制限に引っかからないはずです。
しかし数回プログラムを実行しただけで回数制限に引っかかり15分使用不可のペナルティを受けることが多々ありました。
つまりtweepy内で自分が意識していない箇所でAPIを使っているのではないかと考えられます。
その原因を追求するためにも、どのプログラムでどのAPIのコマンドを何回使ったのかというデータを取得する必要が出てきたので、やってみたと言うのが今回のお話です。
それでは始めていきましょう。
プログラム全体
まずはプログラム全体をお見せします。
import tweepy
consumer_key = ' consumer key '
consumer_secret = ' consumer secret '
access_token = ' access token '
access_token_secret = ' access token secret '
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
rate_limit = api.rate_limit_status()
for category in rate_limit['resources']:
# print(category)
for small_cat in rate_limit['resources'][category]:
# print(small_cat)
data = rate_limit['resources'][category][small_cat]
if data['limit'] != data['remaining']:
print(f'BAD {category}-{small_cat} {data["remaining"]}/{data["limit"]} {data["reset"]}')
else:
print(f' OK {category}-{small_cat} {data["remaining"]}/{data["limit"]} {data["reset"]}')と言うことで上から解説していきましょう。
設定部分+認証部分
まずは設定部分と認証部分です。
import tweepy
consumer_key = ' consumer key '
consumer_secret = ' consumer secret '
access_token = ' access token '
access_token_secret = ' access token secret '
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)特にこれまでと大きな違いはありません。
ただ一点「api = tweepy.API(auth)」の部分で「wait_on_rate_limit = True」は外しています。
正しいかどうか不明ですが、今回使用する使用回数を確認するコマンドに関しては、使用回数制限はない(180回/15分という説も?)ようなので、使用回数制限に引っかかった際、リセットされるまでの時間待つためのこのオプションは必要ないということです。
使用回数取得と表示の部分
次に使用回数を取得し、表示していく部分です。
rate_limit = api.rate_limit_status()
for category in rate_limit['resources']:
for small_cat in rate_limit['resources'][category]:
data = rate_limit['resources'][category][small_cat]
if data['limit'] != data['remaining']:
print(f'BAD {category}-{small_cat} {data["remaining"]}/{data["limit"]} {data["reset"]}')
else:
print(f' OK {category}-{small_cat} {data["remaining"]}/{data["limit"]} {data["reset"]}')まず使用可能回数、残り使用回数、リセットまでの時間を取得するためのコマンドは「api.rate_limit_status()」です。
これをこんなふうに単純に実行すると、なかなか難解なデータが返ってきます。
rate_limit = api.rate_limit_status()
print(rate_limit)
実行結果
{'rate_limit_context': {'access_token': ' access token'},
'resources': {'lists': {'/lists/list': {'limit': 15, 'remaining': 15, 'reset': 1636583574},
'/lists/:id/tweets&GET': {'limit': 900, 'remaining': 900, 'reset': 1636583574},
'/lists/:id/followers&GET': {'limit': 180, 'remaining': 180, 'reset': 1636583574},
'/lists/memberships': {'limit': 75, 'remaining': 75, 'reset': 1636583574},
'/lists/:id&DELETE': {'limit': 300, 'remaining': 300, 'reset': 1636583574},
'/lists/subscriptions': {'limit': 15, 'remaining': 15, 'reset': 1636583574},
'/lists/members': {'limit': 900, 'remaining': 900, 'reset': 1636583574},
(以下略)分かることは色々なコマンドがあって、その中に「limit」、「remaining」、「reset」があることです。
これらがそれぞれ「使用可能回数」、「残り回数」「リセットまでの時間」となります。
ちなみにリセットまでの時間はエポック秒(UNIX秒)と呼ばれるもので1970年1月1日午前0時0分0秒を基準として、そこからの経過時間として表記する方法です。
こちらに関してはまた別の機会に解説していきたいと思います。
今回は通常の時間に変更せずにとりあえず表示するだけにしておきます。
もし通常の時間に変換してみたいという方はこちらのサイトで試してみてください。
何はともあれ、このままではデータが見づらいので、変換しているのが次の部分です。
for category in rate_limit['resources']:
for small_cat in rate_limit['resources'][category]:
data = rate_limit['resources'][category][small_cat]
if data['limit'] != data['remaining']:
print(f'BAD {category}-{small_cat} {data["remaining"]}/{data["limit"]} {data["reset"]}')
else:
print(f' OK {category}-{small_cat} {data["remaining"]}/{data["limit"]} {data["reset"]}')ここを理解するにはまずデータの中に何が入っているか知る必要があります。
rate_limit_status()で取得できるデータの確認
ということでメインのプログラムとは別に内容を確認してみましょう。
print(rate_limit.keys())
実行結果
dict_keys(['rate_limit_context', 'resources'])rate_limitの中には「rate_limit_context」と「resources」が含まれます。
「rate_limit_context」にはアクセストークンが含まれます。
今回取得したい使用回数に関しては「resources」に含まれますので、こちらの中身を見てみましょう。
print(rate_limit['resources'].keys())
実行結果
dict_keys(['lists', 'application', 'mutes', 'verify', 'admin_users', 'live_video_stream',
'friendships', 'guide', 'auth', 'compliance', 'paseto', 'blocks', 'geo', 'users', 'teams',
'followers', 'collections', 'permissions', 'tweets&POST', 'statuses', 'custom_profiles',
'webhooks', 'contacts', 'labs', 'i', 'tweet_prompts', 'moments',
'limiter_scalding_report_creation', 'fleets', 'help', 'feedback', 'business_experience',
'graphql&POST', 'friends', 'sandbox', 'drafts', 'direct_messages', 'media', 'traffic',
'strato', 'account_activity', 'account', 'safety', 'favorites', 'lists&POST', 'device',
'tweets', 'saved_searches', 'oauth', 'search', 'trends', 'live_pipeline', 'graphql'])とまぁこんな感じで色々な項目が含まれます。
さらに中身を見てみましょう。
とりあえず一番最初の「lists」を見てみます。
print(rate_limit['resources']['lists'].keys())
実行結果
dict_keys(['/lists/list', '/lists/:id/tweets&GET', '/lists/:id/followers&GET',
'/lists/memberships', '/lists/:id&DELETE', '/lists/subscriptions', '/lists/members',
'/lists/:id&GET', '/lists/subscribers/show', '/lists/:id&PUT', '/lists/show',
'/lists/ownerships', '/lists/:id/members/:user_id&DELETE', '/lists/subscribers',
'/lists/:id/members&POST', '/lists/:id/members&GET', '/lists/members/show', '/lists/statuses'])これまた色々項目が出てきます。
さらに最初の「/lists/list」を見てみましょう。
print(rate_limit['resources']['lists']['/lists/list'].keys())
実行結果
dict_keys(['limit', 'remaining', 'reset'])ここでやっと「limit」、「remaining」、「reset」が出てきました。
ということでどうやら「大きなカテゴリー>小さなカテゴリー(直接のコマンド?)>使用回数データ」という形になっているようです。
元に戻って取得データの表示
データの構造が分かれば、データ表示の部分を紐解くことができます。
for category in rate_limit['resources']:
for small_cat in rate_limit['resources'][category]:
data = rate_limit['resources'][category][small_cat]
if data['limit'] != data['remaining']:
print(f'BAD {category}-{small_cat} {data["remaining"]}/{data["limit"]} {data["reset"]}')
else:
print(f' OK {category}-{small_cat} {data["remaining"]}/{data["limit"]} {data["reset"]}')最初の部分は使用回数制限のデータに到達するまでfor文を使ってデータに潜っていっています。
そして最後に取得した使用回数のデータを変数「data」に格納しています。
for category in rate_limit['resources']:
for small_cat in rate_limit['resources'][category]:
data = rate_limit['resources'][category][small_cat]if data['limit'] != data['remaining']:
print(f'BAD {category}-{small_cat} {data["remaining"]}/{data["limit"]} {data["reset"]}')
else:
print(f' OK {category}-{small_cat} {data["remaining"]}/{data["limit"]} {data["reset"]}')取得した使用回数のデータで使用可能回数である「limit」と残り使用回数である「remaining」が異なっている場合、つまり使用して残り使用回数が減っている場合の出力と、それ以外、つまり残り使用回数が減っていない場合で出力を変えることで、どのコマンドを使ったのか分かりやすくしようとしています。
そして実行するとこんな感じの出力が得られます。
実行結果
OK lists-/lists/list 15/15 1636583574
OK lists-/lists/:id/tweets&GET 900/900 1636583574
OK lists-/lists/:id/followers&GET 180/180 1636583574
OK lists-/lists/memberships 75/75 1636583574
OK lists-/lists/:id&DELETE 300/300 1636583574
OK lists-/lists/subscriptions 15/15 1636583574
OK lists-/lists/members 900/900 1636583574
OK lists-/lists/:id&GET 75/75 1636583574
OK lists-/lists/subscribers/show 15/15 1636583574
OK lists-/lists/:id&PUT 300/300 1636583574
OK lists-/lists/show 75/75 1636583574
OK lists-/lists/ownerships 15/15 1636583574
(以下略)なかなかみやすい出力になったと思います。
で色々試していたのですが、ここで問題が起きました。
問題:残り使用回数が減らない?!
他のtweepyのプログラムを実行した上で、このプログラムを実行することで、どのコマンドを使っているのか確認しようとしたのですが、どうも残り使用回数が減っているコマンドが見当たりません。
しかし他のtweepyのプログラムを実行していると、確かに利用回数制限に引っかかります。
で、なんでだろうと調べているとTwitterのデベロッパーフォーラムにこんな質問がありました。
簡単に解説すると、今回と同じように「rate_limit_status()」で取得した残り使用回数が減らない、でも制限に引っかかるという問題が他の人にも起こっているようです。
そしてその解答としては「いつもは正しいんだけど、今はエラーが返ってきてて、正しくないようだ」、「Twitterの中の人がこの質問を見て直してくれるか、報告して直してもらうように頼むのがいいね」といった感じでした。
つまりTwitter側に何らかの問題が起こっていて、正しい値を取得できないことがあるということでした。
とりあえずまた時間を置いて試してみることにします。
次回はせっかくなので違うやり方で使用回数の情報を取得してみたいと思います。
ではでは今回はこんな感じで。
コメント