Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」の「タイタニック号乗客の生存予測」のデータセットのNameの敬称の年齢分布を表示してみました。
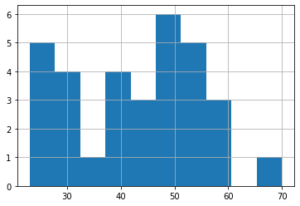
今回は敬称の解析結果をもとにAgeの欠損値を修正し、機械学習・予想を行い、Kaggleにデータを提出してみましょう。
ということでまずはデータの読み込みとこれまでの修正を行っていきます。
<セル1>
import pandas as pd
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
train.loc[train["Sex"] == "male", "Sex"] = 0
train.loc[train["Sex"] == "female", "Sex"] = 1
test.loc[test["Sex"] == "male", "Sex"] = 0
test.loc[test["Sex"] == "female", "Sex"] = 1
test.loc[test["Fare"].isnull() == True, "Fare"] = 7.8875
train.loc[train["Embarked"].isnull() == True, "Embarked"] = "S"
train.loc[train["Embarked"] == "S", "Embarked"] = 0
train.loc[train["Embarked"] == "C", "Embarked"] = 1
train.loc[train["Embarked"] == "Q", "Embarked"] = 2
test.loc[test["Embarked"] == "S", "Embarked"] = 0
test.loc[test["Embarked"] == "C", "Embarked"] = 1
test.loc[test["Embarked"] == "Q", "Embarked"] = 2
all_data = pd.concat([train.drop(columns = "Survived"), test])
all_data
実行結果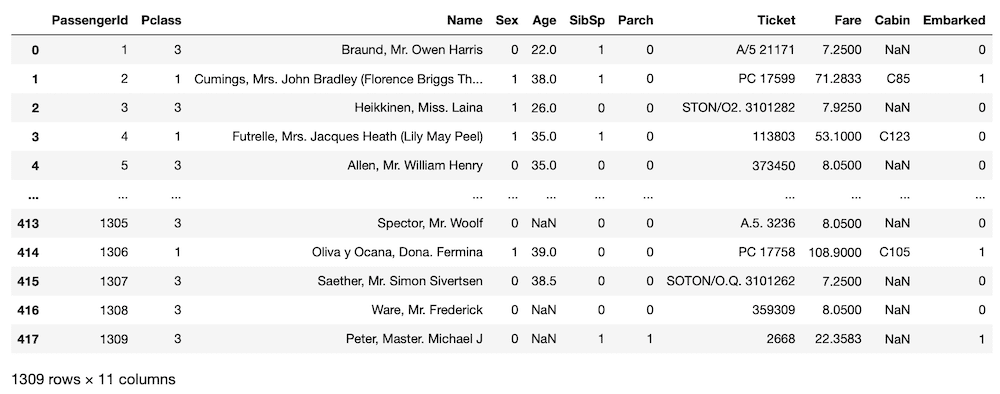
それでは始めていきましょう。
敬称を解析し、数値に置き換える
まずはNameの中にある敬称を解析し、数値データに置き換えます。
とは言ってもここは前回プログラミングしているので、前回のまま使っていきましょう。
<セル2>
title_list = []
for name in all_data["Name"]:
for name_split in name.split():
if name_split.endswith(".") == True:
if name_split != "L.":
title_list.append(name_split)
title_unique = set(title_list)
print(title_unique)
実行結果
{'Sir.', 'Don.', 'Ms.', 'Capt.', 'Dona.', 'Miss.', 'Major.', 'Mrs.', 'Col.', 'Jonkheer.', 'Rev.', 'Mme.', 'Master.', 'Lady.', 'Countess.', 'Dr.', 'Mlle.', 'Mr.'}<セル3>
title_num = []
for title in title_list:
if title == "Mr.":
title_num.append(0)
elif title == "Miss.":
title_num.append(1)
elif title == "Mrs.":
title_num.append(2)
elif title == "Master.":
title_num.append(3)
else:
title_num.append(4)
all_data["title"] = title_num
all_data
実行結果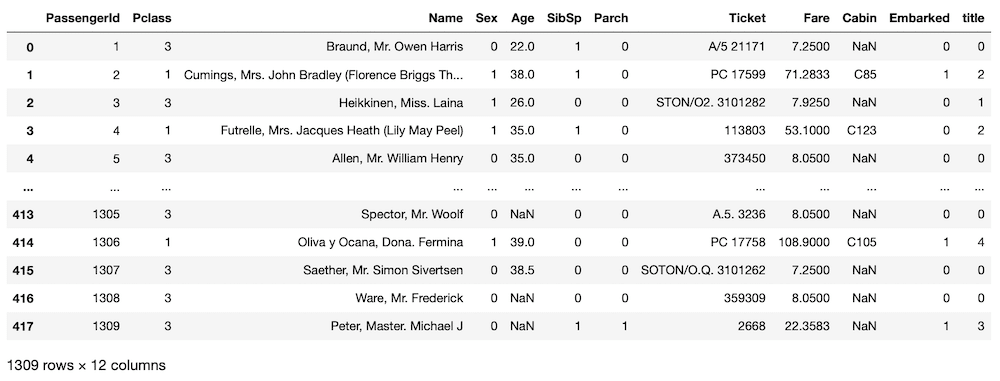
これで全データの敬称を数字に置き換え、新たな列として追加できました。
Ageの欠損値を修正する
ここから訓練用データセット、テスト用データセットのAgeの欠損値を修正していきます。
基本的にはこちらの記事でやったように重みありのランダム値を使って修正していきます。
ただし今回は敬称において、別の重み(年齢分布)を使っていくため、少し難易度が上がっています。
まずはAgeの欠損値を敬称別の年齢分布を重みとして修正するプログラム全体を見てみましょう。
<セル4>
import numpy as np
import random
titleno = [0, 1, 2, 3, 4]
for t_num in titleno:
age_values = all_data[all_data["title"] == t_num]["Age"].value_counts()
age_values = age_values.sort_index()
age_values = np.array(age_values)
age_list = all_data[all_data["title"] == t_num]["Age"].unique()
age_list = np.sort(age_list)
random_age_list = random.choices(age_list[:-1], k = len(all_data), weights = age_values)
random_age_list = np.array(random_age_list)
random_list_no = 0
for i in range(len(train)):
if np.isnan(train.iloc[i, 5]) == True:
if train.iloc[i, 11] == t_num:
train.iloc[i, 5] = random_age_list[random_list_no]
random_list_no = random_list_no + 1
for i in range(len(test)):
if np.isnan(test.iloc[i, 4]) == True:
if test.iloc[i, 10] == t_num:
test.iloc[i, 4] = random_age_list[random_list_no]
random_list_no = random_list_no + 1
実行結果では上から順に見ていきましょう。
最初は「numpy」と「random」のインポート
import numpy as np
import random次に各敬称ごとに「重み」に使用する年齢データを作成していきます。
titleno = [0, 1, 2, 3, 4]
for t_num in titleno:
age_values = all_data[all_data["title"] == t_num]["Age"].value_counts()
age_values = age_values.sort_index()
age_values = np.array(age_values)
age_list = all_data[all_data["title"] == t_num]["Age"].unique()
age_list = np.sort(age_list)「titleno = [0, 1, 2, 3, 4]」として、titleで出現する5つの数字のリストを作成し、「for t_num in titleno:」とすることで、その数字を順番に「t_num」に格納していきます。
そして「age_values = all_data[all_data[“title”] == t_num][“Age”].value_counts()」で「t_num」とTitleの列の数字が一致したデータのみを取りつつ、それぞれの値に対する個数を取得します。
「age_values = age_values.sort_index()」で年齢順に並び替え、「age_values = np.array(age_values)」でnumpyの配列に変換します。
次に「age_list = all_data[all_data[“title”] == t_num][“Age”].unique()」で「t_num」とTitleの列の数字が一致したデータのみを取りつつ、年齢のリストを作成します。
そして「age_list = np.sort(age_list)」で年齢順に並び替えます。
次にランダム値のリストを作成します。
random_age_list = random.choices(age_list[:-1], k = len(all_data), weights = age_values)
random_age_list = np.array(random_age_list)作成したランダム値を訓練用データセットとテスト用データセットのAgeの欠損値に置き換えていきます。
random_list_no = 0
for i in range(len(train)):
if np.isnan(train.iloc[i, 5]) == True:
if train.iloc[i, 11] == t_num:
train.iloc[i, 5] = random_age_list[random_list_no]
random_list_no = random_list_no + 1
for i in range(len(test)):
if np.isnan(test.iloc[i, 4]) == True:
if test.iloc[i, 10] == t_num:
test.iloc[i, 4] = random_age_list[random_list_no]
random_list_no = random_list_no + 1ちなみに前回と比較すると「if train.iloc[i, 11] == t_num:」もしくは「if test.iloc[i, 10] == t_num:」という条件分岐が入っており、ここでTitleの選別をしています。
これでテスト用データセットと訓練用データセットのAgeの欠損値が修正されているはずです。
ということで確認してみましょう。
<セル5>
train.isnull().sum()
実行結果
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 0
dtype: int64<セル6>
test.isnull().sum()
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 327
Embarked 0
dtype: int64それぞれAgeの欠損値の個数が「0」になっており、修正されていることが確認できました。
機械学習・予測 その1
ということで機械学習・予測、そしてKaggleへの提出をしてみましょう。
<セル7>
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x = train.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare", "Embarked", "Age"]]
y = train["Survived"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC(max_iter=10000000)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.8268156424581006これまでのここでのスコアはこんな感じです。
| 修正項目 | 機械学習スコア |
| 初期(修正なし) | 0.79330 |
| Fare | 0.80447 |
| Embarked | 0.83240 |
| Age(平均値) | 0.81564 |
| Age(ランダム値) | 0.74860 |
| Age(重みありランダム値) | 0.77095 |
修正しているとは言え、なかなか綺麗に上がっていかないものですね。
<セル8>
x_testset = test.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare", "Embarked", "Age"]]
pred = model.predict(x_testset)
submit_data = pd.DataFrame()
submit_data["PassengerId"] = test["PassengerId"]
submit_data["Survived"] = pred
submit_data = submit_data.set_index("PassengerId")
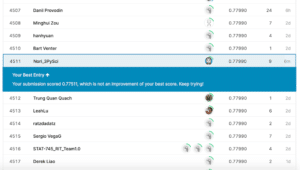
submit_data.to_csv("./submit_data_Age_title_1.csv")これでKaggleに提出してみたところ、これまでの最高値「0.77990」は越えられませんでした。
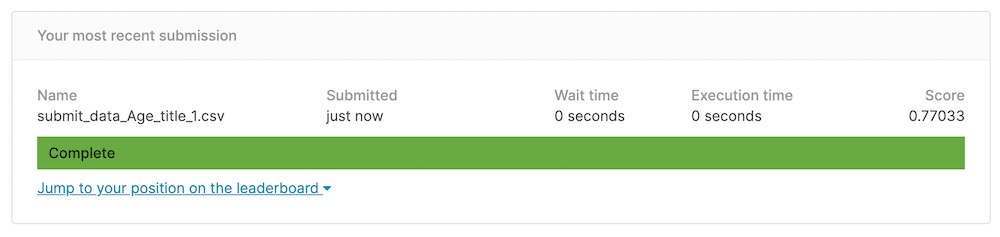
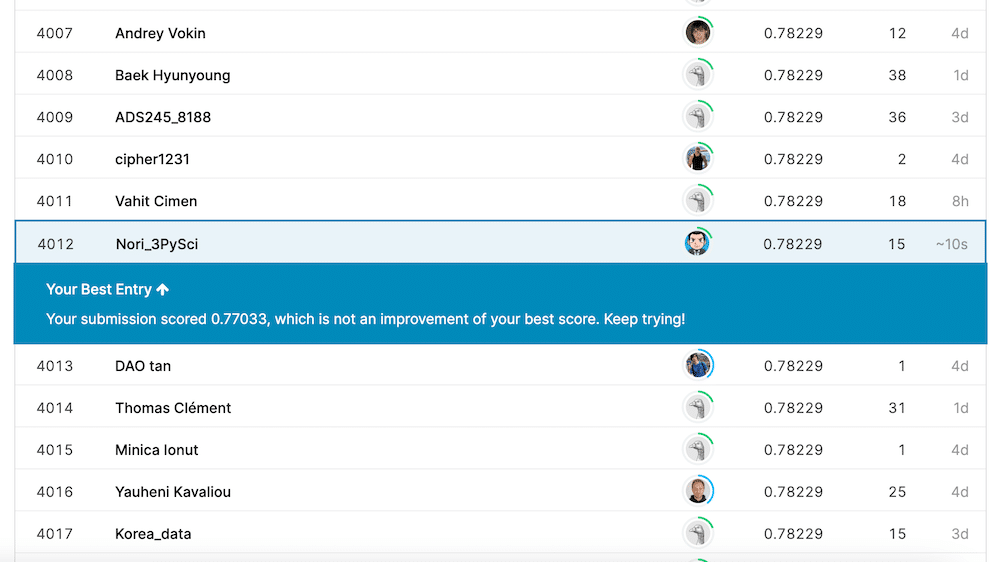
上の図では最高値が「0.78229」になっていますが、これは色々試していたら出てしまった値なので、ちょっと見なかったことにしてください…
ただ今回はもう一つ策があるので試してみましょう。
機械学習・予測 その2
もう一つの策とは「Title」の情報も機械学習のための特徴量として使用してしまうということです。
例えばDr.やSir. など社会的立場の高い人たちは先に脱出ボートに乗ることができたという可能性も考えられ、生存に影響するかもしれません。
ということでまずはTitleの情報を訓練用データセット、テスト用データセットに付け加えていきます。
<セル9>
title_list_train = []
for name in train["Name"]:
for name_split in name.split():
if name_split.endswith(".") == True:
if name_split != "L.":
title_list_train.append(name_split)
title_num_train = []
for title in title_list_train:
if title == "Mr.":
title_num_train.append(0)
elif title == "Miss.":
title_num_train.append(1)
elif title == "Mrs.":
title_num_train.append(2)
elif title == "Master.":
title_num_train.append(3)
else:
title_num_train.append(4)
train["title"] = title_num_train<セル10>
title_list_test = []
for name in test["Name"]:
for name_split in name.split():
if name_split.endswith(".") == True:
if name_split != "L.":
title_list_test.append(name_split)
title_num_test = []
for title in title_list_test:
if title == "Mr.":
title_num_test.append(0)
elif title == "Miss.":
title_num_test.append(1)
elif title == "Mrs.":
title_num_test.append(2)
elif title == "Master.":
title_num_test.append(3)
else:
title_num_test.append(4)
test["title"] = title_num_testそれでは機械学習・予想をしていきましょう。
<セル11>
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x = train.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare", "Embarked", "Age", "title"]]
y = train["Survived"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC(max_iter=10000000)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.8100558659217877これまでのデータと比較するとこんな感じです。
| 修正項目 | 機械学習スコア |
| 初期(修正なし) | 0.79330 |
| Fare | 0.80447 |
| Embarked | 0.83240 |
| Age(平均値) | 0.81564 |
| Age(ランダム値) | 0.74860 |
| Age(重みありランダム値) | 0.77095 |
| Age(敬称による重みありランダム値) | 0.82682 |
<セル12>
x_testset = test.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare", "Embarked", "Age", "title"]]
pred = model.predict(x_testset)
submit_data = pd.DataFrame()
submit_data["PassengerId"] = test["PassengerId"]
submit_data["Survived"] = pred
submit_data = submit_data.set_index("PassengerId")
submit_data.to_csv("./submit_data_Age_title_2.csv")それではデータを提出してみましょう。
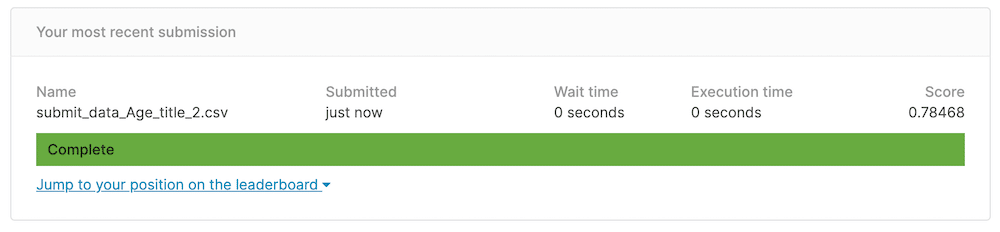
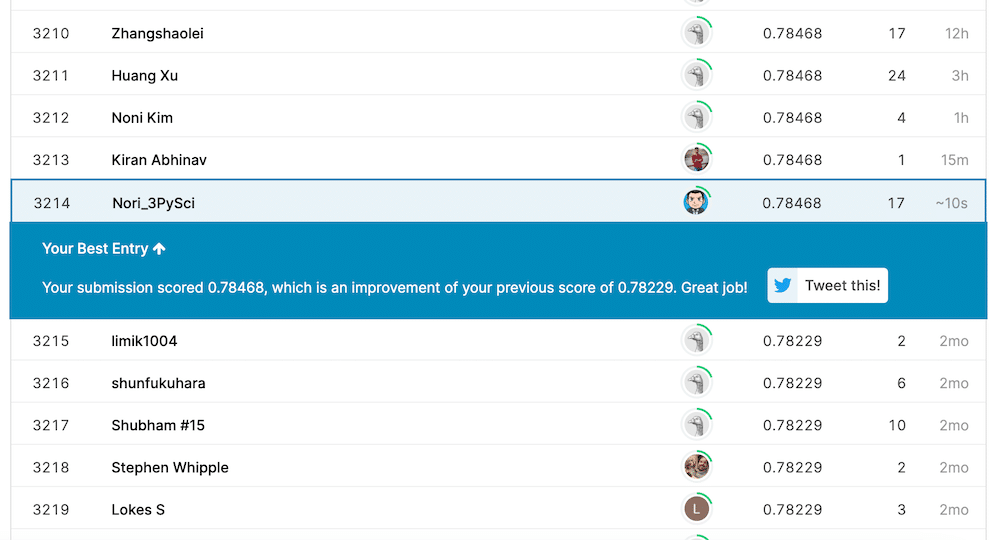
これまでの最高値「0.77990」を越え「0.78468」になりました。
でもここまで修正してきてもなかなか8割の大台には乗ってきませんね。
なかなか手詰まりになってきたので、Kaggleに関しては一旦ここで終わりとしたいと思います。
また興味が向いたら、挑戦してみることにしましょう。
次回からはTwitterをPythonで制御できるようTwitter APIをいじっていきます。
ということで今回はこんな感じで。
コメント