Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」の「タイタニック号乗客の生存予測」のデータセットのName、特に敬称を解析しました。
今回は前回の解析結果をもとにさらに解析を進めていきたいと思います。
ということでまずはデータの読み込みとこれまでの修正を行っていきます。
<セル1>
import pandas as pd
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
train.loc[train["Sex"] == "male", "Sex"] = 0
train.loc[train["Sex"] == "female", "Sex"] = 1
test.loc[test["Sex"] == "male", "Sex"] = 0
test.loc[test["Sex"] == "female", "Sex"] = 1
test.loc[test["Fare"].isnull() == True, "Fare"] = 7.8875
train.loc[train["Embarked"].isnull() == True, "Embarked"] = "S"
train.loc[train["Embarked"] == "S", "Embarked"] = 0
train.loc[train["Embarked"] == "C", "Embarked"] = 1
train.loc[train["Embarked"] == "Q", "Embarked"] = 2
test.loc[test["Embarked"] == "S", "Embarked"] = 0
test.loc[test["Embarked"] == "C", "Embarked"] = 1
test.loc[test["Embarked"] == "Q", "Embarked"] = 2
all_data = pd.concat([train.drop(columns = "Survived"), test])
all_data
実行結果
それでは始めていきましょう。
敬称の分類を行う
前回、乗客の敬称をデータから抜き出し、どんな敬称があるのかの確認、そしてそれぞれの敬称を持つ人の数を数えました。
そのプログラムはこんな感じでした。
<セル2>
title_list = []
for name in all_data["Name"]:
for name_split in name.split():
if name_split.endswith(".") == True:
if name_split != "L.":
title_list.append(name_split)
title_unique = set(title_list)
print(title_unique)
実行結果
{'Lady.', 'Miss.', 'Rev.', 'Dr.', 'Dona.', 'Major.', 'Mr.', 'Jonkheer.', 'Capt.', 'Sir.', 'Ms.', 'Master.', 'Col.', 'Countess.', 'Mlle.', 'Mme.', 'Mrs.', 'Don.'}<セル3>
for title in title_unique:
title_count = title_list.count(title)
print(str(title) + ":" + str(title_count))
実行結果
Lady.:1
Miss.:260
Rev.:8
Dr.:8
Dona.:1
Major.:2
Mr.:757
Jonkheer.:1
Capt.:1
Sir.:1
Ms.:2
Master.:61
Col.:4
Countess.:1
Mlle.:2
Mme.:1
Mrs.:197
Don.:1多い順からいうと「Mr.」、「Miss.」、「Mrs.」、「Master.」であとはごく少数ということが分かります。
ここから新たに「Title」という列を作成し、それぞれの敬称を分類していきます。
「Mr.」は男性に対する敬称なのでなかなか年齢は読み取りにくいですが、「Miss.」は未婚女性、「Mrs.」は既婚女性、「Master.」は少年や青年男性に対する敬称なので、特徴的な年齢分布が出てきそうです。
そこでこれらはそれぞれ別の分類と定義しましょう。
他のものは少数すぎて、分布を調べることができないので、一括りにしてしまいましょう。
ということでこんな感じになります。
<セル4>
title_num = []
for title in title_list:
if title == "Mr.":
title_num.append(0)
elif title == "Miss.":
title_num.append(1)
elif title == "Mrs.":
title_num.append(2)
elif title == "Master.":
title_num.append(3)
else:
title_num.append(4)
all_data["title"] = title_num
all_data
実行結果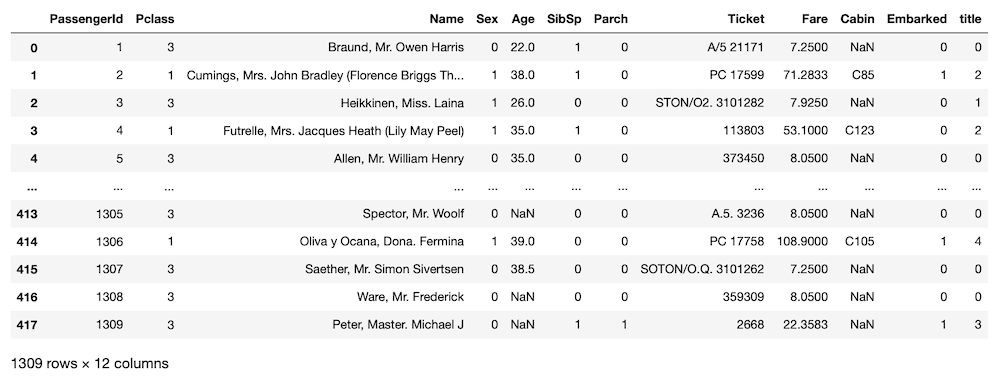
新たな列「Title」が作成されました。
ヒストグラムを表示し、傾向を確認する
分類ができたので、解析を進めていきましょう。
まずはそれぞれの敬称の分布を見てみます。
<セル5>
all_data["title"].hist()
実行結果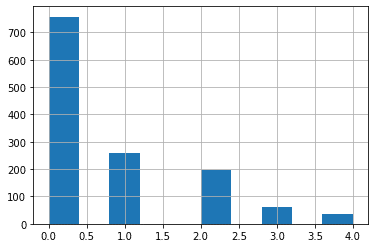
「Mr.」が750人程度、「Miss.」が250人程度、「Mrs.」が200人程度、「Master.」が60人程度、その他が50人程度といったところでしょうか。
次に全体の年齢のヒストグラムを表示してみます。
<セル6>
all_data["Age"].hist()
実行結果
それぞれの敬称における年齢分布と全体の年齢分布を比較していきましょう。
まずは「Mr.」から。
<セル7>
all_data[all_data["title"] == 0]["Age"].hist()
実行結果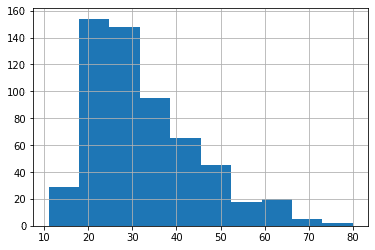
「Mr.」では「Master.」に分類された少年・青年がごっそり抜けたためか、10代以下の人の割合が下がっています。
また50代の人の割合も下がっています。
次は「Miss.」。
<セル8>
all_data[all_data["title"] == 1]["Age"].hist()
実行結果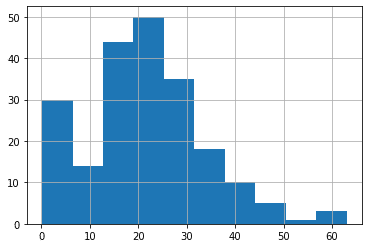
こちらは全体の年齢分布に近い形になっています。
ただ何故か50代の人の割合が少ないようです。
次は「Mrs.」です。
<セル9>
all_data[all_data["title"] == 2]["Age"].hist()
実行結果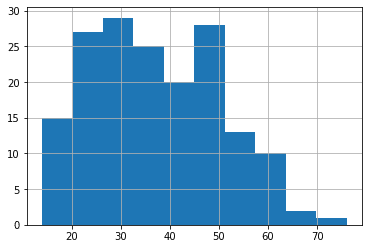
「Mrs.」は既婚女性であるため、10歳未満はいません。
そして20代から40代くらいまでは大体同じ人数いて、50代から段々と少なくなっていっています。
次は「Master.」。
<セル10>
all_data[all_data["title"] == 3]["Age"].hist()
実行結果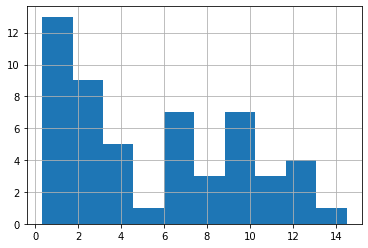
少年・青年に対する敬称のため、低年齢の人ばかりになりました。
最後はその他です。
<セル11>
all_data[all_data["title"] == 4]["Age"].hist()
実行結果
「その他」に分類されるのは「Dr.」や「Rev.」など立場を示す敬称が多いため、年齢は比較的高めの分布になるようです。
このことから「Mr.」や「Miss.」は全体の年齢分布に近いですが、「Mrs.」、「Master.」、「その他」の敬称は全体の年齢分布とは異なる特徴的な年齢分布になっていることが分かります。
となるとAgeの欠損値を埋めるために、この敬称の情報を使うことはなかなか良いかもしれません。
ということで次回は敬称のデータを使って、Ageの欠損値を修正し、機械学習からスコアの取得までやってみることにしましょう。

ではでは今回はこんな感じで。
コメント