データ解析支援ライブラリPandas
前回は欠損値nanをもつダミーデータを作成するため、ダミーデータ作成プログラムをアップデートしました。
今回はそのnanをもつダミーデータを使って、欠損値nanの取り扱い方法の基本を解説していきます。
ということでまずは準備から。
データはアップデートしたダミーデータ作成プログラムで作成したこちらのデータを用います。
データの読み込みはこんな感じ。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df
実行結果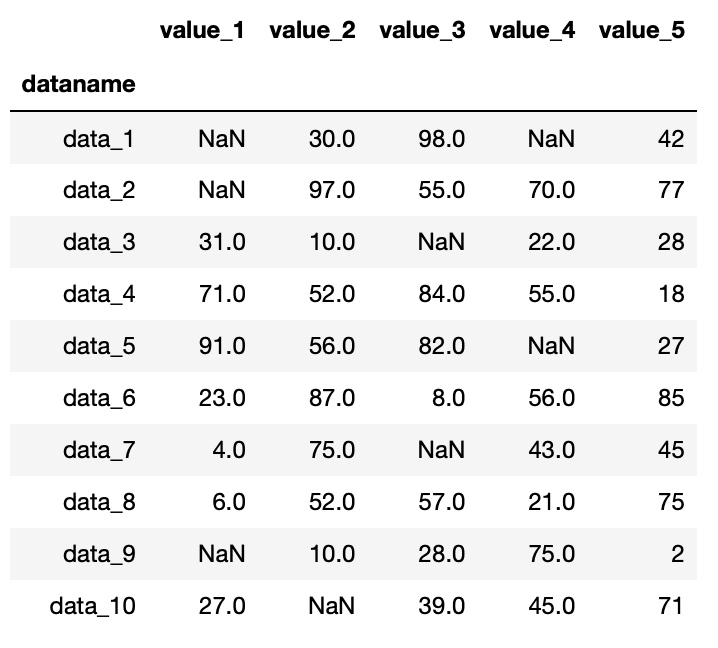
そこそこ欠損値nanがばらまかれている、それでいてnanが入っていない行、列があるいい感じのデータです。
それぞれのセルの値が欠損値nanか確認:.isnull()
まずはそれぞれのセルに入っている値が欠損値nanか確認するコマンドを見てみましょう。
そのコマンドは「.isnull()」です。
「null」というのは「何もないことを示す値」で、「nan」と同じような意味を示しています。
「nan」を使うんだから「.isnan()」だと思ってしまいがちですが、「.isnull()」なので注意してください。
ということで試してみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df.isnull()
実行結果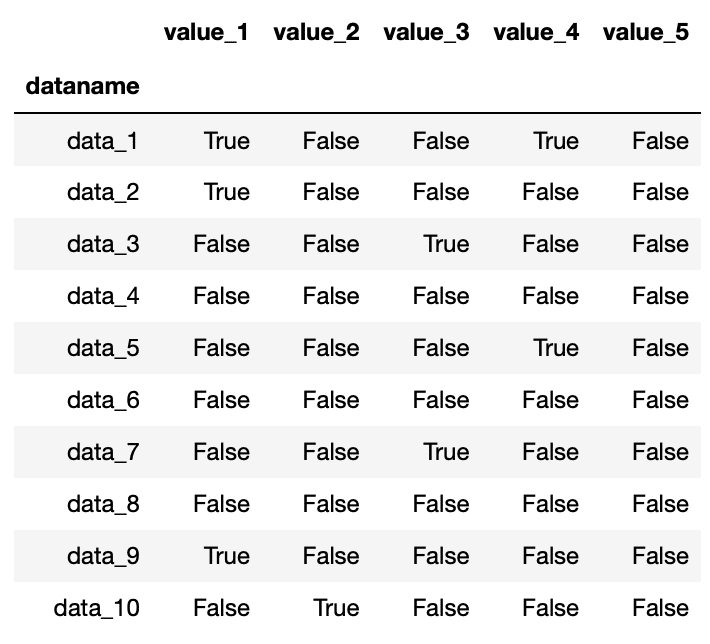
「True」になっているところが「nan」で、「False」となっているところが数値が入っているセルになります。
ちなみに間違えそうな「.isnan()」だとそんなコマンドないというエラーが表示されます。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df.isnan()
実行結果
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-7-893404702a14> in <module>
3 df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
4
----> 5 df.isnan()
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/generic.py in __getattr__(self, name)
5177 if self._info_axis._can_hold_identifiers_and_holds_name(name):
5178 return self[name]
-> 5179 return object.__getattribute__(self, name)
5180
5181 def __setattr__(self, name, value):
AttributeError: 'DataFrame' object has no attribute 'isnan'各行、各列のnanの数をカウント:.isnull().sum()
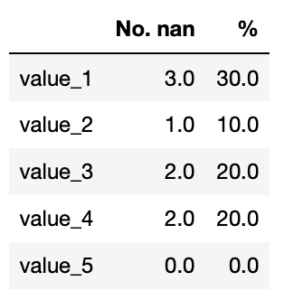
次に各行、各列のnanの数をカウントできるようにしてみましょう。
その場合は一つのコマンドだけではできず、「.isnull()」でnanかどうかを判定し、「.sum()」で「True」となったセル数をカウントします。
また行と列を指定するには「.sum()」のオプションとして、「axis=0」、「axis=1」を追加します。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df.isnull().sum()
実行結果
value_1 3
value_2 1
value_3 2
value_4 2
value_5 0
dtype: int64オプションなしだと各列のnanの数をカウントしてくれます。
またオプションにaxis=0を追加しても同じです。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df.isnull().sum(axis=0)
実行結果
value_1 3
value_2 1
value_3 2
value_4 2
value_5 0
dtype: int64オプションがaxis=1だと各行のnanの数をカウントできます。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df.isnull().sum(axis=1)
実行結果
dataname
data_1 2
data_2 1
data_3 1
data_4 0
data_5 1
data_6 0
data_7 1
data_8 0
data_9 1
data_10 1
dtype: int64欠損値nanを特定の値で置き換え:.fillna()
欠損値が欠損値のままではデータ解析に支障が出る場合があります。
その場合は欠損値を理論的に妥当な値に置き換え、解析を行います。
nanを他の値に置き換える際に用いるコマンドが「.fillna()」です。
全てのnanを1000に置き換えてみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df = df.fillna(1000)
df
実行結果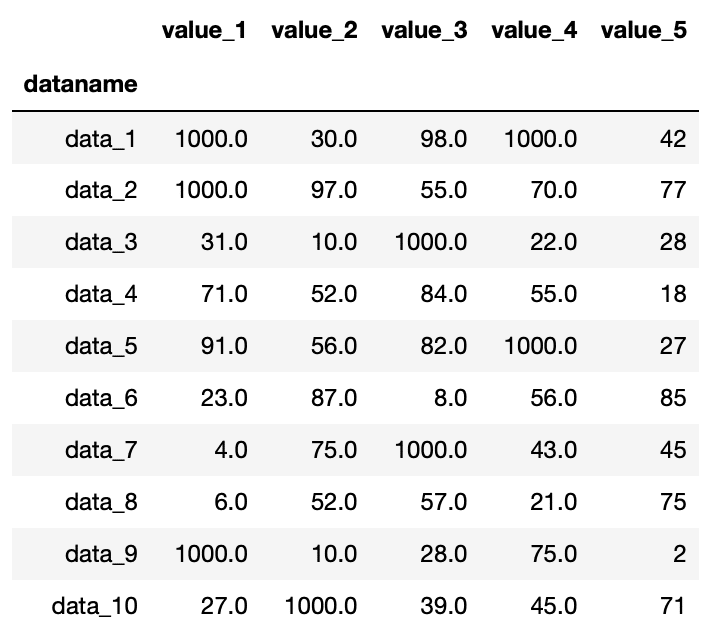
「df = df.fillna(1000)」としているのは、一度データフレームdfをnanを1000に置き換えたデータフレームで上書きするためです。
もちろん特定の列や行のnanだけ置き換えることも可能です。
まずは「value_3」の列のnanを1000に置き換えてみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df["value_3"] = df["value_3"].fillna(1000)
df
実行結果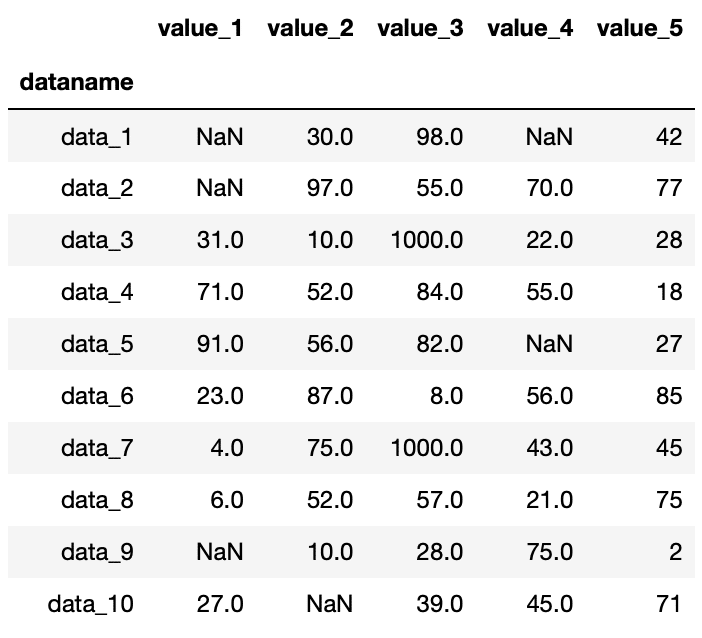
次に「data_7」の列のnanを1000に置き換えてみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df.loc["data_7"] = df.loc["data_7"].fillna(1000)
df
実行結果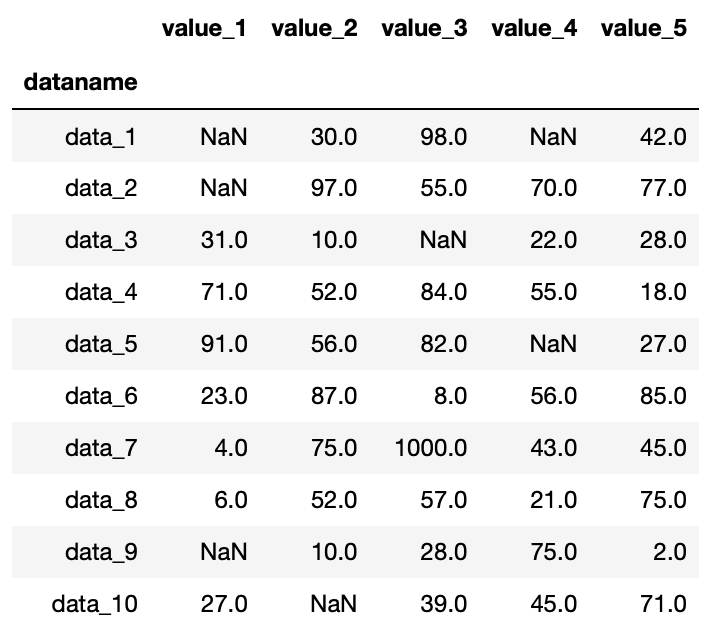
今回はnanの処理の基本編ということでここまでにしておきましょう。
次回は今回解説したコマンドの応用的な使い方を解説していきたいと思います。
ということで今回はこんな感じで。
コメント