データ解析支援ライブラリPandas
前回はデータ解析支援ライブラリPandasで行と列の両方を指定してデータを取得する方法を解説しました。
ここまではデータを読み込んで表示するということばかりでした。
でもPandasはデータ解析を行うためのライブラリなので、データを処理して目的とするデータの傾向を解析ことに用います。
ということで今回はデータ解析でよく用いられる合計値、平均値、中央値、最大値、最小値、標準偏差を計算していきましょう。
ということでまずは準備をしていきます。
使用するデータは、自作のダミーデータ作成プログラムで作ったこちら。
データの読み込みはこんな感じです。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df
実行結果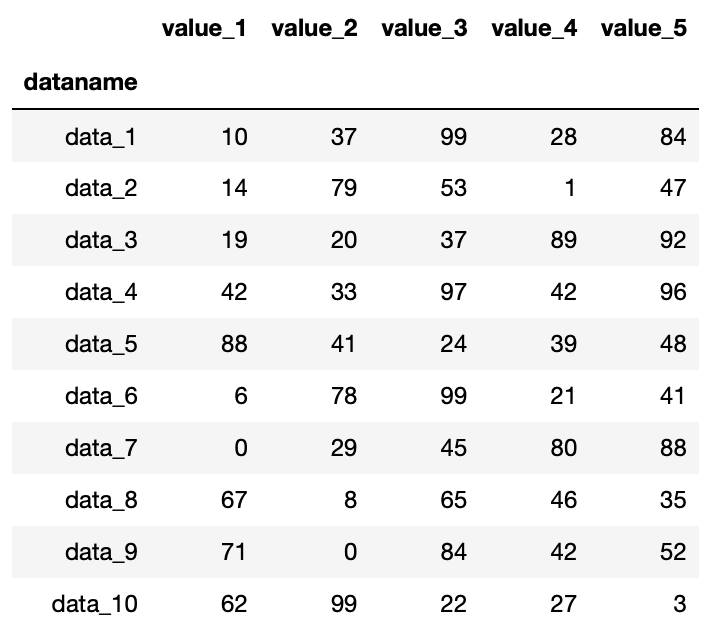
ということでまずは合計値から解説していきましょう。
Pandasで行、列の合計値を計算:.sum()
行、列の合計値を計算するには.sum()というコマンドを用います。
とりあえず使ってみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.sum())
実行結果
value_1 379
value_2 424
value_3 625
value_4 415
value_5 586
dtype: int64各列の合計値が計算できました。
しかし時には各行の合計値を計算したいこともあることでしょう。
行の合計値を計算したいときは、「axis=1」か「axis=”columns”」をオプションとして括弧の中に記述します。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.sum(axis=1))
実行結果
dataname
data_1 258
data_2 194
data_3 257
data_4 310
data_5 240
data_6 245
data_7 242
data_8 221
data_9 249
data_10 213
dtype: int64import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.sum(axis="columns"))
実行結果
dataname
data_1 258
data_2 194
data_3 257
data_4 310
data_5 240
data_6 245
data_7 242
data_8 221
data_9 249
data_10 213
dtype: int64ちなみに「axis=0」は列を示しているので、記述しなかった場合と同じようにそれぞれの列の合計値が取得できます。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.sum(axis=0))
実行結果
value_1 379
value_2 424
value_3 625
value_4 415
value_5 586
dtype: int64ちなみに「axis=”index”」は認識されるのでしょうか?
試してみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.sum(axis="index"))
実行結果
value_1 379
value_2 424
value_3 625
value_4 415
value_5 586
dtype: int64「axis=”index”」でも認識されました。
ではどれか一つの列の合計値を知りたい場合はどうしたらいいでしょうか?
その場合は、そのインデックス番号をリスト形式で指定することで取得できます。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.sum(axis="index")[2])
実行結果
625連続している場合は「:」を使うこともできます。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.sum(axis="index")[2:4])
実行結果
value_3 625
value_4 415
dtype: int64しかし連続していない複数の列は取れないようです。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.sum(axis="index")[2, 4])
実行結果
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/indexes/base.py in get_value(self, series, key)
4735 try:
-> 4736 return libindex.get_value_box(s, key)
4737 except IndexError:
pandas/_libs/index.pyx in pandas._libs.index.get_value_box()
pandas/_libs/index.pyx in pandas._libs.index.get_value_at()
pandas/_libs/util.pxd in pandas._libs.util.get_value_at()
pandas/_libs/util.pxd in pandas._libs.util.validate_indexer()
TypeError: 'tuple' object cannot be interpreted as an integer
(以下略)連続していない列(行もですが)の合計を取得する方法はまた必要になったら考えます。
Pandasで行、列の平均値を計算:.mean()
次に各行、各列の平均値を計算するには、「.mean()」を用います。
これもオプションなし、もしくは「axis=0」、「axis=”index”」では各列の平均値を、「axis=1」か「axis=”columns”」で各行の平均値を取得できます。
ここでは「axis=0」と「axis=1」の場合のみ紹介しておきます。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.mean(axis=0))
実行結果
value_1 37.9
value_2 42.4
value_3 62.5
value_4 41.5
value_5 58.6
dtype: float64import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.mean(axis=1))
実行結果
dataname
data_1 51.6
data_2 38.8
data_3 51.4
data_4 62.0
data_5 48.0
data_6 49.0
data_7 48.4
data_8 44.2
data_9 49.8
data_10 42.6
dtype: float64Pandasで行、列の中央値を計算:.median()
次は中央値です。
中央値を計算するには、「.median()」を用います。
これもオプションなし、もしくは「axis=0」、「axis=”index”」では各列の中央値を、「axis=1」か「axis=”columns”」で各行の中央値を取得できます。
ここでは「axis=0」と「axis=1」の場合のみ紹介しておきます。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.median(axis=0))
実行結果
value_1 30.5
value_2 35.0
value_3 59.0
value_4 40.5
value_5 50.0
dtype: float64import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.median(axis=1))
実行結果
dataname
data_1 37.0
data_2 47.0
data_3 37.0
data_4 42.0
data_5 41.0
data_6 41.0
data_7 45.0
data_8 46.0
data_9 52.0
data_10 27.0
dtype: float64Pandasで行、列の最大値、最小値を計算:.max()、.min()
最大値、最小値を計算するには、それぞれ「.max()」「.min()」を用います。
これもオプションなし、もしくは「axis=0」、「axis=”index”」では各列の最大値、最小値を、「axis=1」か「axis=”columns”」で各行の最大値、最小値を取得できます。
ここでは「axis=0」と「axis=1」の場合のみ紹介しておきます。
<最大値の計算>
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.max(axis=0))
実行結果
value_1 88
value_2 99
value_3 99
value_4 89
value_5 96
dtype: int64import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.max(axis=1))
実行結果
dataname
data_1 99
data_2 79
data_3 92
data_4 97
data_5 88
data_6 99
data_7 88
data_8 67
data_9 84
data_10 99
dtype: int64<最小値の計算>
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.min(axis=0))
実行結果
value_1 0
value_2 0
value_3 22
value_4 1
value_5 3
dtype: int64import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.min(axis=1))
実行結果
dataname
data_1 10
data_2 1
data_3 19
data_4 33
data_5 24
data_6 6
data_7 0
data_8 8
data_9 0
data_10 3
dtype: int64Pandasで行、列の標準偏差を計算:.std()
標準偏差を計算するには「.std()」を用います。
これもオプションなし、もしくは「axis=0」、「axis=”index”」では各列の標準偏差を、「axis=1」か「axis=”columns”」で各行の標準偏差を取得できます。
ここでは「axis=0」と「axis=1」の場合のみ紹介しておきます。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.std(axis=0))
実行結果
value_1 31.991145
value_2 32.646933
value_3 30.718254
value_4 26.285822
value_5 30.317578
dtype: float64import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
print(df.std(axis=1))
実行結果
dataname
data_1 38.069673
data_2 31.340070
data_3 36.418402
data_4 31.709620
data_5 24.010414
data_6 38.852284
data_7 36.390933
data_8 24.242525
data_9 32.267631
data_10 38.056537
dtype: float64これで基本的な統計値は大体計算できるようになったかと思います。
ただこれでは単に計算しただけ、計算したのならデータに入れ込みたいというのが次に考えることでしょう。
ということで次回は値をデータに追加する方法を解説していきます。
ということで今回はこんな感じで。
コメント