データ解析支援ライブラリPandas
前回はデータ解析支援ライブラリPandasで欠損値nanを判定し、カウント、特定の値に置き換える方法を解説しました。
今回はデータ解析をする際に最初に確認するnanの個数と何%のデータがnanなのかを確認する関数を作成してみましょう。
ということでまずは準備から。
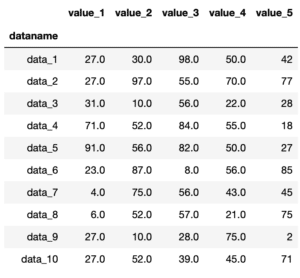
データは前回と同じnanを含んだデータを用います。
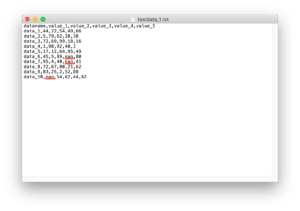
データの読み込みはこんな感じ。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df
実行結果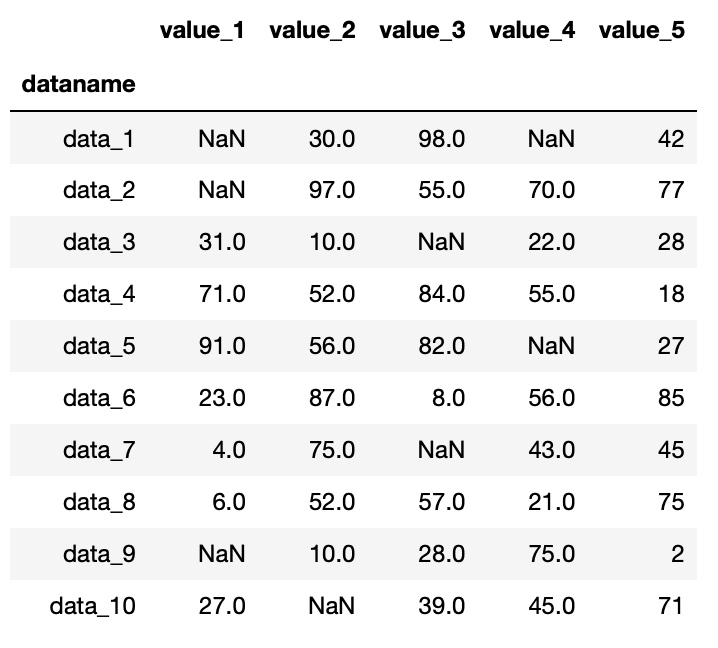
ということで進めていきましょう。
nanの%を計算する方法
前回、nanの数を数える方法を解説しました。
今回はさらに何%のデータがnanなのか計算できるようにしましょう。
よく使われるのは各列のnanの個数と%なので、今回は列のみ解説を行います。
まずは前回解説した個数を数える方法の復習から。
個数をカウントするのは「.isnull().sum()」ということでした。
ということでこんな感じ。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
nan_val = df.isnull().sum()
print(nan_val)
実行結果
value_1 3
value_2 1
value_3 2
value_4 2
value_5 0
dtype: int64%を計算するには列に含まれるデータ数が必要になります。
それぞれの列のデータの個数は「len(データフレーム名.index)」でカウントできます。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
nan_val = df.isnull().sum()
total_val = len(df.index)
print(nan_val)
print(total_val)
実行結果
value_1 3
value_2 1
value_3 2
value_4 2
value_5 0
dtype: int64
10そして%の計算は「100×nanの数/列のデータ数」なので計算してみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
nan_val = df.isnull().sum()
total_val = len(df.index)
nan_percent = 100 * nan_val/total_val
print(nan_val)
print(total_val)
print(nan_percent)
実行結果
value_1 3
value_2 1
value_3 2
value_4 2
value_5 0
dtype: int64
10
value_1 30.0
value_2 10.0
value_3 20.0
value_4 20.0
value_5 0.0
dtype: float64それぞれの列には10個のデータが含まれていて、「value_1」はそのうち3つがnanなので30%、「value_2」はnanが1個なので10%という感じで計算できています。
nanの個数と%を計算する関数を作成する
それでは先ほどの個数と%を計算するプログラムを関数化してみましょう。
自分で関数を作る方法はこちらの記事で解説しています。
とりあえずnan_checkという名前の関数を作ってみます。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
def nan_check(df):
nan_val = df.isnull().sum(axis=0)
total_val = len(df.index)
nan_percent = 100 * nan_val/total_val
print(nan_val)
print(total_val)
print(nan_percent)
nan_check(df)
実行結果
value_1 3
value_2 1
value_3 2
value_4 2
value_5 0
dtype: int64
10
value_1 30.0
value_2 10.0
value_3 20.0
value_4 20.0
value_5 0.0
dtype: float64表にしたいので、Pandasのデータフレームにしてしまいましょう。
データフレームにする方法は次回詳しく解説していきますが、とりあえず「pd.DataFrame(値のリスト, index=行名のリスト)」でデータフレームにすることができます。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
def nan_check(df):
nan_val = df.isnull().sum(axis=0)
total_val = len(df.index)
nan_percent = 100 * nan_val/total_val
nan_df = pd.DataFrame([nan_val, nan_percent], index=["No. nan", "%"])
return nan_df
nan_check(df)
実行結果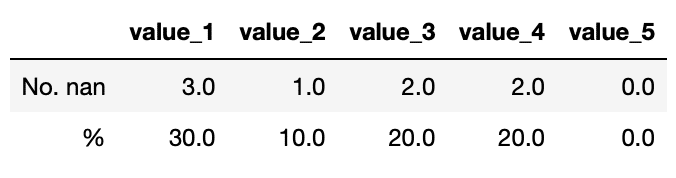
ということで表として表示することができました。
ちなみに列数が多くなってしまった場合、縦に表示したいこともあるでしょう。
その場合は、「return nan_df」の最後に「.T」をつけます。
つまりこうなります。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
def nan_check(df):
nan_val = df.isnull().sum(axis=0)
total_val = len(df.index)
nan_percent = 100 * nan_val/total_val
nan_df = pd.DataFrame([nan_val, nan_percent], index=["No. nan", "%"])
return nan_df.T
nan_check(df)
実行結果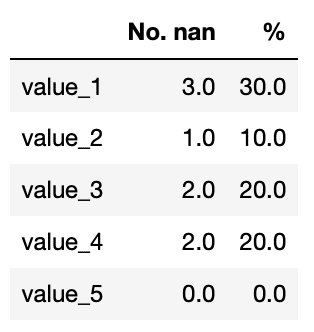
データフレームに「.T」をつけると表の行と列が入れ替わるということです。
もともとtranspose(転置)の頭文字の「T」から来ているようです。
これでnanの個数と%を計算するための関数を作ることができました。
次回はnanを置き換えるのに、平均値とか中央値に置き換えるのを試してみましょう。
ということで今回はこんな感じで。
コメント