データ解析支援ライブラリPandas
前回はデータ解析支援ライブラリPandasで欠損値nanの個数を数え、%表示する関数を作成しました。
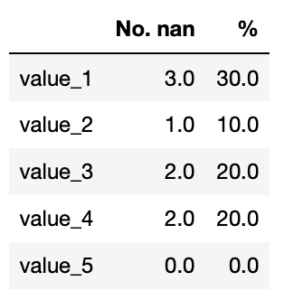
今回は欠損値nanを平均値や中央値で置き換える方法を解説していきます。
今回もまずは準備から。
データは前回と同じnanを含んだデータを用います。
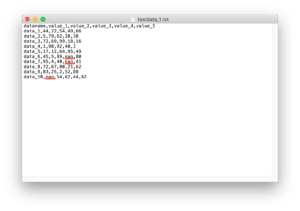
データの読み込みはこんな感じ。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df
実行結果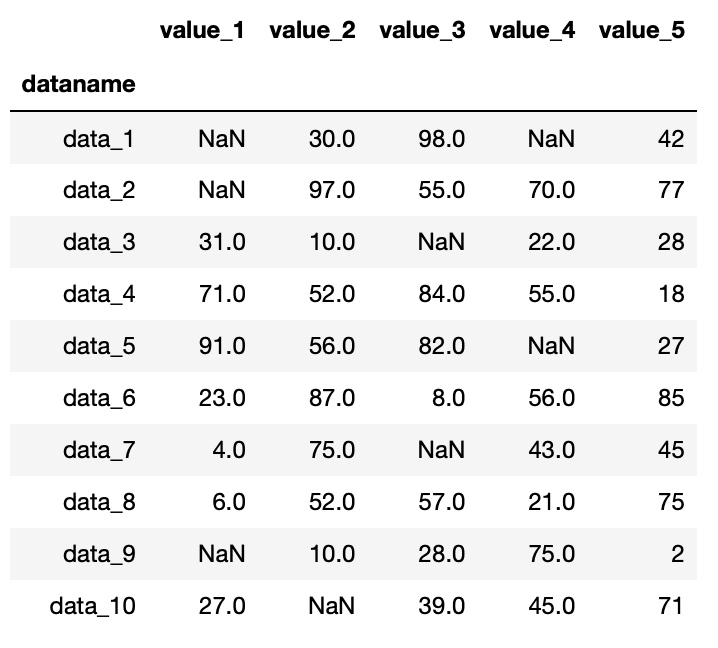
それでは進めていきましょう。
欠損値nanを平均値や中央値で置き換える方法
まずは欠損値nanを置き換える方法を復習しましょう。
欠損値nanを置き換えるには、「.fillna(置き換える値)」でした。
「value_1」のnanを500に置き換えてみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df["value_1"] = df["value_1"].fillna(500)
df
実行結果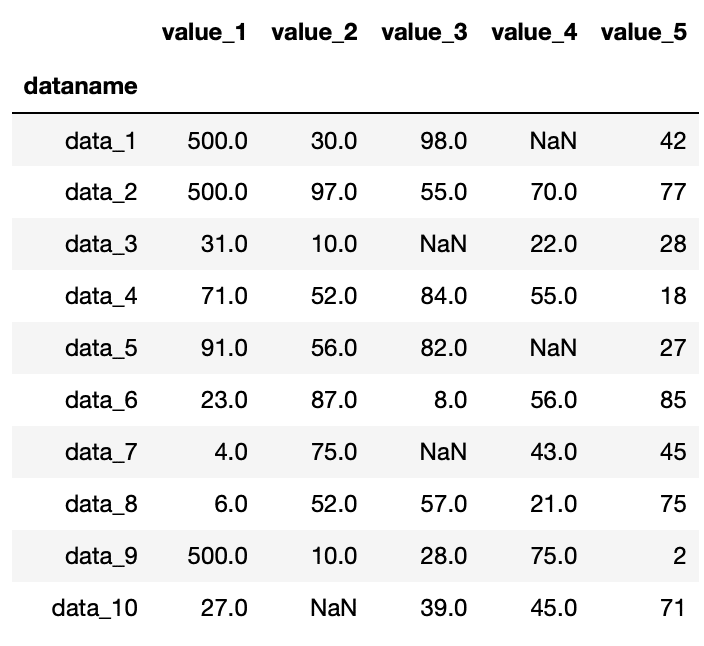
では次に500ではなく、「value_1」の列にある他の値の平均値で置き換えてみましょう。
平均値を計算する場合は、「データフレーム名.mean()」でした。
今回は「value_1」の平均値だけなので、df[“value_1”].mean()となります。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df["value_1"] = df["value_1"].fillna(df["value_1"].mean())
df
実行結果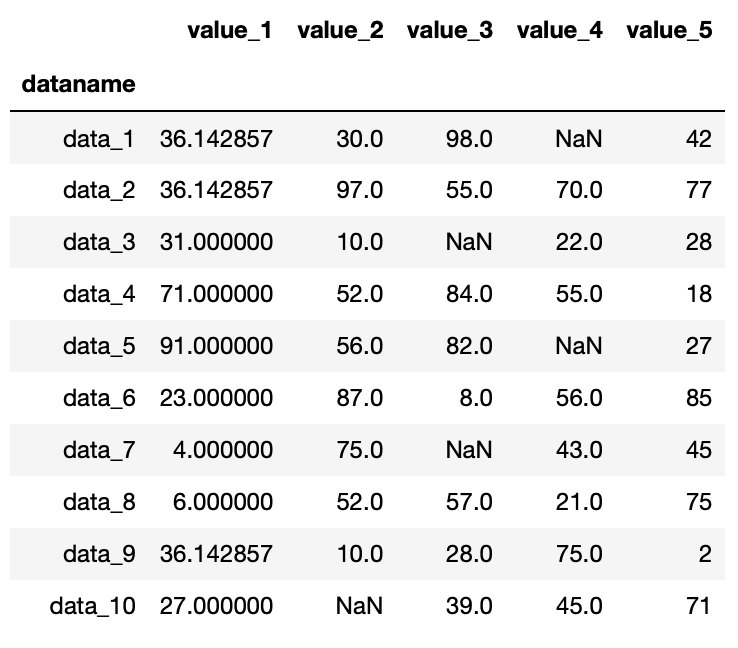
小数点以下6桁まで表示されてしまっていますが、確かにvalue_1の列のnanを平均値で置き換えることができました。
また中央値の場合は「データフレーム名.median()」でした。
ということで中央値の場合はこうなります。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df["value_1"] = df["value_1"].fillna(df["value_1"].median())
df
実行結果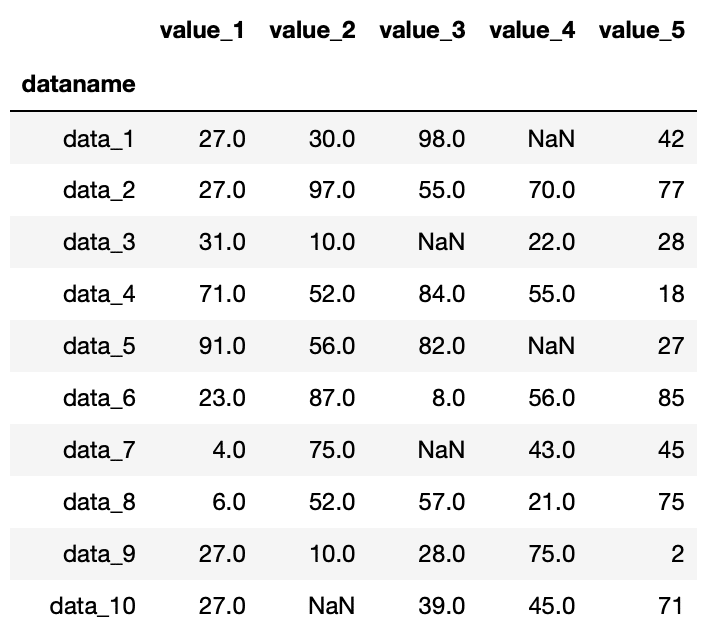
今度はnanが中央値である「27」に置き換えられました。
各列をその列の平均値、中央値で置き換える方法
では今度は1列だけではなく、全列をそれぞれの列の平均値、中央値で置き換えてみましょう。
この場合、悩むのは「df[“value_1”] = df[“value_1”].fillna(df[“value_1”].mean())」の部分。
ここを列名を一つずつ取りつつ、「”value_1″」の代わりに代入していくことになります。
その際に必要なのは列の名前を取得する方法。
列名を取得する方法は下の記事で解説していますが、「データフレーム名.columns」です。
これをfor文を使い、一つずつ先ほどの「”value_1″」の代わりに代入していきます。
ということでこんな感じ。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
for column_name in df.columns:
df[column_name] = df[column_name].fillna(df[column_name].mean())
df
実行結果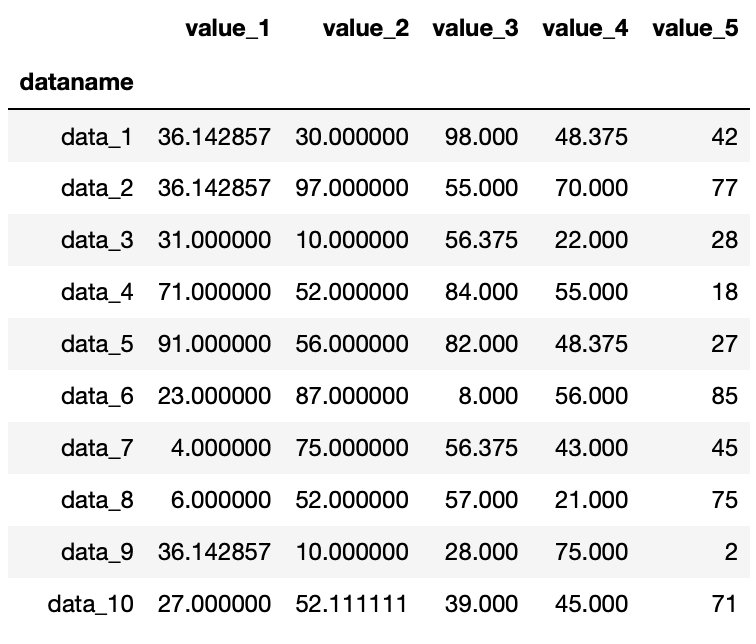
各列のnanを各列の平均値で置き換えることができました。
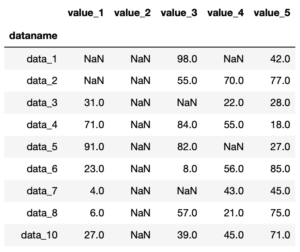
もちろん中央値でも可能です。
import pandas as pd
df = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
for column_name in df.columns:
df[column_name] = df[column_name].fillna(df[column_name].median())
df
実行結果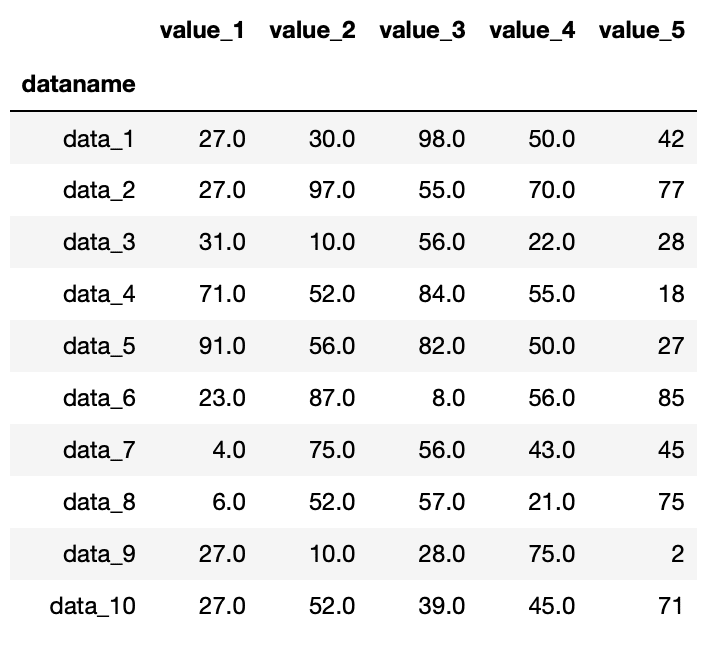
このように欠損値nanを置き換えることで少しでも欠損していないデータに近づけることは、データ解析において重要なことになります。
今回は平均値、中央値だけですが、データによっては違う値を使う方がいい場合もありますが、今回の「df[column_name].mean()」のところを変えるだけで、色々な値にすることができると思います。
どういう値にするといいかはデータを見て判断するしかないのですが。
次回は欠損値nanが入っている場合、その行や列を削除する方法を解説します。
ではでは今回はこんな感じで。
コメント