BeautifulSoup
前回、Webページ解析ライブラリBeautifulSoupを使って、見出しの取得を行いました。

今回はさらに本文の取得を行なっていきます。
用いる記事は前回同様、こちらの記事を使っていきましょう。
また上記のページを保存するにはこちらのプログラムを実行すればローカル(PC上)に保存できます。
import urllib
url = 'https://3pysci.com/dx-1/'
html_out = './dx-1.html'
urllib.request.urlretrieve(url, html_out)それでは始めていきましょう。
本文がどこにあるのかを見定める
本文を取得するにあたって重要なのは、その本文がhtml上のどこに属しているのかと言うことです。
まずhtmlファイルは「<head> </head>」で囲まれたヘッダーと「<body> </body>」で囲まれた実際に表示される領域に分けられます。
そしてそれぞれの領域にはさらに細かく役割が決められた領域が複数存在します。
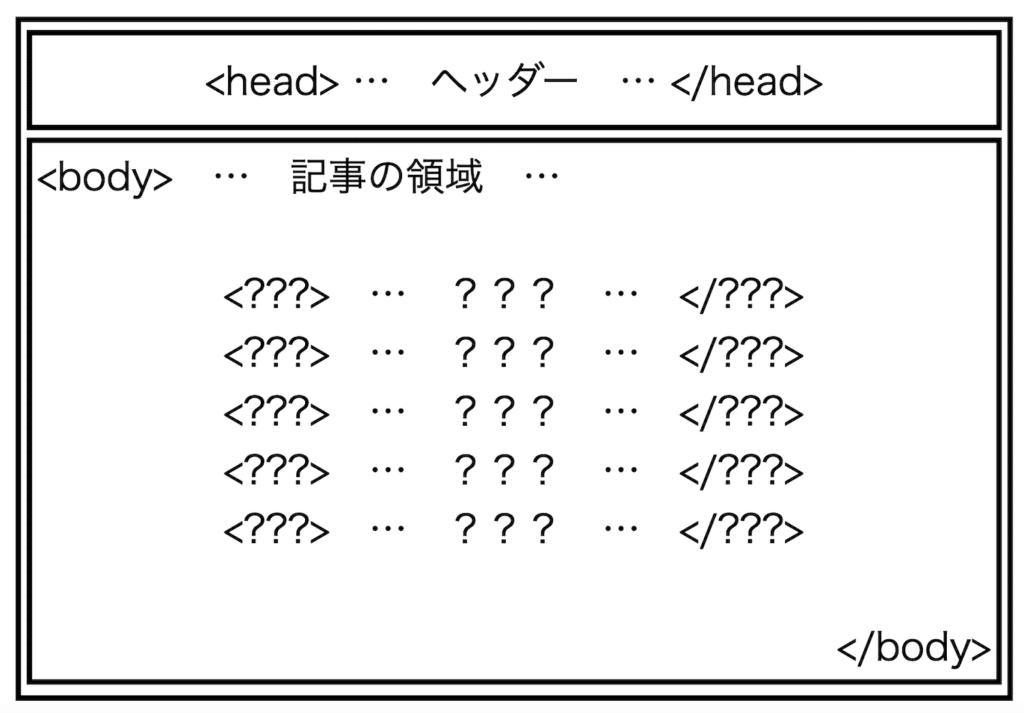
ということでまずは「<body> </body>」で囲まれた領域のデータを取得し、中身を確認して本文の領域を探っていきましょう。
from bs4 import BeautifulSoup
inputfile = './dx-1.html'
with open(inputfile, 'r') as f_in:
soup = BeautifulSoup(f_in)
print(soup.find('body'))前々回勉強した「.find(‘タグ’)」を使って「bodyタグ」を取得しています。
これを実行するとこうなります。
実行結果
<body>
<svg focusable="false" height="0" role="none" style="visibility: hidden; position:
absolute; left: -9999px; overflow: hidden;" viewbox="0 0 0 0" width="0"
xmlns="http://www.w3.org/2000/svg"><defs><filter id="wp-duotone-dark-grayscale">
<fecolormatrix color-interpolation-filters="sRGB" type="matrix" values=" .299 .587
.114 0 0 .299 .587 .114 0 0 .299 .587 .114 0 0 .299 .587 .114 0 0 "></fecolormatrix>
(中略)
<div class="l-content l-container" data-postid="17120" data-pvct="true" id="content">
<main class="l-mainContent l-article" id="main_content">
<article class="l-mainContent__inner">
<div class="p-articleHead c-postTitle">
<h1 class="c-postTitle__ttl">Pythonで始めるなんちゃってDX その1:表の項目を抽出するプログラム</h1>
<time class="c-postTitle__date u-thin" datetime="2022-05-01">
(中略)
:"ListItem","position":1,"item":{"@id":"https:\/\/3pysci.com\/category\/programming\/",
"name":"Programming"}}]}]</script>
</body>「bodyタグ」の中身を取得するのには成功したのですが、本文を取得するにはまだまだ余計な領域が含まれているようです。
そこで本文の近くに「<main class=”l-mainContent l-article” id=”main_content”>」という記述を見つけ、どうやらここに記事本文が含まれているようです。
ということで試してみましょう。
from bs4 import BeautifulSoup
inputfile = './dx-1.html'
with open(inputfile, 'r') as f_in:
soup = BeautifulSoup(f_in)
print(soup.find('main'))
実行結果
<main class="l-mainContent l-article" id="main_content">
<article class="l-mainContent__inner">
<div class="p-articleHead c-postTitle">
<h1 class="c-postTitle__ttl">Pythonで始めるなんちゃってDX その1:表の項目を抽出するプログラム</h1>
<time class="c-postTitle__date u-thin" datetime="2022-05-01">
<span class="__y">2022</span>
(中略)
</li>
</ul>
</div>
<div class="post_content">
<div class="p-toc -capbox"><span class="p-toc__ttl">目次</span></div>
<h2 id="dx-デジタルトランスフォーメーション">DX(デジタルトランスフォーメーション)</h2>
<p>前回、個人でDXやろうぜってことで、Pythonのインストールに関してお話ししました。</p>
<div class="swell-block-postLink" data-style="card"> <div class="p-blogCard -internal"
data-onclick="clickLink" data-type="type1">
(中略)
</p></form> </div><!-- #respond -->
</div>
</section>
</article>
</main>最初含まれていた大量のCSS(らしき)の情報は消えましたが、まだまだ本文だけとは言い難い領域です。
そして今回さらに本文近くに「<div class=”post_content”>」という記述を見つけました。
今度はこの「divタグ」を取得したいのですが、「divタグ」は特定の意味を持たず、単純に「ここがひとかたまりだよー」と教えてくれるタグです。
つまり先ほど探した「bodyタグ」や「mainタグ」のように一つだけ存在するといったタグではありません。
ということで今回は「divタグ」で「class=”post_content”」をもった領域を取得するというのを試していきます。
.find(‘タグ’, class_=’クラス’)
htmlのタグで特定のクラスに属するタグを取得するには「.find(‘タグ’, class_=’クラス’)」、全て取得したい場合は「.find_all(‘タグ’, class_=’クラス’)」を用います。
今回は一つだけなので「.find(‘タグ’, class_=’クラス’)」を使ってみましょう。
ここで注意ですが、「class」はPythonの予約語の一つで変数名、関数名、クラス名などには使うことができません。
そのため「class_」と最後にアンダーバーがついていることを忘れないでください。
ちなみに登録されている予約語は「keywordライブラリ」をインポートして、「keyword.kwlist」で取得できます。
import keyword
print(keyword.kwlist)
実行結果
['False', 'None', 'True', '__peg_parser__', 'and', 'as', 'assert', 'async', 'await',
'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for',
'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass',
'raise', 'return', 'try', 'while', 'with', 'yield']それでは「.find(‘タグ’, class_=’クラス’)」を試してみましょう。
from bs4 import BeautifulSoup
inputfile = './dx-1.html'
with open(inputfile, 'r') as f_in:
soup = BeautifulSoup(f_in)
print(soup.find_all('div', class_='post_content'))
実行結果
<div class="post_content">
<div class="p-toc -capbox"><span class="p-toc__ttl">目次</span></div>
<h2 id="dx-デジタルトランスフォーメーション">DX(デジタルトランスフォーメーション)</h2>
<p>前回、個人でDXやろうぜってことで、Pythonのインストールに関してお話ししました。</p>
<div class="swell-block-postLink" data-style="card"> <div class="p-blogCard -internal"
data-onclick="clickLink" data-type="type1">
(中略)
<p>統計データは大量の列が含まれていて、見づらい場合もあるので、そんな時にこのプログラムがあると便利かなと思います。</p>
<p>良かったら、使ってみたり、いじってみたりしてください。</p>
<p>次回は、このプログラムを試すためのデータを作成したプログラムを紹介します。</p>
<p>ではでは今回はこんな感じで。</p>
</div>これで前後が本文ギリギリまでの領域でデータを取得できました。
テキストだけ取得:.getText()
最後に本文だけ取得してみましょう。
取得したデータに「.getText()」を付けることで、テキストだけ抽出できます(get_text()でもできるらしい)。
from bs4 import BeautifulSoup
inputfile = './dx-1.html'
with open(inputfile, 'r') as f_in:
soup = BeautifulSoup(f_in)
print(soup.find('div', class_='post_content').getText())
実行結果
目次DX(デジタルトランスフォーメーション)
前回、個人でDXやろうぜってことで、Pythonのインストールに関してお話ししました。
(中略)
良かったら、使ってみたり、いじってみたりしてください。
次回は、このプログラムを試すためのデータを作成したプログラムを紹介します。
ではでは今回はこんな感じで。きっちり本文の領域だけをテキストで取得できるようになりました。
これができるようになるとウェブサイトからjanemeを使って形態素解析をしたり、WordCloudを作れるようになるので、ちょっと楽しみが広がります。

その話はまた別の機会にすることにして、次回はhtmlではなくxmlの解析を行ってみたいと思います。

ではでは今回はこんな感じで。
コメント