ワードクラウド
今回はワードクラウドなるものを試してみようと思います。
ワードクラウドとは、文章の中の単語の頻出割合でその単語の文字の大きさや色を変え、画像に配置し、文章をイメージとして捉えられるようにしたものです。
例えば、こちらの記事の最初のパラグラフをワードクラウドにしてみました。
するとこんな感じです。

なかなか面白いと思いませんか?
ということで試していきましょう。
ライブラリのインストール
まずは今回使用するライブラリのインストールを行います。
今回使用するのは、「janome」、「WordCloud」、そして「matplotlib」です。
matplotlibに関しては前にも使用していますので、インストールされていることと思います。
ですので「janome」と「WordCloud」をインストールしていきます。
ライブラリのインストール方法はこちらの記事で解説しています。

といいつつも最近はJupyter Notebook上で「pip」コマンドを使うことをよくやります。
pip install janome
pip install wordcloudインストールができたらプログラムを組んでいきましょう。
janomeを使った形態素解析
まずはjanomeを使って、文章を名詞や動詞、助詞などに分解、そして分類していきます。
細かいことはまた次回解説することにして、今回は流れを解説することにします。
その部分のプログラムはこんな感じです。
from janome.tokenizer import Tokenizer
data = "明日天気になぁれ"
tk = Tokenizer()
tokens = tk.tokenize(data)
words = []
for token in tokens:
token_list = token.part_of_speech.split(",")
if token_list[0] == "名詞" and token_list[1] != "非自立":
words.append(token.surface)
words = " ".join(words)まずjanomeの「Tokenizer」というライブラリをインポートします。
from janome.tokenizer import Tokenizerそして「data = “明日天気になぁれ”」の部分はワードクラウドにする文章です。
ということで好きなように変更してもらって大丈夫です。
次にTockenizerのクラスを読み込み、さらに先ほどの文章を読み込み解析します。
tk = Tokenizer()
tokens = tk.tokenize(data)次に解析した結果のリスト「token」を一つずつ読み込み、名詞に当たるものだけリストwordsに格納します。
words = []
for token in tokens:
token_list = token.part_of_speech.split(",")
if token_list[0] == "名詞" and token_list[1] != "非自立":
words.append(token.surface)最後にWordCloudに渡すため、リスト形式ではなく、スペースで区切った文字列形式に変更します。
words = " ".join(words)WordCloudによる画像化
次にWordCloudを使って画像化していきます。
そのプログラムがこちら。
from wordcloud import WordCloud
wordcloud = WordCloud(background_color="white",font_path=r"/System/Library/Fonts/Hiragino Sans GB.ttc", width=800,height=600).generate(words)
wordcloud.to_file("./sample.png")1行目がWordCloudのインポート。
2行目が画像データへ変換。
3行目が画像ファイルの書き出しです。
こんな感じでたった3行でワードクラウドの画像が出来上がるのはすごいですよね。
ただ一つ重要なのがフォントの読み込みです。
今回のように日本語の文章の時、デフォルトのフォントでは日本語が含まれていないため表示することができず、こんな感じになってしまいます。

そこで「font_path=r”/System/Library/Fonts/Hiragino Sans GB.ttc”」のように日本語を含んだフォントを指定することが必要です。
Macのフォントの保存場所はこちらの記事で解説されています。
Windowsのフォントの保存場所はこちらの記事で解説されています。

フォントを指定した場合はこんな感じになります。

Jupyter Notebook上での表示
ここまでで画像ファイルとして保存することができましたが、せっかくなのでJupyter Notebook上での表示の仕方も解説しておきます。
Jupyter Notebook上で表示するには、「matplotlib」を用います。
import matplotlib.pyplot as plt
plt.imshow(wordcloud)
plt.axis("off")
plt.show()「imshow」を使って画像を読み込み、「plt.show()」で表示するというだけです。
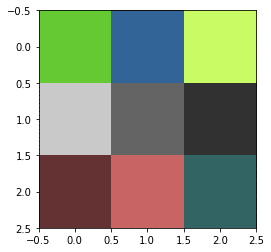
表示された画像はこんな感じです。

ただしその際に軸の表示が邪魔になるので、「plt.axis(“off”)」で軸を削除しています。
ちなみに軸を削除しないこちらのプログラムだとこんな感じで表示されます。
import matplotlib.pyplot as plt
plt.imshow(wordcloud)
plt.show()
これでワードクラウドを作成することができました。
次回はせっかくなので形態素解析ライブラリ「janome」に関して少し解説してみようと思います。

ではでは今回はこんな感じで。
コメント