Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」の「タイタニック号乗客の生存予測」のデータセットの内容を眺めてみました。
今回はとりあえず難しいことを考えずに機械学習して、スコアを出してみようと思います。
そこでまず決める必要があるのは、どのモデルを使うのかということ。
前にもお話しした通り、Scikit-learnにはどのモデルを使うと良いか、ある程度教えてくれるチートシートなるものがあります。
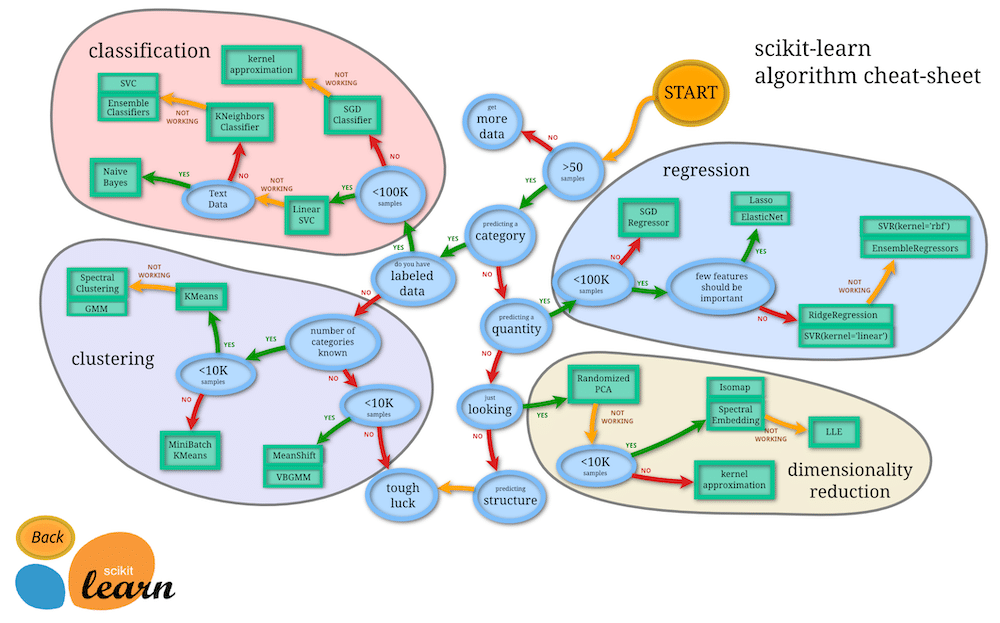
このチートシートから考えるに、今回は「classification(分類)」のカテゴリに入るかと思います。
そこでclassificationの基本的なモデルである「LinearSVC」を今回は使ってみましょう。
ということで始めていきましょう。
データの読み込みと学習用データの選択
まずはデータを読み込んでいきます。
<セル1>
import pandas as pd
train = pd.read_csv("train.csv")
train
実行結果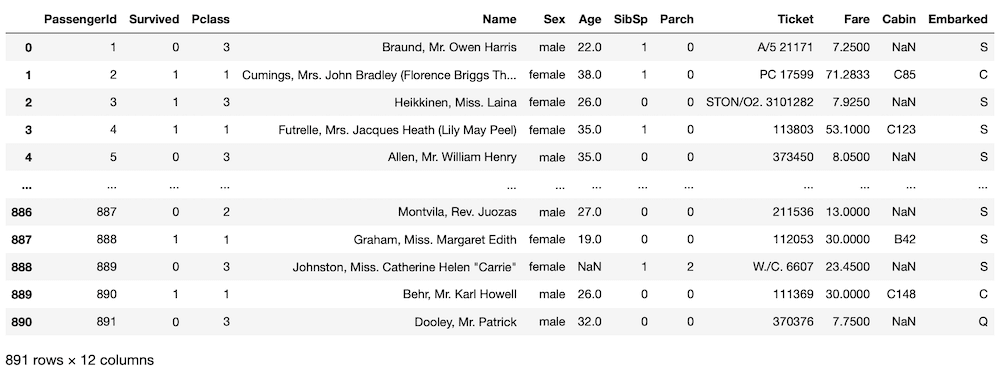
次に学習用の特徴量を変数xに、予想する値であるターゲットを変数yに格納します。
今回、変数xにはとりあえず欠損値が無くて、単純な値になっている「Pclass」、「Sex」、「SibSp」、「Parch」、「Fare」を使っていきます。
変数yはもちろん「Survived」です。
<セル2>
x = train.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare"]]
y = train.loc[:, ["Survived"]]
実行結果こちらは実行しても何も表示されません。
機械学習を実行(1回目)
それでは機械学習を行っていきます。
今回使うのは「LinearSVC」モデルということ、こちらの記事でプログラミングの仕方を紹介しています。
ということで今回も同様のプログラムを使ってみましょう。
<セル3>
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC()
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-6-047c88ba8046> in <module>
6
7 model = LinearSVC()
----> 8 model.fit(x_train, y_train)
9 pred = model.predict(x_test)
10
(中略)
/opt/anaconda3/lib/python3.7/site-packages/numpy/core/_asarray.py in asarray(a, dtype, order)
83
84 """
---> 85 return array(a, dtype, copy=False, order=order)
86
87
ValueError: could not convert string to float: 'male'エラーが出てしましました。
問題点は「could not convert string to float: ‘male’」ということで、「Sex」の値である「male」、「female」は文字のままでは使えず、数字(float値=小数値)にしなければいけないようです。
ということで「male」を0、「female」を1に変換しましょう。
<セル4>
train.loc[train["Sex"] == "male", "Sex"] = 0
train.loc[train["Sex"] == "female", "Sex"] = 1
train
実行結果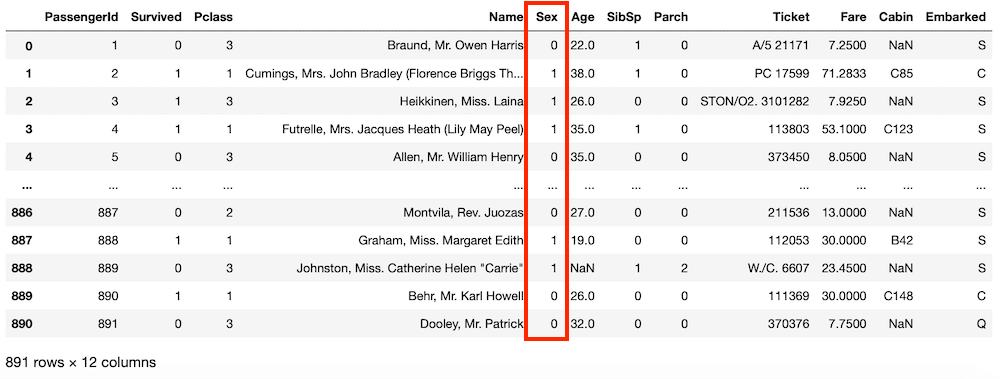
「Sex」の列が0と1のデータに無事変換されました。
機械学習を実行(2回目)
それでは新しいセルでもう一度実行してみましょう。
<セル5>
x = train.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare"]]
y = train.loc[:, ["Survived"]]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC()
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.8268156424581006
/opt/anaconda3/lib/python3.7/site-packages/sklearn/utils/validation.py:73: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/opt/anaconda3/lib/python3.7/site-packages/sklearn/svm/_base.py:977: ConvergenceWarning: Liblinear failed to converge, increase the number of iterations.
"the number of iterations.", ConvergenceWarning)スコアは出てきた、つまり機械学習はできたのですが、何やら二つ警告が出てきました。
最初の警告は、「DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().」ということで、変数yの形式がおかしいということです。
1次元([a, b, c, d, e]のようなデータ)の答えが予想されるはずなのに、変数yは多次元([[a, b,][c, d,e]]のようなデータ)になってしまっているようです。
これは私がデータの渡し方を間違えたわけで「y = train.loc[:, [“Survived”]]」と変数yを定義していますが、「y = train[“Survived”]」とすれば良かったのです。
次に「Liblinear failed to converge, increase the number of iterations.」は前にも出てきた警告です。
こちらはモデルを読み込む際に「max_iter」を設定してやれば解消します。
機械学習を実行(3回目)
先ほどの2点を修正したプログラムがこちらです。
<セル6>
x = train.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare"]]
y = train["Survived"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC(max_iter=10000000)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.7988826815642458今回は特にエラーも警告も出ずに終了しました。
これでとりあえず機械学習モデルは完成しました。
次回はこのモデルを使って、テスト用データセット「test.csv」の中の乗客の生存予想をしていきましょう。

ということで今回はこんな感じで。
コメント