Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」の「タイタニック号乗客の生存予測」のデータセットをJupyter Notebookで読み込んでみました。
今回はデータセットを眺めて、何をしなければいけないのか一つ一つ確認していきましょう。
まず必要なのは訓練用データセットなので、「train.csv」に集中してデータを見ていくことにしましょう。
ということでデータセットの読み込みから。
<セル1>
import pandas as pd
train = pd.read_csv("train.csv")
train
実行結果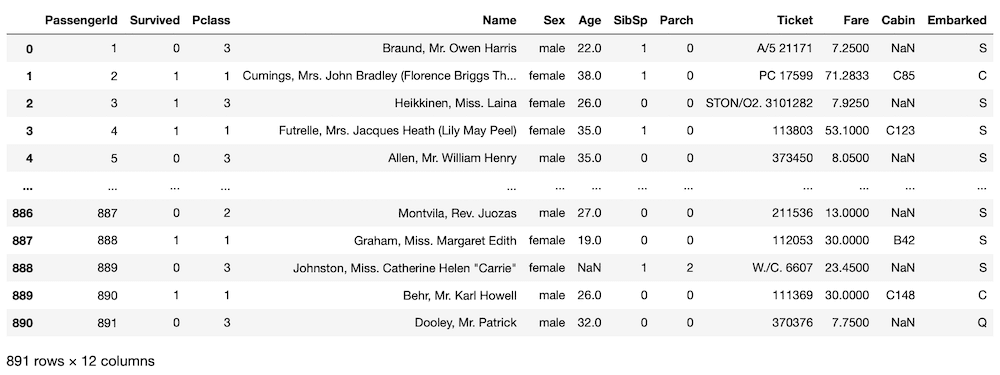
データセットを読み込めたところで、特徴量を見ていきましょう。
特徴量を確認してみる
一つ一つ特徴量を確認していきましょう。
Passengerid:乗客ID。
Survived:生存か死亡か。生存していれば1、死亡なら0。こちらは予想するターゲット(今更ですが目的変数というらしい)
Pclass:チケットの等級。1st(1等)、2nd(2等)、3rd(3等)
Name:乗客の名前
Sex:性別
Age:年齢
Sibsp:兄弟姉妹、配偶者の人数。
Parch:親・子供の数。
Ticket:チケット番号
Fare:料金
Cabin:部屋番号
Embarket:乗船地
これらのデータから生存予想モデルを組み立てていくことになります。
データの欠損を確認
次にデータに欠損値があるか確認してみましょう。
Pandasのデータフレームにおける欠損値の確認に関しては、こちらの記事で解説していますので、良かったらこちらもどうぞ。
欠損値を確認するには「データフレーム名.isnull().sum()」です。
<セル2>
train.isnull().sum()
実行結果
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64「Age(年齢)」、「Cabin(客室番号)」、「Embarked(乗船地)」の3つの特徴量に欠損値があることが分かりました。
「Cabin(客室番号)」は891人のデータ中、687人のデータが欠損しており、これを復元するのはなかなか難しそうということと、客室のグレードに関しては「Pclass(チケットの等級)」や「Fare(料金)」で代替できそうなので、とりあえずは使わない方針にしましょう。
「Embarked(乗船地)」は欠損が2つだけなので、何らかの形で推測するか、もしくは適当に決めてしまっても大きな影響は与えなさそうです。
「Age(年齢)」は891人のデータ中、177人のデータが欠損していますが、こちらは「Name(名前)」と「SibSp(兄弟、配偶者の数)」や「Parch(親、子供の数)」から少しずつ埋めていけそうですので、ちょっと頑張って埋めてみましょう。
分布をみてみる
後はとりあえずすぐに表示できそうなものだけですが、分布を表示してみましょう。
Pandasで分布図(ヒストグラム)を表示する方法はこちらの記事で解説していますので、良かったらどうぞ。
とりあえず表示するには「データフレーム名[“データ名”].hist()」で表示できます。
表示できそうな特徴量としては、「Survived(生存か死亡か)」、「Pclass(チケットの等級)」、「Sex(性別)」、「Age(年齢)」、「SibSp(兄弟、配偶者の数)」、「Parch(親、子供の数)」、「Fare(料金)」 、「Embarked(乗船地)」です。
ということで分布図を表示していきましょう。
Survived(生存か死亡か)
<セル3>
train["Survived"].hist()
実行結果
Pclass(チケットの等級)
<セル4>
train["Pclass"].hist()
実行結果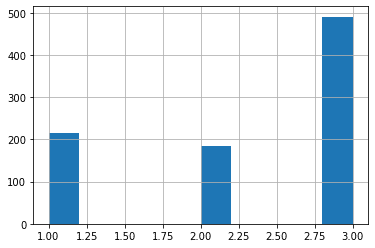
Sex(性別)
<セル5>
train["Sex"].hist()
実行結果
Age(年齢)
<セル6>
train["Age"].hist()
実行結果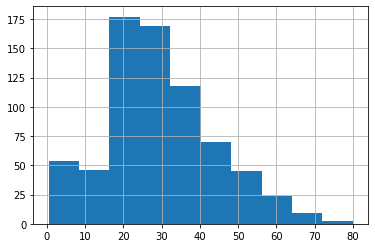
SibSp(兄弟、配偶者の数)
<セル7>
train["SibSp"].hist()
実行結果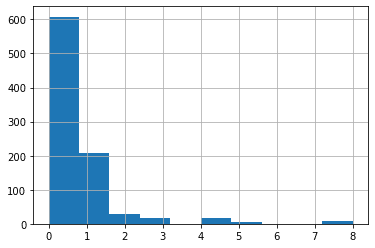
Parch(親、子供の数)
<セル8>
train["Parch"].hist()
実行結果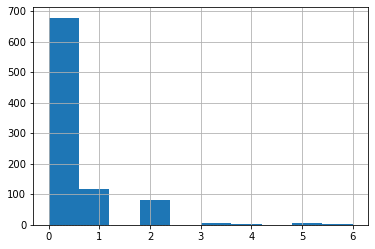
Fare(料金)
<セル9>
train["Fare"].hist()
実行結果
Embarked(乗船地)
<セル10>
train["Embarked"].hist()
実行結果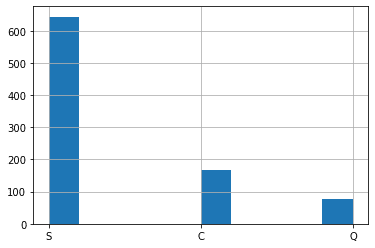
とりあえず今回はデータセットを眺めてみましたが、いかがでしたでしょうか?
何となくこのデータセットの雰囲気は掴めてきたでしょうか?
次回はとりあえずすぐに使えそうな特徴量を使って、早速機械学習してみたいと思います。
ではでは今回はこんな感じで。
コメント