Pythonの辞書とは?
Pythonで辞書というと、前に解説したリストのようにいくつかのデータを格納する仕組みのようです。

リストは前にやった通り、こんな形でした。
a = [1, 2, 3, 4, 5]
print(a[1])
実行結果
2辞書は「キー」と「値」を組み合わせ、格納するらしいです。
a = {"key1":1, "key2":2, "key3":3, "key4":4, "key5":5}
print(a["key3"])
実行結果
3辞書の場合は、[ ] ではなく、{ } を使い、「キー:値」と言う形で格納していくそうです。
そして呼び出す時は、「キー」を用いて「値」を呼び出すんだそうです。
個人的にこの書き方はどうも慣れないので、使ったことはありません。
(みんな使っているんだろうか?なんて思ってみたり…)
プログラミングが仕事の方やチームで開発している方は、こう言った基礎的なこともしっかり学んだほうがいいと思いますので、詳しく解説しているサイトを紹介しておきます。

その代わりに私が使用しているのが、Bunchというちょっと違った辞書です。
今回はそのBunchのお話。
Bunchのインストール
BunchはAnacondaに最初からは入っていないので、最初に自分でインストールする必要があります。
Bunchのインストール方法は、Anacondaの使い方を紹介した時に、一緒に紹介しましたが、今一度紹介しておきます。

まずAnaconda-Navigatorから「Qt Console」を起動します。
起動すると新しいウインドウが開きます。
新しいコンソールが開きますので、下記のコードを書いて、Shift+Enter。
pip install bunch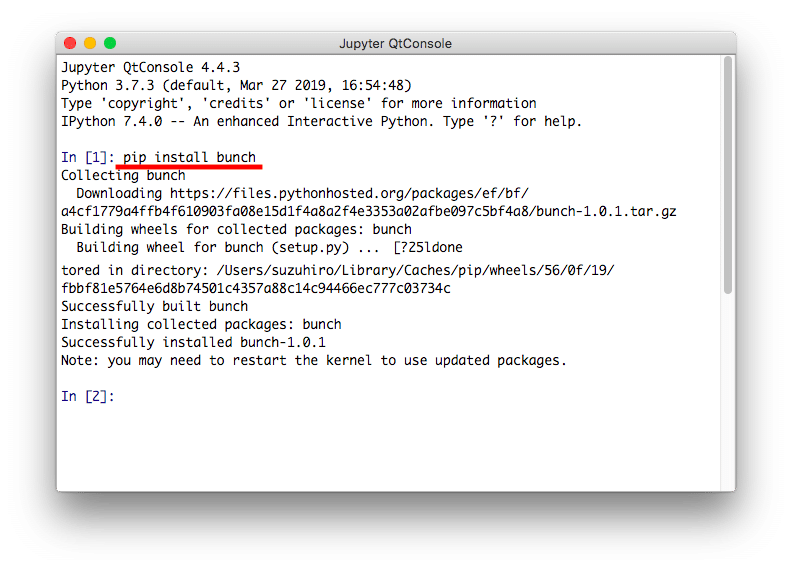
「Successfully installed bunch-1.0.1」と表示され、インストール完了です。
ただ、最後の「1.0.1」はバージョン番号なので、アップデートされていたら、違うかもしれません。
これでインストール完了です。
ちなみにsklearnというパッケージを入れても付いてくるらしいです。
Bunchの基本的な使い方
Bunchを使うにはまずインポートする必要があります。
from bunch import BunchBunchを直接インストールせず、sklearnを入れた方は、こんな感じでインポートできます。
from sklearn.datasets.base import Bunchそしてまずは空のデータセットを作ります。
from bunch import Bunch
data1 = Bunch()
print(data1)
実行結果
{}この空のデータセットにデータを入れるには、データ名とデータを放り込む感じです(分かりにくい…)。
from bunch import Bunch
data1 = Bunch()
data1.time = [0, 1, 2, 3, 4, 5]
print(data1.time)
実行結果
[0, 1, 2, 3, 4, 5]data1.timeのところをもう少し分解して説明するとこんな感じです。
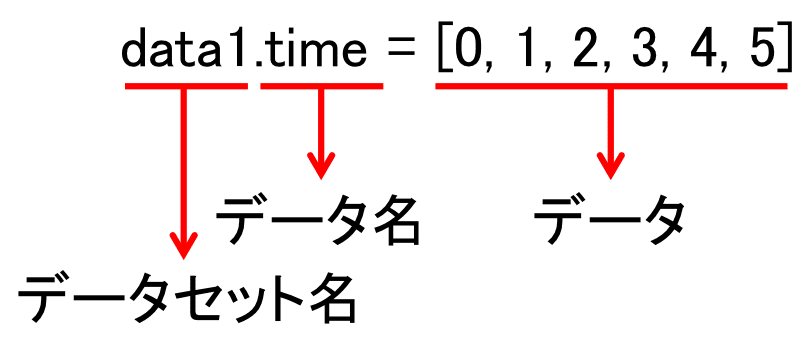
このデータセットに対し、他のデータ(今回はtempとします)を入れ込むことも可能です。
from bunch import Bunch
data1 = Bunch()
data1.time = [0, 1, 2, 3, 4, 5]
data1.temp = [5, 10, 15, 20, 25, 30]
print(data1.time)
print(data1.temp)
実行結果
[0, 1, 2, 3, 4, 5]
[5, 10, 15, 20, 25, 30]私の場合は今回紹介したように、例えば時間だったり、温度だったりとそれぞれのデータを別のデータ名として保存することが多いです。
またそれぞれのデータを呼び出す時は、データセット名.データ名で呼び出せますし、さらに今回の例のようにリストを格納した場合、そのままインデックス指定も可能です。
from bunch import Bunch
data1 = Bunch()
data1.time = [0, 1, 2, 3, 4, 5]
print(data1.time)
print(data1.time[2])
実行結果
[0, 1, 2, 3, 4, 5]
2またデータセットの中に入れたデータ名を一覧で取得するには、keys()を用います。
from bunch import Bunch
data1 = Bunch()
data1.time = [0, 1, 2, 3, 4, 5]
data1.temp = [5, 10, 15, 20, 25, 30]
print(data1.keys())
実行結果
dict_keys(['time', 'temp'])データをBunchに格納した後、keys()を使ってデータ名を表示させると、ちゃんと格納されているか簡単に確認できます。
とりあえずBunchに関してはこんな感じです。
Bunchに関してのちょっとした後書き
しかしなぜBunchを使うようになったかと言うと、一時期機械学習をやろうと思って、sklearnを学んでいたんですが、その時に使用されていた辞書がBunchだったんです。
で最近、また機械学習に関して調べてみたら、pandasというデータ分析のライブラリを使っている人が多いように思います。
またBunchを使い始めた時も、あまり情報が見当たらなく、苦労したことを覚えています。
もしかしたらあまり主流ではないのでしょうか?
個人的にはしっくりくるし、使いやすくて好きなのですが、スタンダードな辞書クラスを学んだり、pandasを学んだりしたいなぁと思う今日この頃です。
次回はその辞書に関する基本知識と使い方に関して解説をしていきます。

ということで今回はこんな感じで。
コメント