データ解析支援ライブラリPandas
前回はPandasの.plot()で出力されるグラフを、matplotlibの機能を使っていじってみました。
今回はグラフから離れて、Pandasでデータの概要を確認する方法を解説していきます。
これまで解説で用いてきたデータはあまり大きくないデータを用いていましたが、実際データ解析をする場合にはもっと大量のデータを扱います。
そのためデータ全部を見るのはかなり大変。
そんな場合、データの性質や数などを概要として確認していきます。
そしてそんな機能がPandasには搭載されているので、その機能を今回紹介しようというわけです。
ということで準備をしていきましょう。
データはランダムデータ作成プログラムで新たに作成したこちらのデータを用います。
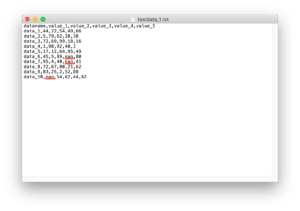
データの読み込みはこんな感じです。
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv("python-pandas-22_data1.txt", index_col=0)
df
実行結果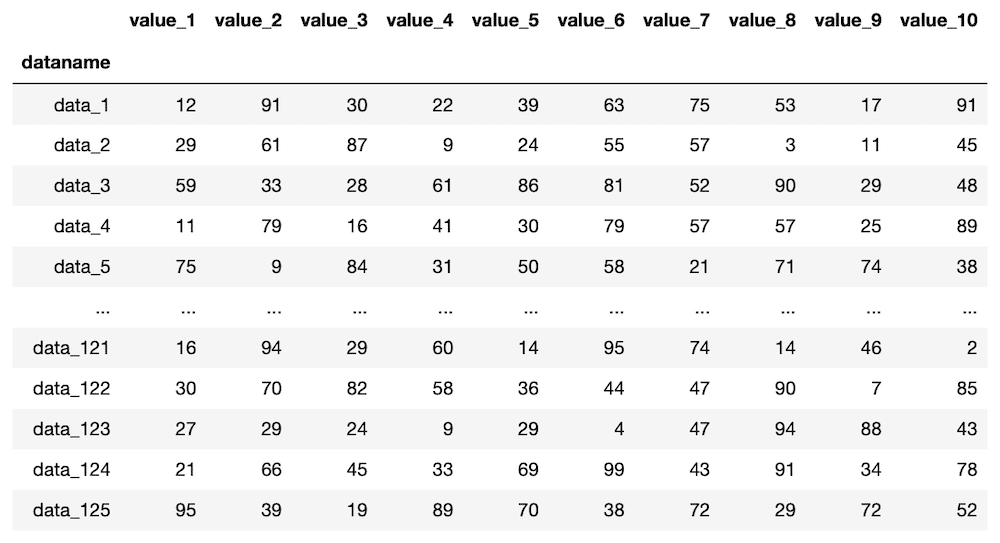
ということで始めていきましょう。
最初のX行を表示:.head(行数)
データの特性を確認するのに、数行だけ見てみるというのは重要なことです。
そこで最初の数行を見るコマンドを見てみましょう。
最初の数行を表示するには「.head(行数)」で表示できます。
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv("python-pandas-22_data1.txt", index_col=0)
df.head(10)
実行結果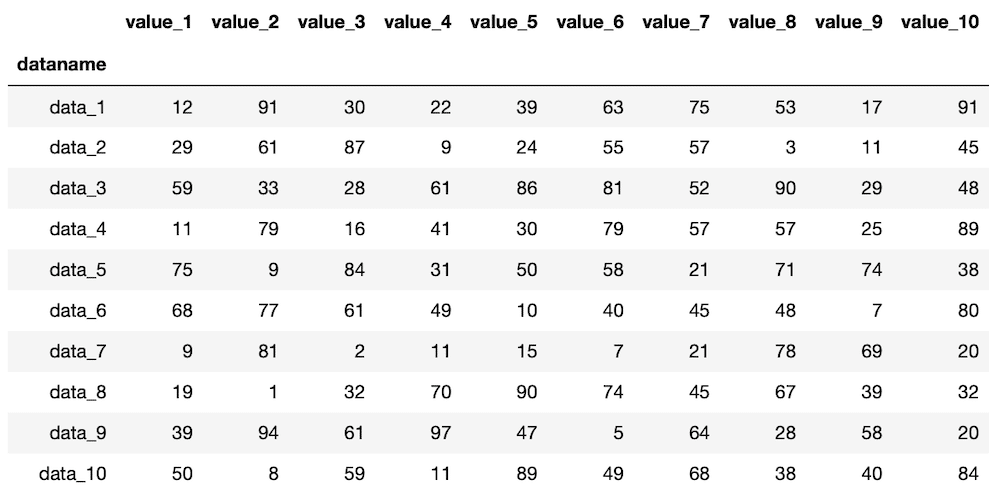
ちなみに行数を入れないと、最初の5行が表示されます。
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv("python-pandas-22_data1.txt", index_col=0)
df.head()
実行結果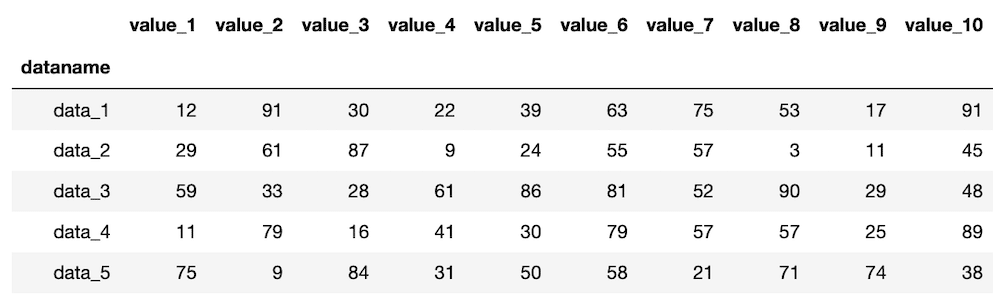
最後のX行を表示:.tail(行数)
ファイルの後ろから見る場合は「.tail(行数)」で確認することができます。
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv("python-pandas-22_data1.txt", index_col=0)
df.tail(10)
実行結果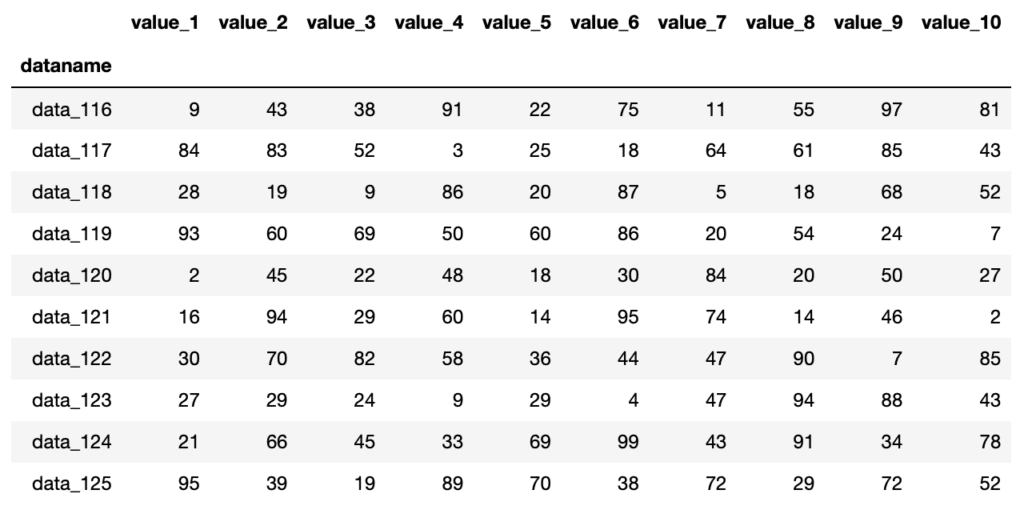
こちらも行数を指定しなかったら、後ろから5行が表示されます。
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv("python-pandas-22_data1.txt", index_col=0)
df.tail()
実行結果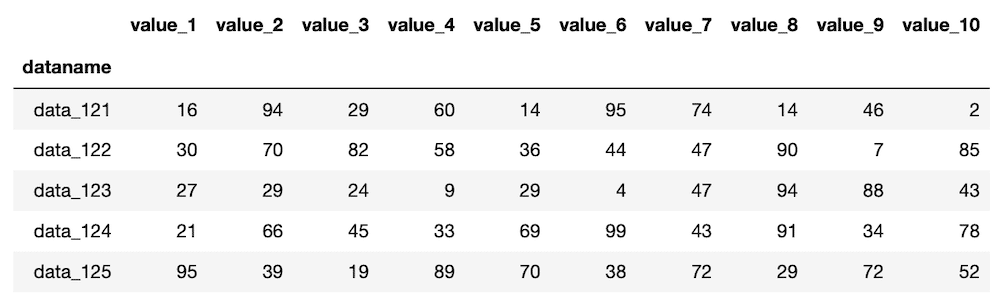
統計情報を表示:.describe()
データの統計情報を表示を表示するには「.describe()」を使います。
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv("python-pandas-22_data1.txt", index_col=0)
df.describe()
実行結果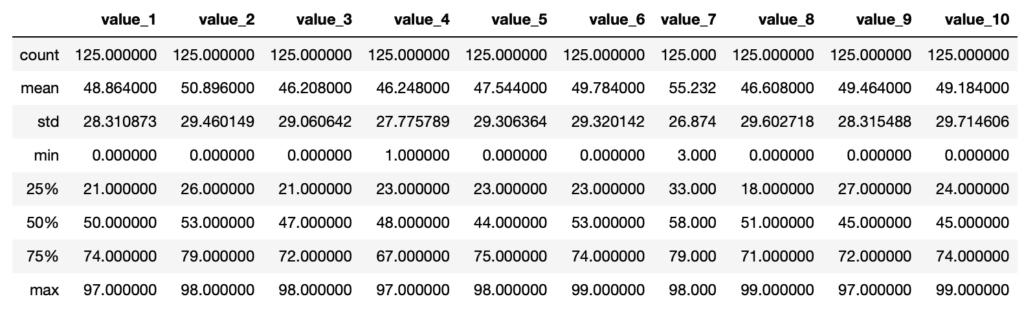
| Count | その列のデータの数 |
| mean | 平均値 |
| std | 標準偏差 |
| min | 最小値 |
| 25% | データ数が全データ数の25%となるところのデータの値(第1四分位数) |
| 50% | データ数が全データ数の50%となるところのデータの値(第2四分位数) |
| 75% | データ数が全データ数の75%となるところのデータの値(第3四分位数) |
| max | 最大値 |
列数、列名、行数、データ型を表示:.info()
列数、列名、行数、データ型などデータの大まかな形を知るには「.info()」を用います。
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv("python-pandas-22_data1.txt", index_col=0)
df.info()
実行結果
<class 'pandas.core.frame.DataFrame'>
Index: 125 entries, data_1 to data_125
Data columns (total 10 columns):
value_1 125 non-null int64
value_2 125 non-null int64
value_3 125 non-null int64
value_4 125 non-null int64
value_5 125 non-null int64
value_6 125 non-null int64
value_7 125 non-null int64
value_8 125 non-null int64
value_9 125 non-null int64
value_10 125 non-null int64
dtypes: int64(10)
memory usage: 10.7+ KB今回はPandasのデータ概要を表示する方法を解説しました。
最初にも少しお話ししたのですが、データ解析をする場合、データの規模が大きくなればなるほど、全部のデータを確認するのは困難になります。
そこでこういった統計値を利用して、大体の傾向を掴むということが重要になってきます。
私も今後データ解析や機械学習なんかをしっかり学んでいきたいと思っているので、こういったことを少しずつ積み重ねていきたいと思っています。
次回は前に作成したダミーデータ作成プログラムをさらに改変していきたいと思います。
ということで今回はこんな感じで。
コメント