機械学習用データ
今回は前に作成したダミーデータ作成プログラムをさらにアップデートしていこうと思います。
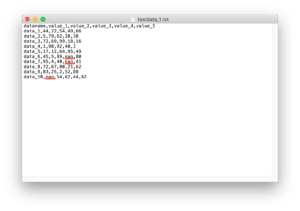
今回変更する点としては、一番最後の列に教師ありの機械学習で使う予想する結果の列「target」を出力するという点です。
出力する結果としてはこんな感じ。
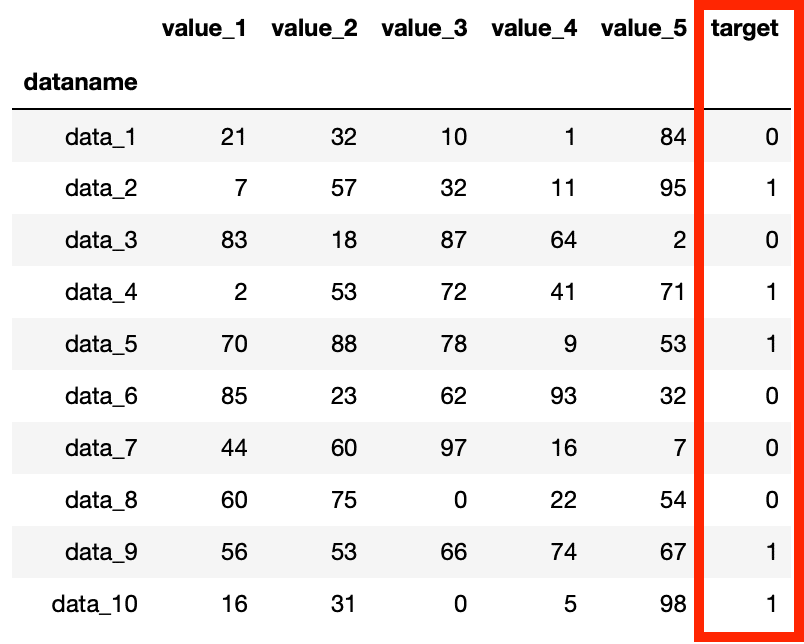
「target」の列の「1」、「0」が予想したい結果になり、「value」の列が項目ごとのデータという形になります。
もちろんこのダミーデータの数値はランダムで選んでいるため、これでまともな答えが出る機械学習データとはなりませんが、いろんなスキルを磨くのにいいかなと思います。
まだ3PySciでは機械学習に関しては触れていないので、なんのこっちゃと思う方もいるかもしれませんが、先を見据えてということで今後の記事を楽しみにしていてください。
ということでまずはおさらいから。
・ライブラリインポート
import csv
import random
import numpy as np・セッティング
file_name_head = "testdata_"
file_name_end = ""
file_ext = ".txt"
data_name_head = "data_"
data_name_end = ""
value_name_head = "value_"
value_name_end = ""
index_name = "dataname"
no_files = 1
rows = 10
columns = 5
random_range = [0, 99]
nan_val = range(100, 200)・メインプログラム
for no_file in range(no_files):
filename = file_name_head + str(no_file + 1) + file_name_end + file_ext
# print(filename)
f = open(filename, "w")
writer = csv.writer(f)
header = [index_name]
for column in range(columns):
valuename = value_name_head + str(column + 1) + value_name_end
header.append(valuename)
writer.writerow(header)
for row in range(rows):
data = []
dataname = data_name_head + str(row + 1) + data_name_end
data.append(dataname)
for column in range(columns):
random_val = random.randint(random_range[0], random_range[1])
if random_val in nan_val:
random_val = np.nan
print(random_val)
data.append(random_val)
writer.writerow(data)
f.close()
print("Done")それではアップデートしていきましょう。
セッティング
セッティングのセルにtarget列用のプログラムを追加していきます。
といっても追加するのはたった2行です。
まずはターゲット列の名前のための変数です。
target_name = "target"ターゲット列に用いる値のリストです。
target_val = [0, 1]ターゲット列はこのリストからランダムに数値が割り当てられます。
ということでセッティング全体としてはこんな感じになります。
#Settings
file_name_head = "testdata_"
file_name_end = ""
file_ext = ".txt"
data_name_head = "data_"
data_name_end = ""
value_name_head = "value_"
value_name_end = ""
target_name = "target"
index_name = "dataname"
no_files = 1
rows = 20
columns = 5
target_val = [0, 1]
random_range = [0, 99]
nan_val = range(100, 200)メインプログラム
次にメインプログラムのアップデートをしていきます。
まずは名前の行に「target列の名前」を追加するプログラムを追加します。
if len(target_val) > 1:
header.append(target_name)「target_val」のリストに含まれる要素数が2以上の場合のみ、「target」の列を追加します。
要素数が1以下だと全部同じ値になり、データの意味がないので、2以上としています。
追加するのはここです。
header = [index_name]
for column in range(columns):
valuename = value_name_head + str(column + 1) + value_name_end
header.append(valuename)
if len(target_val) > 1: #new
header.append(target_name) #new
writer.writerow(header)次にデータを書き出す際も「target_val」の要素数が2以上であり、そのリストからランダムに選択するようにします。
ということでこの2行を追加します。
if len(target_val) > 1:
data.append(random.choice(target_val))追加するのはここです。
for column in range(columns):
random_val = random.randint(random_range[0], random_range[1])
if random_val in nan_val:
random_val = np.nan
print(random_val)
data.append(random_val)
if len(target_val) > 1: #new
data.append(random.choice(target_val)) #new
writer.writerow(data)ということでメインプログラムはこんな感じになります。
#Main
for no_file in range(no_files):
filename = file_name_head + str(no_file + 1) + file_name_end + file_ext
# print(filename)
f = open(filename, "w")
writer = csv.writer(f)
header = [index_name]
for column in range(columns):
valuename = value_name_head + str(column + 1) + value_name_end
header.append(valuename)
if len(target_val) > 1:
header.append(target_name)
writer.writerow(header)
for row in range(rows):
data = []
dataname = data_name_head + str(row + 1) + data_name_end
data.append(dataname)
for column in range(columns):
random_val = random.randint(random_range[0], random_range[1])
if random_val in nan_val:
random_val = np.nan
print(random_val)
data.append(random_val)
if len(target_val) > 1:
data.append(random.choice(target_val))
writer.writerow(data)
f.close()
print("Done")出力データの確認
ということでこのプログラムを実行して、データを確認してみましょう。
データファイルは「testdata_1.txt」として出力されるので、Pandasで読み込んで出力してみましょう。
import pandas as pd
df = pd.read_csv("testdata_1.txt", index_col = 0)
df.head(10)
実行結果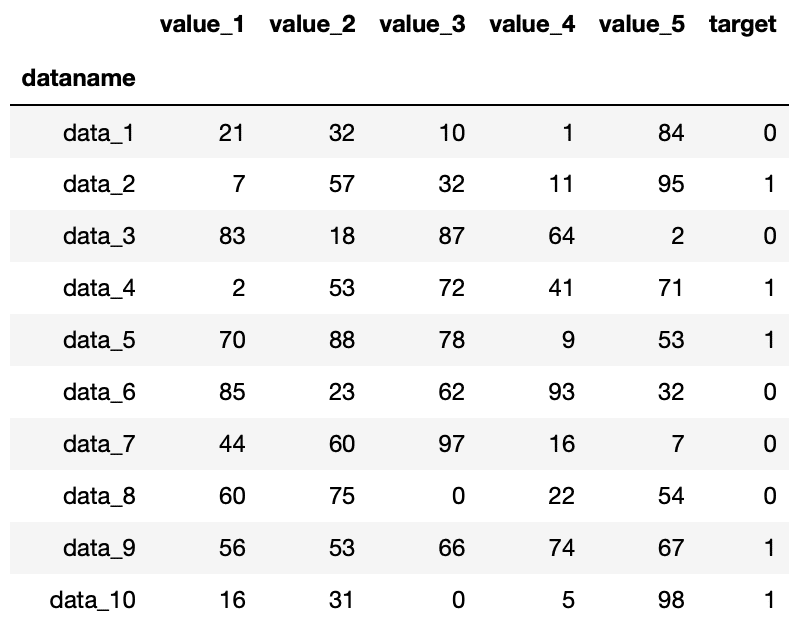
確かに「target」の列が追加され、「0」か「1」が割り当てられています。
ということでアップデート完了です。
プログラムをGitHubにアップロードしていますので、良かったらそちらもご覧ください。
次回はこのダミーファイルを使って、seabornというグラフ表示ライブラリを試していきます。
ではでは今回はこんな感じで。
コメント