re
前回、numpyで値が同じか(equal, not_equal, array_equal)、大きいか(greater, greater_equal)、小さいか(less, less_equal)を判定する方法を紹介しました。
今回からは正規表現を勉強してみます。
初回としてはとりあえずざっくりと正規表現とはなんぞやというのを捉えてみようと思っています。
正規表現を一言で説明すると「さまざまな類似した文字列を一つの形式で表現する方法」です。
このままでは分かりにくいですが、例えばメールアドレスやウェブサイトのURLは必ず一定の形式となっています。
メールアドレスなら「xxx@yyy.zzz」、ウェブサイトのURLなら「http://xxx.yyy」や「https://xxx.yyy」といった感じです。
ただxもyもzもそれぞれのメールアドレス、ウェブサイトで異なります(だからこそ一意で決まるのですが)。
形式は同じだけども、それぞれの文字列(値)が違うものを一つの形式で表現する方法が正規表現です。
通常この正規表現を使って、文字列から特定の形式を持った文字列(例えばメールアドレスやウェブサイトのURLなど)を抽出するのに用います。
それでは始めていきましょう。
とりあえず使ってみる
まずPythonで正規表現を使うには「re」モジュールをインポートします。
そしてreモジュールには正規表現と文字列がどうマッチするかによって、色々な文字列の抽出法があります。
今回はとりあえず文字列の先頭がマッチするかチェックする「match(正規表現, 探索する文字列)」を使ってみます。
import re
query1 = "https://abc.com"
query2 = "https://def.org"
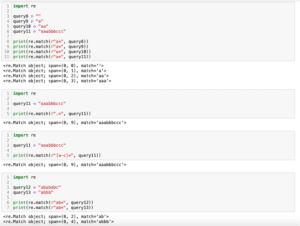
print(re.match(r"https://[a-z]+\.com", query1))
print(re.match(r"https://[a-z]+\.com", query2))
実行結果
<re.Match object; span=(0, 15), match='https://abc.com'>
None「query1」、「query2」というのが正規表現とマッチする文字列が入っているか探索する文字列です。
今回は「https://[a-z]+.com」という正規表現を用いてみました。
入力した文字列が正規表現であるとするには「r”文字列”」とすることに注意してください。
この正規表現は文字列として「https://」で始まっているか、そして「[a-z]+\.com」では「aからzまでの文字が1つ以上」あり、さらに最後に「.com」で終わっている文字列を示しています。
「\(バックスラッシュ)」はエスケープ文字としてこの後に来る文字が特殊な意味を持たず、単純に文字列として認識するようにしています。
逆にいうとこのエスケープ文字を使わない場合、その文字が特殊な意味を持つということです。
「query1」と「query2」を見てみると、「https://abc.com」と「https://def.org」となっています。
どちらも「https://」で始まり、「aからzまでの文字が1つ以上ある」というところまでは同じで、正規表現とマッチしていますが、最後の「.com」に関しては「query2」では満たしていません。
そのため「query2」の結果は「None」となりました。
複数の文字列の範囲を指定
先ほどは「https://」、「aからzまでの文字が1つ以上ある」、「.com」という正規表現を用いましたが、「https://abc123.com」という場合はどのような正規表現を用いたらいいでしょうか?
もちろん「https://」、「aからzまでの文字が1つ以上ある」、「.com」では「None」となってしまいます。
import re
query3 = "https://abc123.com"
print(re.match(r"https://[a-z]+\.com", query3))
実行結果
None「abc」に「123」が続いているので「aからzまでの文字が1つ以上」、さらにその後に「0から9までの数字が一つ以上」としてみましょう。
「0から9までの数字が一つ以上」は「[0-9]+」と書きます。
import re
query3 = "https://abc123.com"
print(re.match(r"https://[a-z]+[0-9]+\.com", query3))
実行結果
<re.Match object; span=(0, 18), match='https://abc123.com'>マッチさせることができました。
ですがこの場合、URLが「https://123abc.com」となるとまたマッチできなくなってしまいます。
import re
query4 = "https://123abc.com"
print(re.match(r"https://[a-z]+[0-9]+\.com", query4))
実行結果
Noneつまりこの場合、「aからzまで、もしくは0から9までが1つ以上」とするとどちらでもマッチさせられるようになります。
import re
query3 = "https://abc123.com"
query4 = "https://123abc.com"
print(re.match(r"https://([a-z0-9]+)\.com", query3))
print(re.match(r"https://([a-z0-9]+)\.com", query4))
実行結果
<re.Match object; span=(0, 18), match='https://abc123.com'>
<re.Match object; span=(0, 18), match='https://123abc.com'>大文字・小文字をマッチ
ちなみにアルファベットの大文字と小文字も別の文字として扱われます。
つまり先ほどの「https://」、「aからzまで、もしくは0から9までが1つ以上」、「.com」という正規表現では「https://123Abc.com」はマッチさせることができません。
import re
query5 = "https://123Abc.com"
print(re.match(r"https://([a-z0-9]+)\.com", query5))
実行結果
Noneマッチさせるためみはさらに「AからZ」も追加する必要があります。
つまり「aからzまで、もしくはA-Z、もしくは0から9までが1つ以上」というわけです。
import re
query5 = "https://123Abc.com"
print(re.match(r"https://([a-zA-Z0-9]+)\.com", query5))
実行結果
<re.Match object; span=(0, 18), match='https://123Abc.com'>ここまで来ればかなりの数のURLをマッチさせられそうです。
任意の1文字
実はもっと簡単にどんなURLにもマッチさせられる方法があります。
それは「.(任意の1文字)」を使う方法です。
先ほど「.」には特殊な意味があるため、もし「.(ピリオド)」の意味として使用するためにはエスケープ文字「\(バックスラッシュ)」を使う必要があることを紹介しました。
「.」には「任意の1文字」という意味があるのです。
つまりなんでもいいけど1文字あるということです。
これと「+(前の文字が1つ以上)」を組み合わせ、「.+」とすると「任意の1文字が1つ以上」あるという意味になります。
import re
query5 = "https://123Abc.com"
print(re.match(r"https://.+\.com", query5))
実行結果
<re.Match object; span=(0, 18), match='https://123Abc.com'>この場合、これまで試してきた範囲よりも広くマッチさせることができるようになります。
どういう用途で使うかによりますが、一般的なURLを取得したい場合はこのように広い範囲でマッチさせられるものがいいでしょう。
次回は今回も出てきた「.」や「+」のような正規表現の特殊文字(メタキャラクタ)に関して勉強していきましょう。
ではでは今回はこんな感じで。
コメント