正規表現
前回、正規表現をざっくりと捉えてみました。
今回は正規表現でよく使う特殊文字(メタ文字、メタキャラクタ)を勉強していきます。
それでは始めていきましょう。
.:なんでも良い1文字
まずは「.(ピリオド)」です。
これはなんでも良い(アルファベットの大文字でも小文字でも数字でもひらがなでも感じでも、記号でも)1文字を表します。
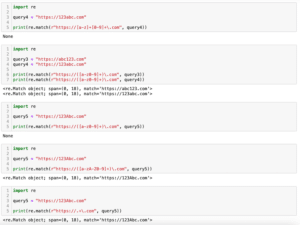
import re
query1 = "a"
query2 = "1"
query3 = "あ"
query4 = "亜"
query5 = "_"
query6 = "."
print(re.match(r".", query1))
print(re.match(r".", query2))
print(re.match(r".", query3))
print(re.match(r".", query4))
print(re.match(r".", query5))
print(re.match(r".", query6))
実行結果
<re.Match object; span=(0, 1), match='a'>
<re.Match object; span=(0, 1), match='1'>
<re.Match object; span=(0, 1), match='あ'>
<re.Match object; span=(0, 1), match='亜'>
<re.Match object; span=(0, 1), match='_'>
<re.Match object; span=(0, 1), match='.'>気をつける点はあくまでも「1文字」を表しているということ。
2文字、3文字を表したいときは、「.(ピリオド)」を2つ、もしくは3つ使うと表すことができます。
import re
query7 = "abc"
print(re.match(r".", query7))
print(re.match(r"..", query7))
print(re.match(r"...", query7))
実行結果
<re.Match object; span=(0, 1), match='a'>
<re.Match object; span=(0, 2), match='ab'>
<re.Match object; span=(0, 3), match='abc'>ちなみに何でも良いとはいっていますが、改行文字である「\n」や「\r」にはマッチしません。
*:直前の文字が0回以上繰り返す
「*(アスタリスク)」はその直前の文字が0回以上繰り返すことを表しています。
つまり「a*」とすると「aが0回以上繰り返す」ということになります。
import re
query8 = ""
query9 = "a"
query10 = "aa"
query11 = "aaabbbccc"
print(re.match(r"a*", query8))
print(re.match(r"a*", query9))
print(re.match(r"a*", query10))
print(re.match(r"a*", query11))
実行結果
<re.Match object; span=(0, 0), match=''>
<re.Match object; span=(0, 1), match='a'>
<re.Match object; span=(0, 2), match='aa'>
<re.Match object; span=(0, 3), match='aaa'>「a*」は「a*が0回以上繰り返す」時にマッチするため、「query8」のように「a」が0個でもマッチすることになります。
ちなみに先ほど出てきた「.(ピリオド)」を使い、「.*」とすると「何でもいい1文字が0回以上繰り返す」にマッチします。
import re
query11 = "aaabbbccc"
print(re.match(r".*", query11))
実行結果
<re.Match object; span=(0, 9), match='aaabbbccc'>また前回学んだように「[](角括弧)」を使って範囲を指定しつつ、0回以上繰り返すという文字にマッチさせるということもできます。
「[a-c]*」とすると「aからcまでの文字が0回以上繰り返す」となります。
import re
query11 = "aaabbbccc"
print(re.match(r"[a-c]*", query11))
実行結果
<re.Match object; span=(0, 9), match='aaabbbccc'>またあくまでも直前の文字に対してなので「ab*」だと、「aが1つ、その後ろにbが0回以上繰り返す」ということになります。
import re
query12 = "abababc"
query13 = "abbb"
print(re.match(r"ab*", query12))
print(re.match(r"ab*", query13))
実行結果
<re.Match object; span=(0, 2), match='ab'>
<re.Match object; span=(0, 4), match='abbb'>+:直前の文字が1回以上繰り返す
「+(プラス)」は直前の文字が1回以上繰り返すことを表しています。
つまり「a+」とすると「aが1回以上繰り返す」ということになります。
import re
query8 = ""
query9 = "a"
query10 = "aa"
query11 = "aaabbbccc"
print(re.match(r"a+", query8))
print(re.match(r"a+", query9))
print(re.match(r"a+", query10))
print(re.match(r"a+", query11))
実行結果
None
<re.Match object; span=(0, 1), match='a'>
<re.Match object; span=(0, 2), match='aa'>
<re.Match object; span=(0, 3), match='aaa'>直前の文字が0回以上繰り返す「*」とは違い、0回の場合はマッチしないため、「query8」のように該当文字がない場合は「None」となります。
なんでもいい1文字「.」や文字の範囲指定「[a-c]」が使えるのは「*」と同様です。
import re
query11 = "aaabbbccc"
print(re.match(r".+", query11))
print(re.match(r"[a-c]+", query11))
実行結果
<re.Match object; span=(0, 9), match='aaabbbccc'>
<re.Match object; span=(0, 9), match='aaabbbccc'>直前の文字だけが対象なのも「*」と同様ですので、「ab+」だと「aが1つで、その後ろにbが1回以上繰り返す」という意味になります。
import re
query12 = "abababc"
query13 = "abbb"
print(re.match(r"ab+", query12))
print(re.match(r"ab+", query13))
実行結果
<re.Match object; span=(0, 2), match='ab'>
<re.Match object; span=(0, 4), match='abbb'>?:直前の文字が0回か1回
「?(クエッションマーク)」はその直前の文字が0回か1回あることを表します。
つまり「a?」は「aが0回か1回ある」ということをになります。
import re
query8 = ""
query9 = "a"
query10 = "aa"
query11 = "aaabbbccc"
print(re.match(r"a?", query8))
print(re.match(r"a?", query9))
print(re.match(r"a?", query10))
print(re.match(r"a?", query11))
実行結果
<re.Match object; span=(0, 0), match=''>
<re.Match object; span=(0, 1), match='a'>
<re.Match object; span=(0, 1), match='a'>
<re.Match object; span=(0, 1), match='a'>「*」と同様に「直前の文字が0回」も対象であるため、「query8」のようにその文字が無くてもマッチします。
しかしながら「0回か1回」であるため、「query10」や「query11」のように直前の文字が複数個あってもマッチするのは最初の1つだけです。
^:文字列の最初、$:文字列の最後
「^(キャレット)」は続く文字が文字列の先頭であること、「$(ドル)」はこの前の文字が文字列の最後であることを表します。
Pythonの「re.match」では正規表現が文字列の先頭からマッチするかを検討しますので、ここでは正規表現が文字列中のどこかにあるか検討する「re.search」を使って解説していきます。
import re
query14 = "abcdefg"
print(re.search(r"^abc", query14))
print(re.search(r"bcd", query14))
print(re.search(r"^bcd", query14))
print(re.search(r"efg$", query14))
print(re.search(r"def", query14))
print(re.search(r"def$", query14))
実行結果
<re.Match object; span=(0, 3), match='abc'>
<re.Match object; span=(1, 4), match='bcd'>
None
<re.Match object; span=(4, 7), match='efg'>
<re.Match object; span=(3, 6), match='def'>
None「^abc」は「abcdefg」の最初に「abc」があるのでマッチします。
次の「bcd」は「abcdefg」に含まれるのでマッチします(re.searchの場合です。re.matchの場合はマッチしません)。
「^bcd」は「abcdefg」の最初が「bcd」ではないのでマッチしません。
「efg$」は「abcdefg」の最後が「efg」であるのでマッチします。
次の「def」は「abcdefg」に含まれるのでマッチします(re.searchの場合です。re.matchの場合はマッチしません)。
「def$」は「abcdefg」の最後が「def」ではないのでマッチしません。
{}:繰り返しの回数を指定
「{}(波括弧)」を使うと繰り返しの回数を指定できます。
「{n}」はn回の繰り返し、「{n,}」はn回以上の繰り返し、「{,m}」はm回までの繰り返し、「{n,m}」はn回以上、m回以下の繰り返しとなります。
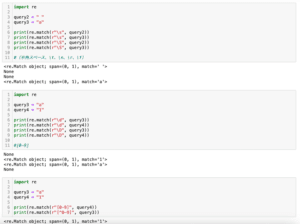
import re
query15 = "abcdeABCDE12345"
print(re.match(r"ab.{3}", query15))
print(re.match(r"ab.{2,}", query15))
print(re.match(r"ab.{,7}", query15))
print(re.match(r"ab.{2,4}", query15))
実行結果
<re.Match object; span=(0, 5), match='abcde'>
<re.Match object; span=(0, 15), match='abcdeABCDE12345'>
<re.Match object; span=(0, 9), match='abcdeABCD'>
<re.Match object; span=(0, 6), match='abcdeA'>「ab.{3}」の場合は「abと何でもいい1文字が3回」となるため、「abcde」がマッチします。
「ab.{2,}」は「abと何でもいい1文字が2回以上」となるため、「abcdeABCDE12345」がマッチします。
「ab.{,7}」は「abと何でもいい1文字が7回以下」であるため、「abcdeABCD」がマッチします。
「ab.{2,4}」は「abと何でもいい1文字が2回以上4回以下」であるため、「abcdeA」がマッチします。
ちなみに「{n,m}」はn回以上、m回”以下”であり、n回以上、m回”未満”でないことに注意してください。
rangeなんかは「range(n, m)」だとn以上、m”未満”なので注意して覚えないと間違えてしまいそうです。
次回は正規表現で使うエスケープシーケンスに関して勉強していきます。
ではでは今回はこんな感じで。
コメント