目次
re
前回、正規表現のエスケープ文字(エスケープシーケンス)でできることを紹介しました。
あわせて読みたい
【re】正規表現のエスケープ文字(エスケープシーケンス)でできること[Python]
正規表現 前回、よく使う正規表現の特殊文字(メタ文字、メタキャラクタ)をまとめてみました。 今回は正規表現のエスケープ文字(エスケープシーケンス)でできること…
今回はPythonのreモジュールで使いそうなものを紹介していきます。
それでは始めていきましょう。
match:先頭からマッチするか
これまで何度か出てきた「match」ですが、こちらは正規表現が探索文字列の先頭からマッチするかを確認するための関数です。
使い方は「match(正規表現, 探索文字列)」です。
文字列の先頭以外の場所に正規表現とマッチするものがあってもマッチしたとみなされないので注意です。
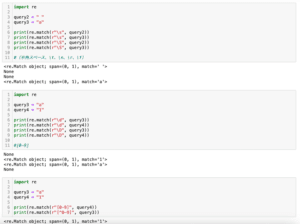
import re
query1 = "abcABC123"
print(re.match(r"abc", query1))
print(re.match(r"ABC", query1))
print(re.match(r"123", query1))
実行結果
<re.Match object; span=(0, 3), match='abc'>
None
Noneseach:文字列中のどこかにマッチするか
「search」関数では正規表現が探索文字列中に存在するかを確認できます。
「match」と違い、文字列中のどこにあっても大丈夫です。
使い方は「search(正規表現, 探索文字列)」です。
import re
query1 = "abcABC123"
print(re.search(r"abc", query1))
print(re.search(r"ABC", query1))
print(re.search(r"123", query1))
実行結果
<re.Match object; span=(0, 3), match='abc'>
<re.Match object; span=(3, 6), match='ABC'>
<re.Match object; span=(6, 9), match='123'>fullmatch:文字列全体とマッチするか
「fullmatch」では、正規表現が文字列の全体とマッチするかを確認できます。
使い方は「fullmatch(正規表現, 探索文字列)」です。
import re
query1 = "abcABC123"
print(re.fullmatch(r"[a-zA-Z0-9]+", query1))
実行結果
<re.Match object; span=(0, 9), match='abcABC123'>findall:マッチしたものを全て抽出
「findall」では文字列中で正規表現とマッチした全ての部分をリストとして抽出できます。
使い方は「findall(正規表現, 探索文字列)」です。
import re
query2 = "abcde_abcde_abcde"
print(re.findall(r"abc", query2))
実行結果
['abc', 'abc', 'abc']次回はPillowでさまざまなフィルターをかけてみましょう。
あわせて読みたい
【Pillow(PIL)】画像に様々なフィルターをかけてみる[Python]
Pillow(PIL) 前回、Pythonのreモジュールでよく使う関数を紹介しました。 今回はPythonの画像ライブラリであるPillow(PIL)を使って画像に色々なフィルターをかけて…
ではでは今回はこんな感じで。
コメント