機械学習ライブラリScikit-learn
前回までは機械学習ライブラリScikit-learnのボストン住宅価格のデータセットを使い、色々な機械学習モデル、標準化・正規化の効果を検証してきました。
今回からは新しいデータセットを使って、さらに機械学習を学んでいきたいと思います。
ということで使うデータセットは「糖尿病患者のデータセット」です。
どういうものかよく分からないので、とりあえずは読み込んで色々見ていきましょう。
まずはインポートするライブラリは2つ。
sklearnのdatasetsから「load_diabetes」をインポートします。
from sklearn.datasets import load_diabetesそして次にデータセットを変数diabetesに格納していきます。
diabetes = load_diabetes()最後にどんなキーがあるのか表示してみましょう。
print(diabetes.keys())全体としてはこんな感じです。
<セル1>
from sklearn.datasets import load_diabetes
import pandas as pd
diabetes = load_diabetes()
print(diabetes.keys())
実行結果
dict_keys(['data', 'target', 'DESCR', 'feature_names', 'data_filename', 'target_filename'])データセットの概要を確認する
それではこの糖尿病患者のデータセットの概要を表示し、確認してみましょう。
先ほどのキーの中で「DESCR」がデータセットの概要なので、こちらを呼び出してみます。
print(diabetes.DESCR)
実行結果
.. _diabetes_dataset:
Diabetes dataset
----------------
Ten baseline variables, age, sex, body mass index, average blood
pressure, and six blood serum measurements were obtained for each of n =
442 diabetes patients, as well as the response of interest, a
quantitative measure of disease progression one year after baseline.
**Data Set Characteristics:**
:Number of Instances: 442
:Number of Attributes: First 10 columns are numeric predictive values
:Target: Column 11 is a quantitative measure of disease progression one year after baseline
:Attribute Information:
- Age
- Sex
- Body mass index
- Average blood pressure
- S1
- S2
- S3
- S4
- S5
- S6
Note: Each of these 10 feature variables have been mean centered and scaled by the standard deviation times `n_samples` (i.e. the sum of squares of each column totals 1).
Source URL:
https://www4.stat.ncsu.edu/~boos/var.select/diabetes.html
For more information see:
Bradley Efron, Trevor Hastie, Iain Johnstone and Robert Tibshirani (2004) "Least Angle Regression," Annals of Statistics (with discussion), 407-499.
(https://web.stanford.edu/~hastie/Papers/LARS/LeastAngle_2002.pdf)この中で機械学習していくのに重要そうなものだけ解説していきます。
「Number of Instances: 442」はデータが442個含まれることを示しています。
「Number of Attributes: First 10 columns are numeric predictive values」:最初の10個の列が数値予測値、つまりこれらの値を使って機械学習していきます。
「Target: Column 11 is a quantitative measure of disease progression one year after baseline」:11番目の列がターゲット、つまり機械学習で予想する値になり、1年後の糖尿病の進行度を示した値になります。
「Attribute Information:」:特徴量の説明で「Age:年齢」、「Sex:性別」、「Body mass index:BMI値」、「Average blood pressure:平均血圧」、「S1〜6:血中のある物質の量」です。
データを読み込み、表示してみる
それでは実際のデータを読み込んで表示してみましょう。
ここでpandaを使うのでインポートし、データをpandasのデータフレームに格納していきます。
そしてターゲットも忘れずに追加しておきましょう。
import pandas as pd
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
df["target"] = diabetes.target
df
実行結果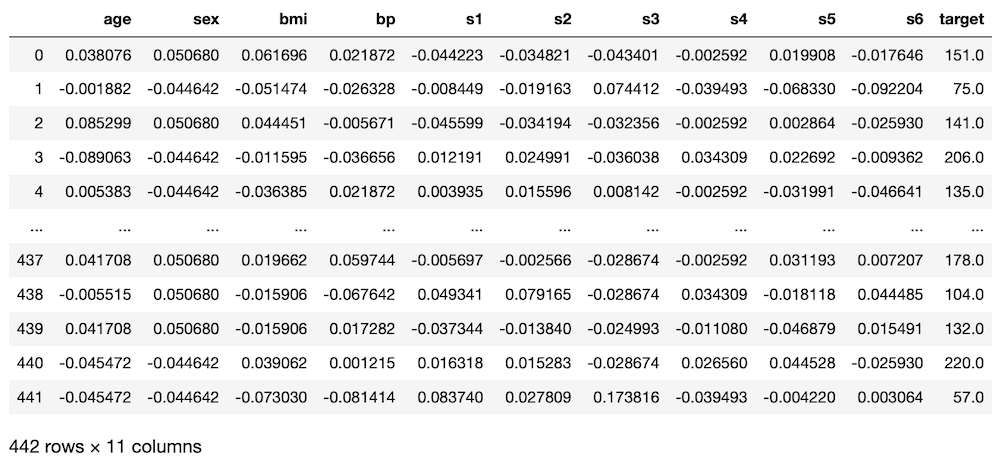
ん?特徴量がどれも小数点となってしまいました。
年齢なんかは小数点にはならないと思いますし、BMI値も10とか20とかあるはずです。
ということで、もう一回概要を見直してみました。
すると「Note: Each of these 10 feature variables have been mean centered and scaled by the standard deviation times n_samples (i.e. the sum of squares of each column totals 1).」とあり、すでに「mean centered」、つまり平均による中心化とやらを行っていると書かれています。
つまりはもうデータの処理はしてあり、このまま機械学習に使えば良さそうです。
ちなみにモデルとしては、特徴量が数値であり、ターゲットも数値であるため、前のボストン住宅価格に使ったモデルを使えば良さそうです。
つまり、LinearRegression、Lasso、ElasticNet、Ridge、SVRのモデルということです。
欠損値があるか確認してみる
次に欠損値があるか確認してみましょう。
先ほどデータを表示したところ、上5行、下5行に関しては欠損値はなさそうですが、どこに潜んでいるか分かりません。
それぞれの列における欠損値の数を表示するのはたった1行のコマンドです。
df.isnull().sum()
実行結果
age 0
sex 0
bmi 0
bp 0
s1 0
s2 0
s3 0
s4 0
s5 0
s6 0
target 0
dtype: int64今回のデータセットでは欠損値はないようです。
相関マップを表示してみる
次にどの値がターゲット(予測する値)に近いか相関マップを表示してみましょう。
そのためにまずはそれぞれの値の相関を計算します。
corr = df.corr()
corr
実行結果
セルの中の数値が縦の値と横の値の相関値になっています。
ただこのままではみづらいので、これを相関マップとして表示してみましょう。
そのためにまずは「seaborn」と「matplotlib」のインポート、グラフをjupyter notebook内で表示するためのマジックコマンドを記載します。
import seaborn as sns
from matplotlib import pyplot as plt
%matplotlib inline次にグラフサイズの設定をします。
plt.figure(figsize=(10,7))最後にseabornのヒートマップで相関図を作成します。
sns.heatmap(corr, annot=True)「annot=True」はそれぞれのセルの中に数値を表示するオプションです。
全体としてはこんな感じになります。
import seaborn as sns
from matplotlib import pyplot as plt
%matplotlib inline
plt.figure(figsize=(10,7))
sns.heatmap(corr, annot=True)
実行結果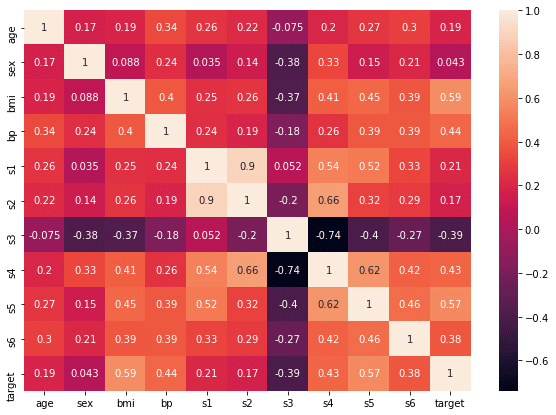
この図の中で白っぽいところが正の相関が高いところ、黒っぽいところが負の相関が高いところです。
この中で確認すべきところはこちらの青枠(縦でも横でもいい)です。
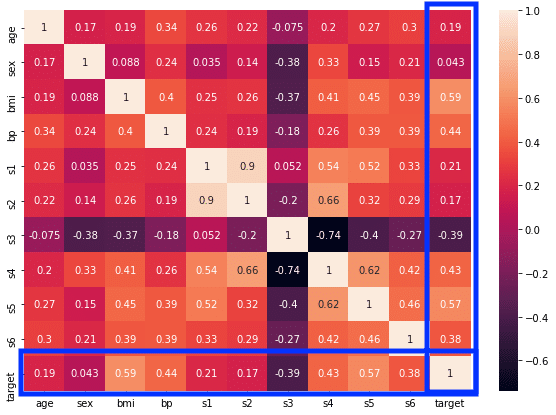
ということでじっと見ていくと、どうやら「bmi」、「s5」、「bp」、「s4」、「s3」、「s6」あたりが相関がありそうです。
次回はこれらの値を使って機械学習してみましょう。
ではでは今回はこんな感じで。
コメント